 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Long-Range Parser for Sequential Data Understanding
Apr 08, 2024The transformer is a powerful data modelling framework responsible for remarkable performance on a wide range of tasks. However, they are limited in terms of scalability as it is suboptimal and inefficient to process long-sequence data. To this purpose we introduce BLRP (Bidirectional Long-Range Parser), a novel and versatile attention mechanism designed to increase performance and efficiency on long-sequence tasks. It leverages short and long range heuristics in the form of a local sliding window approach combined with a global bidirectional latent space synthesis technique. We show the benefits and versatility of our approach on vision and language domains by demonstrating competitive results against state-of-the-art methods on the Long-Range-Arena and CIFAR benchmarks together with ablations demonstrating the computational efficiency.
Watermark Text Pattern Spotting in Document Images
Jan 11, 2024Watermark text spotting in document images can offer access to an often unexplored source of information, providing crucial evidence about a record's scope, audience and sometimes even authenticity. Stemming from the problem of text spotting, detecting and understanding watermarks in documents inherits the same hardships - in the wild, writing can come in various fonts, sizes and forms, making generic recognition a very difficult problem. To address the lack of resources in this field and propel further research, we propose a novel benchmark (K-Watermark) containing 65,447 data samples generated using Wrender, a watermark text patterns rendering procedure. A validity study using humans raters yields an authenticity score of 0.51 against pre-generated watermarked documents. To prove the usefulness of the dataset and rendering technique, we developed an end-to-end solution (Wextract) for detecting the bounding box instances of watermark text, while predicting the depicted text. To deal with this specific task, we introduce a variance minimization loss and a hierarchical self-attention mechanism. To the best of our knowledge, we are the first to propose an evaluation benchmark and a complete solution for retrieving watermarks from documents surpassing baselines by 5 AP points in detection and 4 points in character accuracy.
CONSENT: Context Sensitive Transformer for Bold Words Classification
May 16, 2022

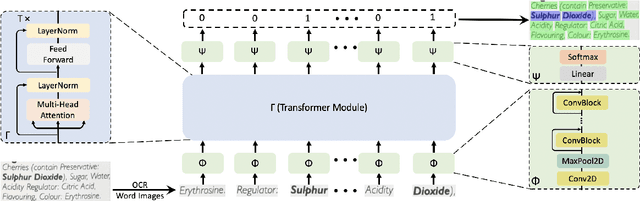

We present CONSENT, a simple yet effective CONtext SENsitive Transformer framework for context-dependent object classification within a fully-trainable end-to-end deep learning pipeline. We exemplify the proposed framework on the task of bold words detection proving state-of-the-art results. Given an image containing text of unknown font-types (e.g. Arial, Calibri, Helvetica), unknown language, taken under various degrees of illumination, angle distortion and scale variation, we extract all the words and learn a context-dependent binary classification (i.e. bold versus non-bold) using an end-to-end transformer-based neural network ensemble. To prove the extensibility of our framework, we demonstrate competitive results against state-of-the-art for the game of rock-paper-scissors by training the model to determine the winner given a sequence with $2$ pictures depicting hand poses.