 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of fractional calculus in learned optimization
Nov 22, 2024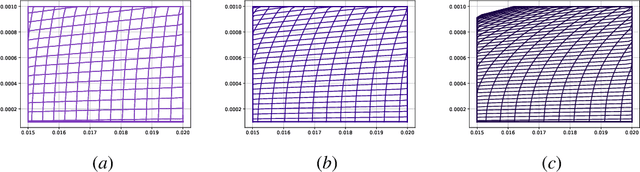
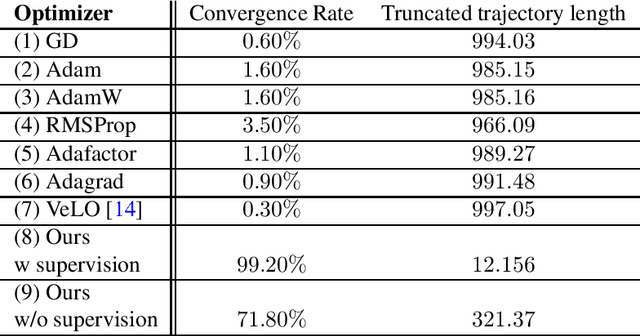
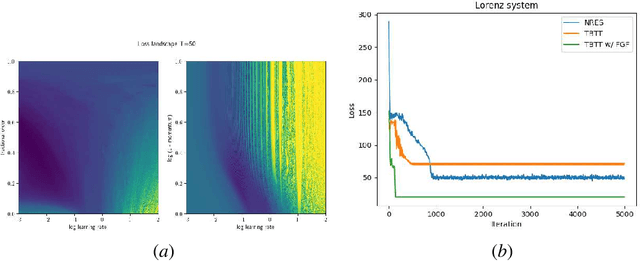
Fractional gradient descent has been studied extensively, with a focus on its ability to extend traditional gradient descent methods by incorporating fractional-order derivatives. This approach allows for more flexibility in navigating complex optimization landscapes and offers advantages in certain types of problems, particularly those involving non-linearities and chaotic dynamics. Yet, the challenge of fine-tuning the fractional order parameters remains unsolved. In this work, we demonstrate that it is possible to train a neural network to predict the order of the gradient effectively.
SPHEAR: Spherical Head Registration for Complete Statistical 3D Modeling
Nov 04, 2023



We present \emph{SPHEAR}, an accurate, differentiable parametric statistical 3D human head model, enabled by a novel 3D registration method based on spherical embeddings. We shift the paradigm away from the classical Non-Rigid Registration methods, which operate under various surface priors, increasing reconstruction fidelity and minimizing required human intervention. Additionally, SPHEAR is a \emph{complete} model that allows not only to sample diverse synthetic head shapes and facial expressions, but also gaze directions, high-resolution color textures, surface normal maps, and hair cuts represented in detail, as strands. SPHEAR can be used for automatic realistic visual data generation, semantic annotation, and general reconstruction tasks. Compared to state-of-the-art approaches, our components are fast and memory efficient, and experiments support the validity of our design choices and the accuracy of registration, reconstruction and generation techniques.
Reconstructing Three-Dimensional Models of Interacting Humans
Aug 04, 2023



Understanding 3d human interactions is fundamental for fine-grained scene analysis and behavioural modeling. However, most of the existing models predict incorrect, lifeless 3d estimates, that miss the subtle human contact aspects--the essence of the event--and are of little use for detailed behavioral understanding. This paper addresses such issues with several contributions: (1) we introduce models for interaction signature estimation (ISP) encompassing contact detection, segmentation, and 3d contact signature prediction; (2) we show how such components can be leveraged to ensure contact consistency during 3d reconstruction; (3) we construct several large datasets for learning and evaluating 3d contact prediction and reconstruction methods; specifically, we introduce CHI3D, a lab-based accurate 3d motion capture dataset with 631 sequences containing $2,525$ contact events, $728,664$ ground truth 3d poses, as well as FlickrCI3D, a dataset of $11,216$ images, with $14,081$ processed pairs of people, and $81,233$ facet-level surface correspondences. Finally, (4) we propose methodology for recovering the ground-truth pose and shape of interacting people in a controlled setup and (5) annotate all 3d interaction motions in CHI3D with textual descriptions. Motion data in multiple formats (GHUM and SMPLX parameters, Human3.6m 3d joints) is made available for research purposes at \url{https://ci3d.imar.ro}, together with an evaluation server and a public benchmark.
HUM3DIL: Semi-supervised Multi-modal 3D Human Pose Estimation for Autonomous Driving
Dec 15, 2022Autonomous driving is an exciting new industry, posing important research questions. Within the perception module, 3D human pose estimation is an emerging technology, which can enable the autonomous vehicle to perceive and understand the subtle and complex behaviors of pedestrians. While hardware systems and sensors have dramatically improved over the decades -- with cars potentially boasting complex LiDAR and vision systems and with a growing expansion of the available body of dedicated datasets for this newly available information -- not much work has been done to harness these novel signals for the core problem of 3D human pose estimation. Our method, which we coin HUM3DIL (HUMan 3D from Images and LiDAR), efficiently makes use of these complementary signals, in a semi-supervised fashion and outperforms existing methods with a large margin. It is a fast and compact model for onboard deployment. Specifically, we embed LiDAR points into pixel-aligned multi-modal features, which we pass through a sequence of Transformer refinement stages. Quantitative experiments on the Waymo Open Dataset support these claims, where we achieve state-of-the-art results on the task of 3D pose estimation.
PhoMoH: Implicit Photorealistic 3D Models of Human Heads
Dec 14, 2022
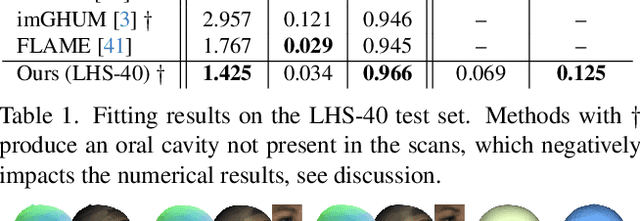


We present PhoMoH, a neural network methodology to construct generative models of photorealistic 3D geometry and appearance of human heads including hair, beards, clothing and accessories. In contrast to prior work, PhoMoH models the human head using neural fields, thus supporting complex topology. Instead of learning a head model from scratch, we propose to augment an existing expressive head model with new features. Concretely, we learn a highly detailed geometry network layered on top of a mid-resolution head model together with a detailed, local geometry-aware, and disentangled color field. Our proposed architecture allows us to learn photorealistic human head models from relatively little data. The learned generative geometry and appearance networks can be sampled individually and allow the creation of diverse and realistic human heads. Extensive experiments validate our method qualitatively and across different metrics.
Structured 3D Features for Reconstructing Relightable and Animatable Avatars
Dec 13, 2022



We introduce Structured 3D Features, a model based on a novel implicit 3D representation that pools pixel-aligned image features onto dense 3D points sampled from a parametric, statistical human mesh surface. The 3D points have associated semantics and can move freely in 3D space. This allows for optimal coverage of the person of interest, beyond just the body shape, which in turn, additionally helps modeling accessories, hair, and loose clothing. Owing to this, we present a complete 3D transformer-based attention framework which, given a single image of a person in an unconstrained pose, generates an animatable 3D reconstruction with albedo and illumination decomposition, as a result of a single end-to-end model, trained semi-supervised, and with no additional postprocessing. We show that our S3F model surpasses the previous state-of-the-art on various tasks, including monocular 3D reconstruction, as well as albedo and shading estimation. Moreover, we show that the proposed methodology allows novel view synthesis, relighting, and re-posing the reconstruction, and can naturally be extended to handle multiple input images (e.g. different views of a person, or the same view, in different poses, in video). Finally, we demonstrate the editing capabilities of our model for 3D virtual try-on applications.
BlazePose GHUM Holistic: Real-time 3D Human Landmarks and Pose Estimation
Jun 23, 2022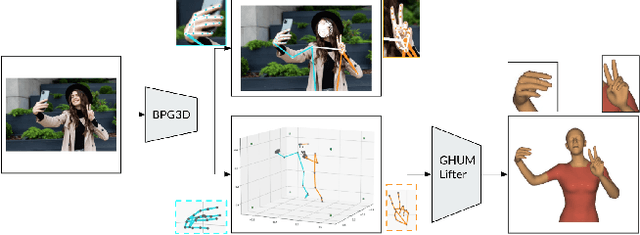
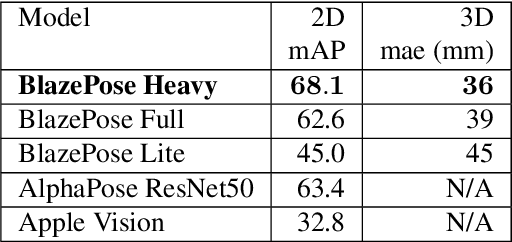
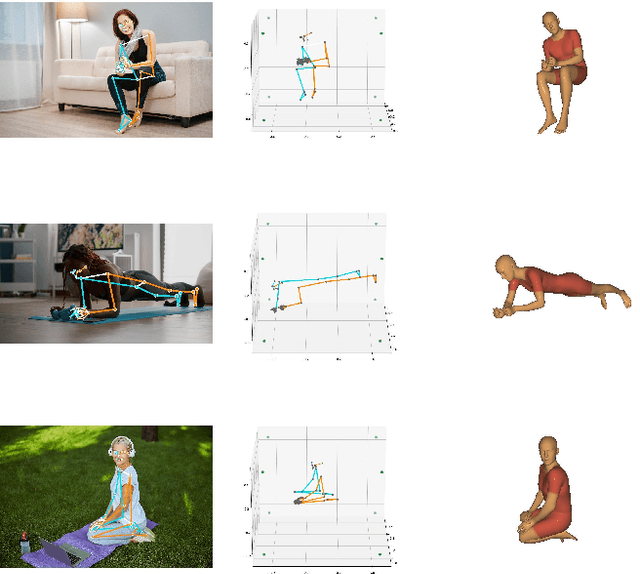
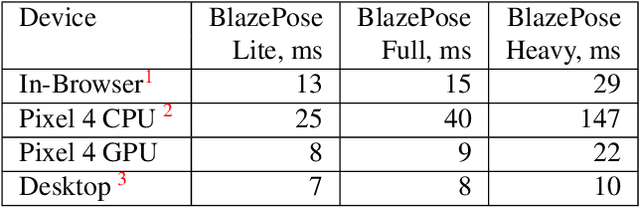
We present BlazePose GHUM Holistic, a lightweight neural network pipeline for 3D human body landmarks and pose estimation, specifically tailored to real-time on-device inference. BlazePose GHUM Holistic enables motion capture from a single RGB image including avatar control, fitness tracking and AR/VR effects. Our main contributions include i) a novel method for 3D ground truth data acquisition, ii) updated 3D body tracking with additional hand landmarks and iii) full body pose estimation from a monocular image.
Photorealistic Monocular 3D Reconstruction of Humans Wearing Clothing
Apr 19, 2022
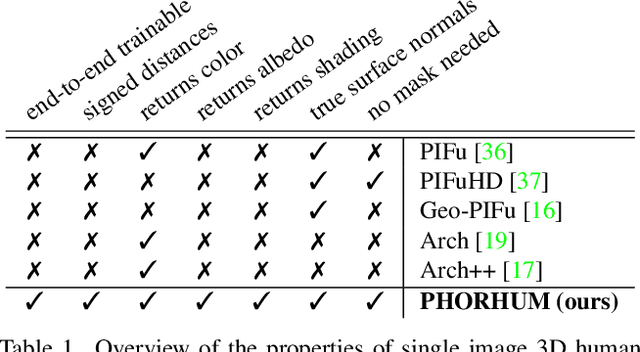
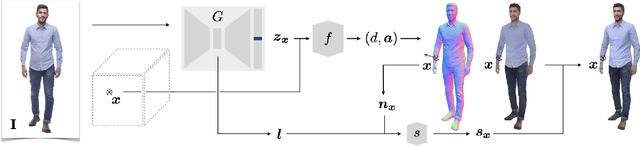
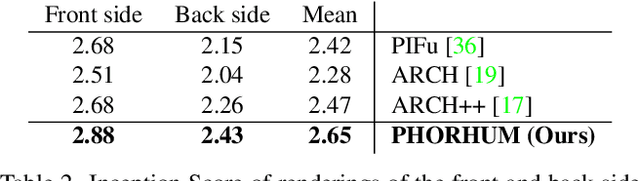
We present PHORHUM, a novel, end-to-end trainable, deep neural network methodology for photorealistic 3D human reconstruction given just a monocular RGB image. Our pixel-aligned method estimates detailed 3D geometry and, for the first time, the unshaded surface color together with the scene illumination. Observing that 3D supervision alone is not sufficient for high fidelity color reconstruction, we introduce patch-based rendering losses that enable reliable color reconstruction on visible parts of the human, and detailed and plausible color estimation for the non-visible parts. Moreover, our method specifically addresses methodological and practical limitations of prior work in terms of representing geometry, albedo, and illumination effects, in an end-to-end model where factors can be effectively disentangled. In extensive experiments, we demonstrate the versatility and robustness of our approach. Our state-of-the-art results validate the method qualitatively and for different metrics, for both geometric and color reconstruction.
HSPACE: Synthetic Parametric Humans Animated in Complex Environments
Jan 06, 2022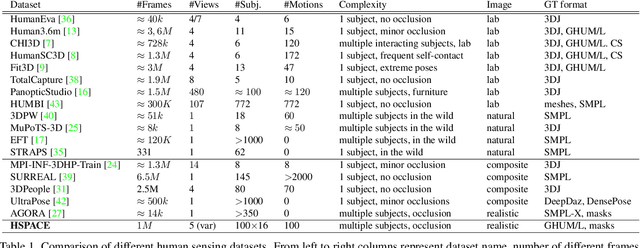
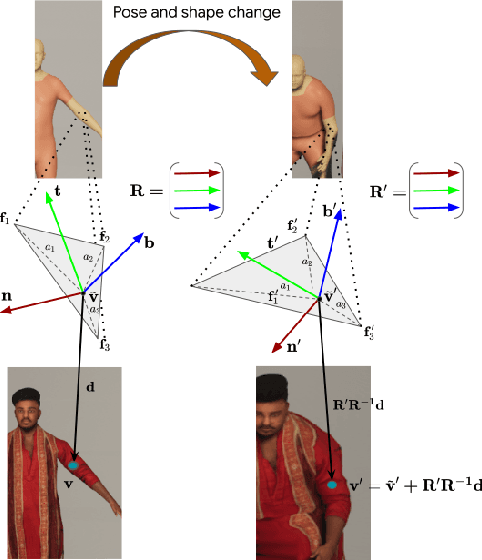
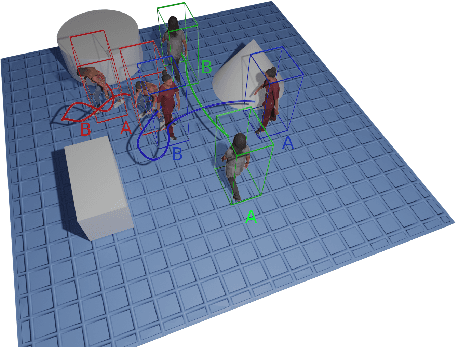
Advances in the state of the art for 3d human sensing are currently limited by the lack of visual datasets with 3d ground truth, including multiple people, in motion, operating in real-world environments, with complex illumination or occlusion, and potentially observed by a moving camera. Sophisticated scene understanding would require estimating human pose and shape as well as gestures, towards representations that ultimately combine useful metric and behavioral signals with free-viewpoint photo-realistic visualisation capabilities. To sustain progress, we build a large-scale photo-realistic dataset, Human-SPACE (HSPACE), of animated humans placed in complex synthetic indoor and outdoor environments. We combine a hundred diverse individuals of varying ages, gender, proportions, and ethnicity, with hundreds of motions and scenes, as well as parametric variations in body shape (for a total of 1,600 different humans), in order to generate an initial dataset of over 1 million frames. Human animations are obtained by fitting an expressive human body model, GHUM, to single scans of people, followed by novel re-targeting and positioning procedures that support the realistic animation of dressed humans, statistical variation of body proportions, and jointly consistent scene placement of multiple moving people. Assets are generated automatically, at scale, and are compatible with existing real time rendering and game engines. The dataset with evaluation server will be made available for research. Our large-scale analysis of the impact of synthetic data, in connection with real data and weak supervision, underlines the considerable potential for continuing quality improvements and limiting the sim-to-real gap, in this practical setting, in connection with increased model capacity.
THUNDR: Transformer-based 3D HUmaN Reconstruction with Markers
Jun 17, 2021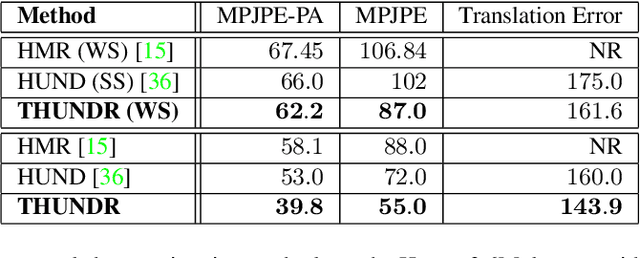
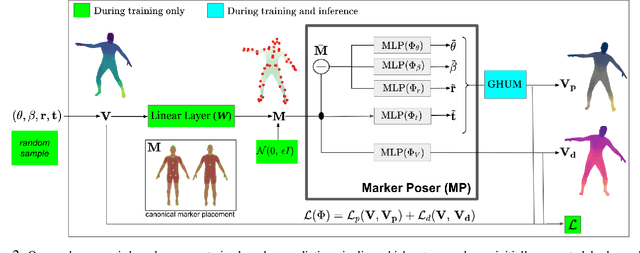
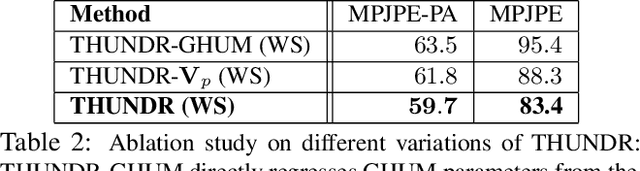
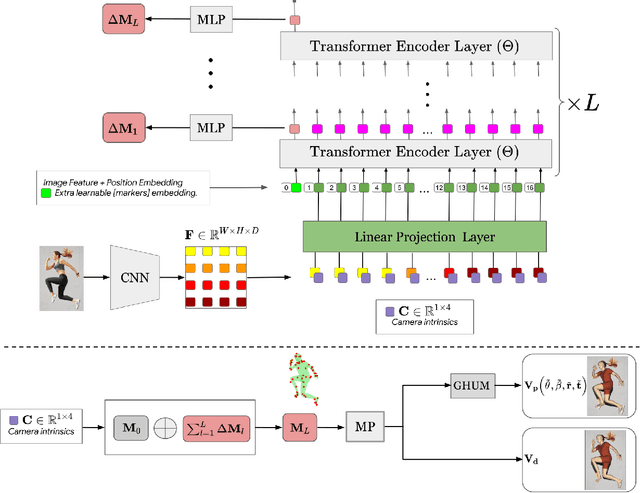
We present THUNDR, a transformer-based deep neural network methodology to reconstruct the 3d pose and shape of people, given monocular RGB images. Key to our methodology is an intermediate 3d marker representation, where we aim to combine the predictive power of model-free-output architectures and the regularizing, anthropometrically-preserving properties of a statistical human surface model like GHUM -- a recently introduced, expressive full body statistical 3d human model, trained end-to-end. Our novel transformer-based prediction pipeline can focus on image regions relevant to the task, supports self-supervised regimes, and ensures that solutions are consistent with human anthropometry. We show state-of-the-art results on Human3.6M and 3DPW, for both the fully-supervised and the self-supervised models, for the task of inferring 3d human shape, joint positions, and global translation. Moreover, we observe very solid 3d reconstruction performance for difficult human poses collected in the wild.