 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneCrafter: Controllable Multi-View Driving Scene Editing
Jun 24, 2025Simulation is crucial for developing and evaluating autonomous vehicle (AV) systems. Recent literature builds on a new generation of generative models to synthesize highly realistic images for full-stack simulation. However, purely synthetically generated scenes are not grounded in reality and have difficulty in inspiring confidence in the relevance of its outcomes. Editing models, on the other hand, leverage source scenes from real driving logs, and enable the simulation of different traffic layouts, behaviors, and operating conditions such as weather and time of day. While image editing is an established topic in computer vision, it presents fresh sets of challenges in driving simulation: (1) the need for cross-camera 3D consistency, (2) learning ``empty street" priors from driving data with foreground occlusions, and (3) obtaining paired image tuples of varied editing conditions while preserving consistent layout and geometry. To address these challenges, we propose SceneCrafter, a versatile editor for realistic 3D-consistent manipulation of driving scenes captured from multiple cameras. We build on recent advancements in multi-view diffusion models, using a fully controllable framework that scales seamlessly to multi-modality conditions like weather, time of day, agent boxes and high-definition maps. To generate paired data for supervising the editing model, we propose a novel framework on top of Prompt-to-Prompt to generate geometrically consistent synthetic paired data with global edits. We also introduce an alpha-blending framework to synthesize data with local edits, leveraging a model trained on empty street priors through novel masked training and multi-view repaint paradigm. SceneCrafter demonstrates powerful editing capabilities and achieves state-of-the-art realism, controllability, 3D consistency, and scene editing quality compared to existing baselines.
Scaling Laws of Motion Forecasting and Planning -- A Technical Report
Jun 09, 2025We study the empirical scaling laws of a family of encoder-decoder autoregressive transformer models on the task of joint motion forecasting and planning in the autonomous driving domain. Using a 500 thousand hours driving dataset, we demonstrate that, similar to language modeling, model performance improves as a power-law function of the total compute budget, and we observe a strong correlation between model training loss and model evaluation metrics. Most interestingly, closed-loop metrics also improve with scaling, which has important implications for the suitability of open-loop metrics for model development and hill climbing. We also study the optimal scaling of the number of transformer parameters and the training data size for a training compute-optimal model. We find that as the training compute budget grows, optimal scaling requires increasing the model size 1.5x as fast as the dataset size. We also study inference-time compute scaling, where we observe that sampling and clustering the output of smaller models makes them competitive with larger models, up to a crossover point beyond which a larger models becomes more inference-compute efficient. Overall, our experimental results demonstrate that optimizing the training and inference-time scaling properties of motion forecasting and planning models is a key lever for improving their performance to address a wide variety of driving scenarios. Finally, we briefly study the utility of training on general logged driving data of other agents to improve the performance of the ego-agent, an important research area to address the scarcity of robotics data for large capacity models training.
S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Modelwith Spatio-Temporal Visual Representation
May 30, 2025

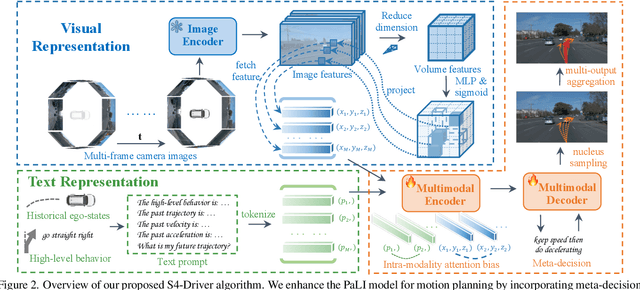

The latest advancements in multi-modal large language models (MLLMs) have spurred a strong renewed interest in end-to-end motion planning approaches for autonomous driving. Many end-to-end approaches rely on human annotations to learn intermediate perception and prediction tasks, while purely self-supervised approaches--which directly learn from sensor inputs to generate planning trajectories without human annotations often underperform the state of the art. We observe a key gap in the input representation space: end-to-end approaches built on MLLMs are often pretrained with reasoning tasks in 2D image space rather than the native 3D space in which autonomous vehicles plan. To this end, we propose S4-Driver, a scalable self-supervised motion planning algorithm with spatio-temporal visual representation, based on the popular PaLI multimodal large language model. S4-Driver uses a novel sparse volume strategy to seamlessly transform the strong visual representation of MLLMs from perspective view to 3D space without the need to finetune the vision encoder. This representation aggregates multi-view and multi-frame visual inputs and enables better prediction of planning trajectories in 3D space. To validate our method, we run experiments on both nuScenes and Waymo Open Motion Dataset (with in-house camera data). Results show that S4-Driver performs favorably against existing supervised multi-task approaches while requiring no human annotations. It also demonstrates great scalability when pretrained on large volumes of unannotated driving logs.
EMMA: End-to-End Multimodal Model for Autonomous Driving
Oct 30, 2024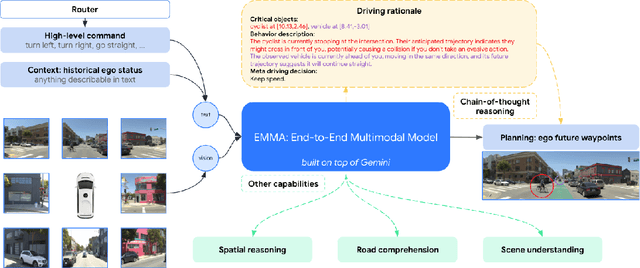
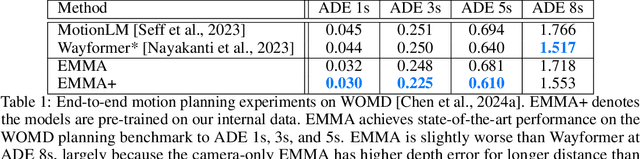
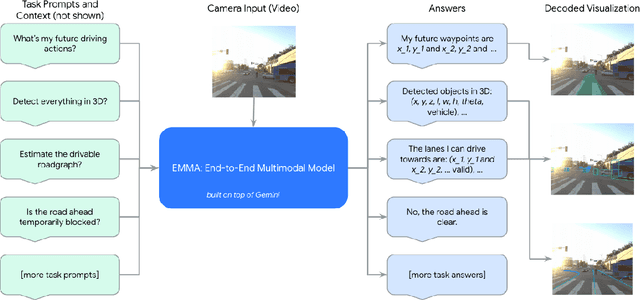
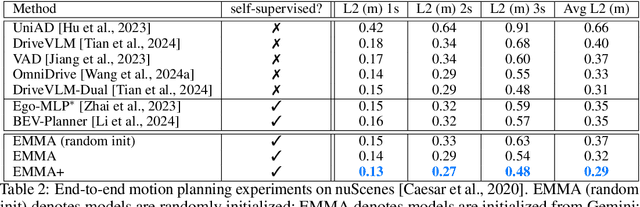
We introduce EMMA, an End-to-end Multimodal Model for Autonomous driving. Built on a multi-modal large language model foundation, EMMA directly maps raw camera sensor data into various driving-specific outputs, including planner trajectories, perception objects, and road graph elements. EMMA maximizes the utility of world knowledge from the pre-trained large language models, by representing all non-sensor inputs (e.g. navigation instructions and ego vehicle status) and outputs (e.g. trajectories and 3D locations) as natural language text. This approach allows EMMA to jointly process various driving tasks in a unified language space, and generate the outputs for each task using task-specific prompts. Empirically, we demonstrate EMMA's effectiveness by achieving state-of-the-art performance in motion planning on nuScenes as well as competitive results on the Waymo Open Motion Dataset (WOMD). EMMA also yields competitive results for camera-primary 3D object detection on the Waymo Open Dataset (WOD). We show that co-training EMMA with planner trajectories, object detection, and road graph tasks yields improvements across all three domains, highlighting EMMA's potential as a generalist model for autonomous driving applications. However, EMMA also exhibits certain limitations: it can process only a small amount of image frames, does not incorporate accurate 3D sensing modalities like LiDAR or radar and is computationally expensive. We hope that our results will inspire further research to mitigate these issues and to further evolve the state of the art in autonomous driving model architectures.
PVTransformer: Point-to-Voxel Transformer for Scalable 3D Object Detection
May 05, 2024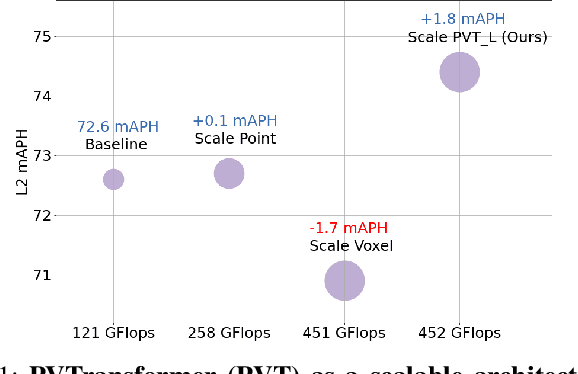
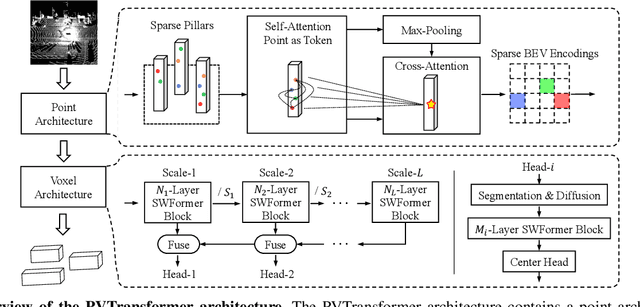
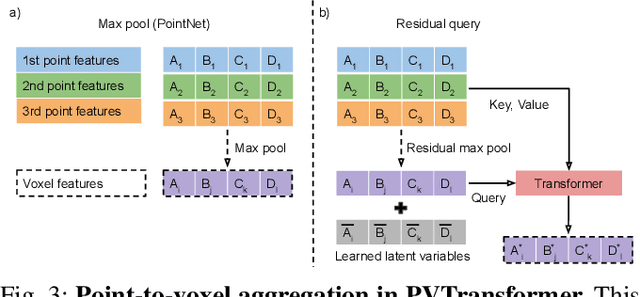
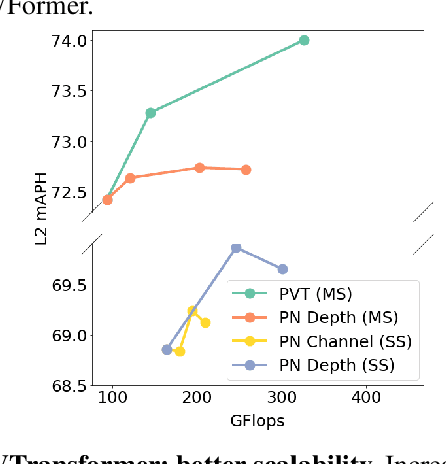
3D object detectors for point clouds often rely on a pooling-based PointNet to encode sparse points into grid-like voxels or pillars. In this paper, we identify that the common PointNet design introduces an information bottleneck that limits 3D object detection accuracy and scalability. To address this limitation, we propose PVTransformer: a transformer-based point-to-voxel architecture for 3D detection. Our key idea is to replace the PointNet pooling operation with an attention module, leading to a better point-to-voxel aggregation function. Our design respects the permutation invariance of sparse 3D points while being more expressive than the pooling-based PointNet. Experimental results show our PVTransformer achieves much better performance compared to the latest 3D object detectors. On the widely used Waymo Open Dataset, our PVTransformer achieves state-of-the-art 76.5 mAPH L2, outperforming the prior art of SWFormer by +1.7 mAPH L2.
MoST: Multi-modality Scene Tokenization for Motion Prediction
Apr 30, 2024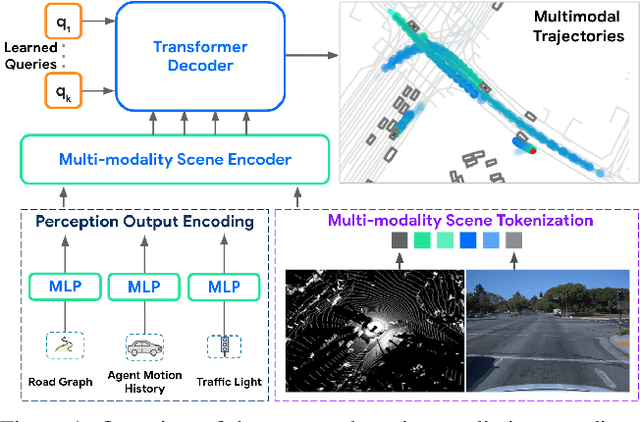

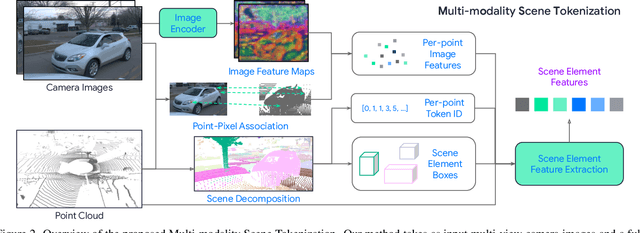
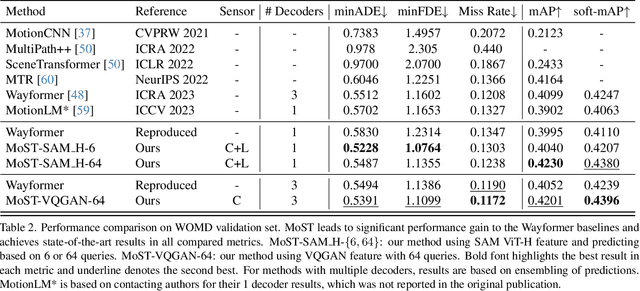
Many existing motion prediction approaches rely on symbolic perception outputs to generate agent trajectories, such as bounding boxes, road graph information and traffic lights. This symbolic representation is a high-level abstraction of the real world, which may render the motion prediction model vulnerable to perception errors (e.g., failures in detecting open-vocabulary obstacles) while missing salient information from the scene context (e.g., poor road conditions). An alternative paradigm is end-to-end learning from raw sensors. However, this approach suffers from the lack of interpretability and requires significantly more training resources. In this work, we propose tokenizing the visual world into a compact set of scene elements and then leveraging pre-trained image foundation models and LiDAR neural networks to encode all the scene elements in an open-vocabulary manner. The image foundation model enables our scene tokens to encode the general knowledge of the open world while the LiDAR neural network encodes geometry information. Our proposed representation can efficiently encode the multi-frame multi-modality observations with a few hundred tokens and is compatible with most transformer-based architectures. To evaluate our method, we have augmented Waymo Open Motion Dataset with camera embeddings. Experiments over Waymo Open Motion Dataset show that our approach leads to significant performance improvements over the state-of-the-art.
Waymax: An Accelerated, Data-Driven Simulator for Large-Scale Autonomous Driving Research
Oct 12, 2023
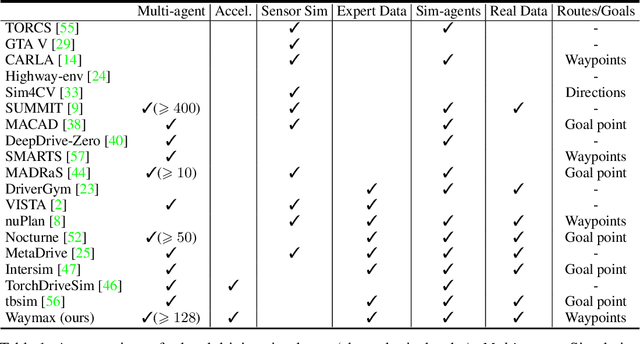
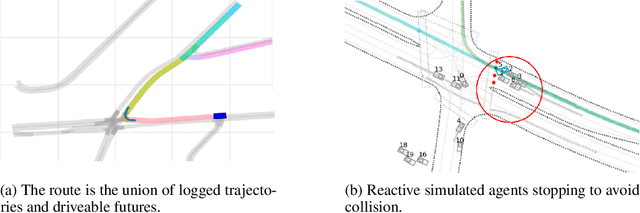
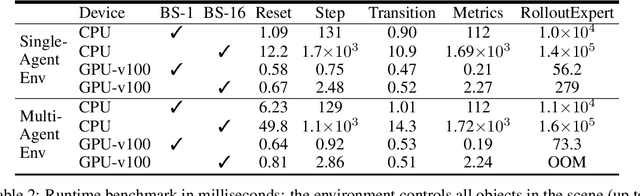
Simulation is an essential tool to develop and benchmark autonomous vehicle planning software in a safe and cost-effective manner. However, realistic simulation requires accurate modeling of nuanced and complex multi-agent interactive behaviors. To address these challenges, we introduce Waymax, a new data-driven simulator for autonomous driving in multi-agent scenes, designed for large-scale simulation and testing. Waymax uses publicly-released, real-world driving data (e.g., the Waymo Open Motion Dataset) to initialize or play back a diverse set of multi-agent simulated scenarios. It runs entirely on hardware accelerators such as TPUs/GPUs and supports in-graph simulation for training, making it suitable for modern large-scale, distributed machine learning workflows. To support online training and evaluation, Waymax includes several learned and hard-coded behavior models that allow for realistic interaction within simulation. To supplement Waymax, we benchmark a suite of popular imitation and reinforcement learning algorithms with ablation studies on different design decisions, where we highlight the effectiveness of routes as guidance for planning agents and the ability of RL to overfit against simulated agents.
LEF: Late-to-Early Temporal Fusion for LiDAR 3D Object Detection
Sep 28, 2023



We propose a late-to-early recurrent feature fusion scheme for 3D object detection using temporal LiDAR point clouds. Our main motivation is fusing object-aware latent embeddings into the early stages of a 3D object detector. This feature fusion strategy enables the model to better capture the shapes and poses for challenging objects, compared with learning from raw points directly. Our method conducts late-to-early feature fusion in a recurrent manner. This is achieved by enforcing window-based attention blocks upon temporally calibrated and aligned sparse pillar tokens. Leveraging bird's eye view foreground pillar segmentation, we reduce the number of sparse history features that our model needs to fuse into its current frame by 10$\times$. We also propose a stochastic-length FrameDrop training technique, which generalizes the model to variable frame lengths at inference for improved performance without retraining. We evaluate our method on the widely adopted Waymo Open Dataset and demonstrate improvement on 3D object detection against the baseline model, especially for the challenging category of large objects.
Unsupervised 3D Perception with 2D Vision-Language Distillation for Autonomous Driving
Sep 25, 2023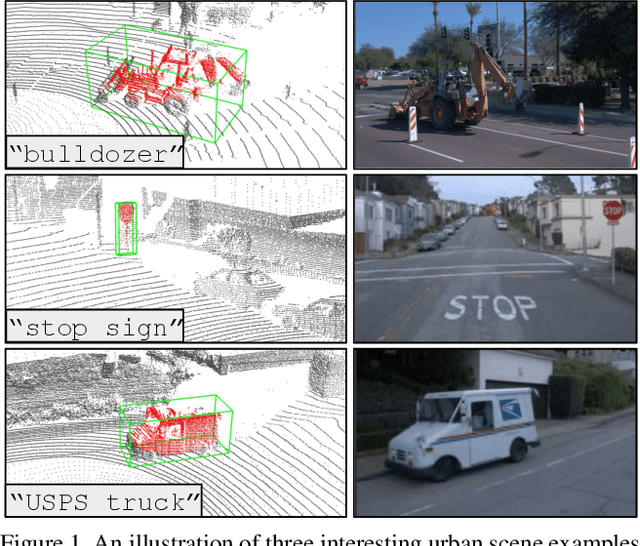
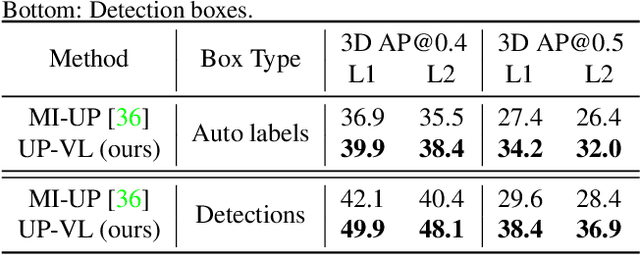
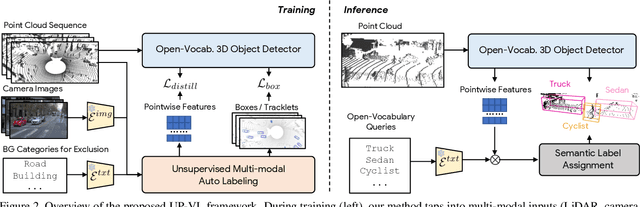

Closed-set 3D perception models trained on only a pre-defined set of object categories can be inadequate for safety critical applications such as autonomous driving where new object types can be encountered after deployment. In this paper, we present a multi-modal auto labeling pipeline capable of generating amodal 3D bounding boxes and tracklets for training models on open-set categories without 3D human labels. Our pipeline exploits motion cues inherent in point cloud sequences in combination with the freely available 2D image-text pairs to identify and track all traffic participants. Compared to the recent studies in this domain, which can only provide class-agnostic auto labels limited to moving objects, our method can handle both static and moving objects in the unsupervised manner and is able to output open-vocabulary semantic labels thanks to the proposed vision-language knowledge distillation. Experiments on the Waymo Open Dataset show that our approach outperforms the prior work by significant margins on various unsupervised 3D perception tasks.
3D Human Keypoints Estimation From Point Clouds in the Wild Without Human Labels
Jun 07, 2023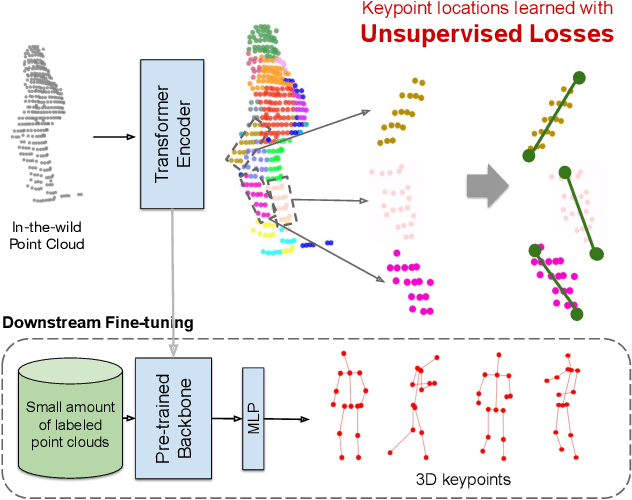
Training a 3D human keypoint detector from point clouds in a supervised manner requires large volumes of high quality labels. While it is relatively easy to capture large amounts of human point clouds, annotating 3D keypoints is expensive, subjective, error prone and especially difficult for long-tail cases (pedestrians with rare poses, scooterists, etc.). In this work, we propose GC-KPL - Geometry Consistency inspired Key Point Leaning, an approach for learning 3D human joint locations from point clouds without human labels. We achieve this by our novel unsupervised loss formulations that account for the structure and movement of the human body. We show that by training on a large training set from Waymo Open Dataset without any human annotated keypoints, we are able to achieve reasonable performance as compared to the fully supervised approach. Further, the backbone benefits from the unsupervised training and is useful in downstream fewshot learning of keypoints, where fine-tuning on only 10 percent of the labeled training data gives comparable performance to fine-tuning on the entire set. We demonstrated that GC-KPL outperforms by a large margin over SoTA when trained on entire dataset and efficiently leverages large volumes of unlabeled data.