 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVTransformer: Point-to-Voxel Transformer for Scalable 3D Object Detection
May 05, 2024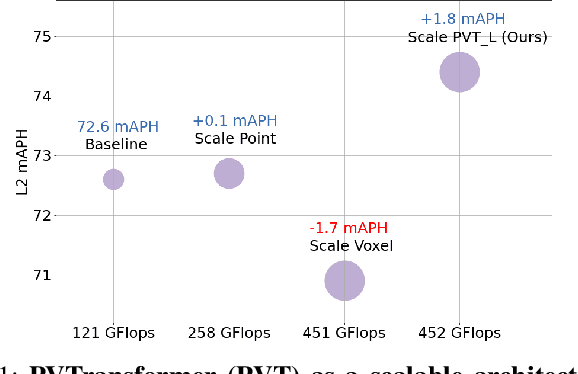
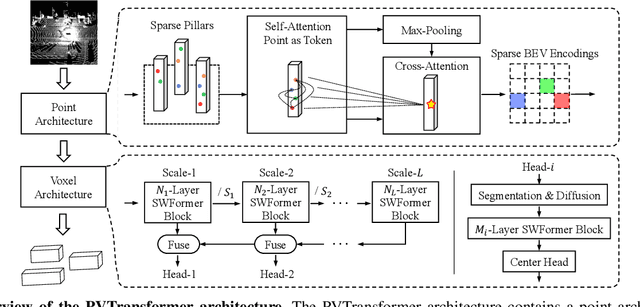
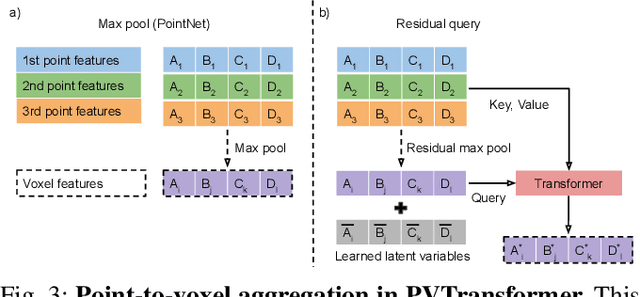
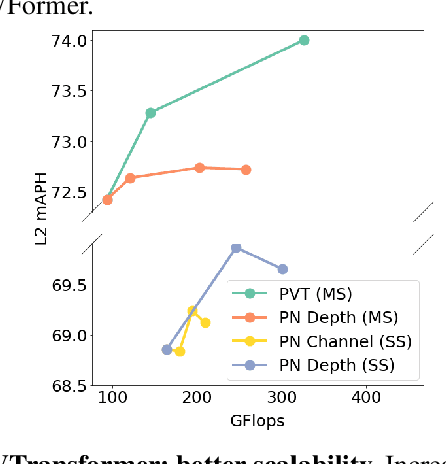
3D object detectors for point clouds often rely on a pooling-based PointNet to encode sparse points into grid-like voxels or pillars. In this paper, we identify that the common PointNet design introduces an information bottleneck that limits 3D object detection accuracy and scalability. To address this limitation, we propose PVTransformer: a transformer-based point-to-voxel architecture for 3D detection. Our key idea is to replace the PointNet pooling operation with an attention module, leading to a better point-to-voxel aggregation function. Our design respects the permutation invariance of sparse 3D points while being more expressive than the pooling-based PointNet. Experimental results show our PVTransformer achieves much better performance compared to the latest 3D object detectors. On the widely used Waymo Open Dataset, our PVTransformer achieves state-of-the-art 76.5 mAPH L2, outperforming the prior art of SWFormer by +1.7 mAPH L2.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
LEF: Late-to-Early Temporal Fusion for LiDAR 3D Object Detection
Sep 28, 2023



We propose a late-to-early recurrent feature fusion scheme for 3D object detection using temporal LiDAR point clouds. Our main motivation is fusing object-aware latent embeddings into the early stages of a 3D object detector. This feature fusion strategy enables the model to better capture the shapes and poses for challenging objects, compared with learning from raw points directly. Our method conducts late-to-early feature fusion in a recurrent manner. This is achieved by enforcing window-based attention blocks upon temporally calibrated and aligned sparse pillar tokens. Leveraging bird's eye view foreground pillar segmentation, we reduce the number of sparse history features that our model needs to fuse into its current frame by 10$\times$. We also propose a stochastic-length FrameDrop training technique, which generalizes the model to variable frame lengths at inference for improved performance without retraining. We evaluate our method on the widely adopted Waymo Open Dataset and demonstrate improvement on 3D object detection against the baseline model, especially for the challenging category of large objects.
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.
Koopman neural operator as a mesh-free solver of non-linear partial differential equations
Jan 24, 2023



The lacking of analytic solutions of diverse partial differential equations (PDEs) gives birth to series of computational techniques for numerical solutions. In machine learning, numerous latest advances of solver designs are accomplished in developing neural operators, a kind of mesh-free approximators of the infinite-dimensional operators that map between different parameterization spaces of equation solutions. Although neural operators exhibit generalization capacities for learning an entire PDE family simultaneously, they become less accurate and explainable while learning long-term behaviours of non-linear PDE families. In this paper, we propose Koopman neural operator (KNO), a new neural operator, to overcome these challenges. With the same objective of learning an infinite-dimensional mapping between Banach spaces that serves as the solution operator of target PDE family, our approach differs from existing models by formulating a non-linear dynamic system of equation solution. By approximating the Koopman operator, an infinite-dimensional linear operator governing all possible observations of the dynamic system, to act on the flow mapping of dynamic system, we can equivalently learn the solution of an entire non-linear PDE family by solving simple linear prediction problems. In zero-shot prediction and long-term prediction experiments on representative PDEs (e.g., the Navier-Stokes equation), KNO exhibits notable advantages in breaking the tradeoff between accuracy and efficiency (e.g., model size) while previous state-of-the-art models are limited. These results suggest that more efficient PDE solvers can be developed by the joint efforts from physics and machine learning.
KoopmanLab: machine learning for solving complex physics equations
Jan 17, 2023Numerous physics theories are rooted in partial differential equations (PDEs). However, the increasingly intricate physics equations, especially those that lack analytic solutions or closed forms, have impeded the further development of physics. Computationally solving PDEs by classic numerical approaches suffers from the trade-off between accuracy and efficiency and is not applicable to the empirical data generated by unknown latent PDEs. To overcome this challenge, we present KoopmanLab, an efficient module of the Koopman neural operator family, for learning PDEs without analytic solutions or closed forms. Our module consists of multiple variants of the Koopman neural operator (KNO), a kind of mesh-independent neural-network-based PDE solvers developed following dynamic system theory. The compact variants of KNO can accurately solve PDEs with small model sizes while the large variants of KNO are more competitive in predicting highly complicated dynamic systems govern by unknown, high-dimensional, and non-linear PDEs. All variants are validated by mesh-independent and long-term prediction experiments implemented on representative PDEs (e.g., the Navier-Stokes equation and the Bateman-Burgers equation in fluid mechanics) and ERA5 (i.e., one of the largest high-resolution global-scale climate data sets in earth physics). These demonstrations suggest the potential of KoopmanLab to be a fundamental tool in diverse physics studies related to equations or dynamic systems.
Statistical Physics of Deep Neural Networks: Initialization toward Optimal Channels
Dec 04, 2022In deep learning, neural networks serve as noisy channels between input data and its representation. This perspective naturally relates deep learning with the pursuit of constructing channels with optimal performance in information transmission and representation. While considerable efforts are concentrated on realizing optimal channel properties during network optimization, we study a frequently overlooked possibility that neural networks can be initialized toward optimal channels. Our theory, consistent with experimental validation, identifies primary mechanics underlying this unknown possibility and suggests intrinsic connections between statistical physics and deep learning. Unlike the conventional theories that characterize neural networks applying the classic mean-filed approximation, we offer analytic proof that this extensively applied simplification scheme is not valid in studying neural networks as information channels. To fill this gap, we develop a corrected mean-field framework applicable for characterizing the limiting behaviors of information propagation in neural networks without strong assumptions on inputs. Based on it, we propose an analytic theory to prove that mutual information maximization is realized between inputs and propagated signals when neural networks are initialized at dynamic isometry, a case where information transmits via norm-preserving mappings. These theoretical predictions are validated by experiments on real neural networks, suggesting the robustness of our theory against finite-size effects. Finally, we analyze our findings with information bottleneck theory to confirm the precise relations among dynamic isometry, mutual information maximization, and optimal channel properties in deep learning.
LidarAugment: Searching for Scalable 3D LiDAR Data Augmentations
Oct 24, 2022



Data augmentations are important in training high-performance 3D object detectors for point clouds. Despite recent efforts on designing new data augmentations, perhaps surprisingly, most state-of-the-art 3D detectors only use a few simple data augmentations. In particular, different from 2D image data augmentations, 3D data augmentations need to account for different representations of input data and require being customized for different models, which introduces significant overhead. In this paper, we resort to a search-based approach, and propose LidarAugment, a practical and effective data augmentation strategy for 3D object detection. Unlike previous approaches where all augmentation policies are tuned in an exponentially large search space, we propose to factorize and align the search space of each data augmentation, which cuts down the 20+ hyperparameters to 2, and significantly reduces the search complexity. We show LidarAugment can be customized for different model architectures with different input representations by a simple 2D grid search, and consistently improve both convolution-based UPillars/StarNet/RSN and transformer-based SWFormer. Furthermore, LidarAugment mitigates overfitting and allows us to scale up 3D detectors to much larger capacity. In particular, by combining with latest 3D detectors, our LidarAugment achieves a new state-of-the-art 74.8 mAPH L2 on Waymo Open Dataset.
SWFormer: Sparse Window Transformer for 3D Object Detection in Point Clouds
Oct 13, 2022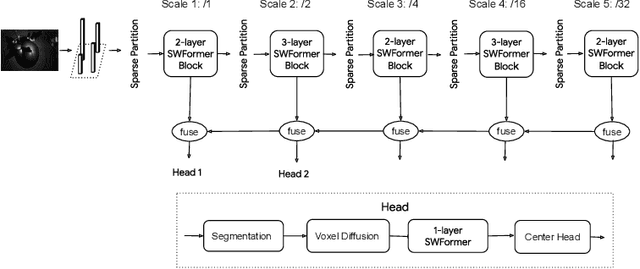
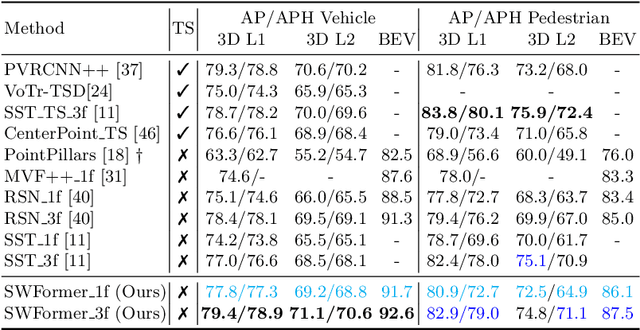
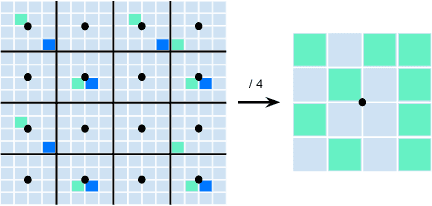

3D object detection in point clouds is a core component for modern robotics and autonomous driving systems. A key challenge in 3D object detection comes from the inherent sparse nature of point occupancy within the 3D scene. In this paper, we propose Sparse Window Transformer (SWFormer ), a scalable and accurate model for 3D object detection, which can take full advantage of the sparsity of point clouds. Built upon the idea of window-based Transformers, SWFormer converts 3D points into sparse voxels and windows, and then processes these variable-length sparse windows efficiently using a bucketing scheme. In addition to self-attention within each spatial window, our SWFormer also captures cross-window correlation with multi-scale feature fusion and window shifting operations. To further address the unique challenge of detecting 3D objects accurately from sparse features, we propose a new voxel diffusion technique. Experimental results on the Waymo Open Dataset show our SWFormer achieves state-of-the-art 73.36 L2 mAPH on vehicle and pedestrian for 3D object detection on the official test set, outperforming all previous single-stage and two-stage models, while being much more efficient.
LidarNAS: Unifying and Searching Neural Architectures for 3D Point Clouds
Oct 10, 2022
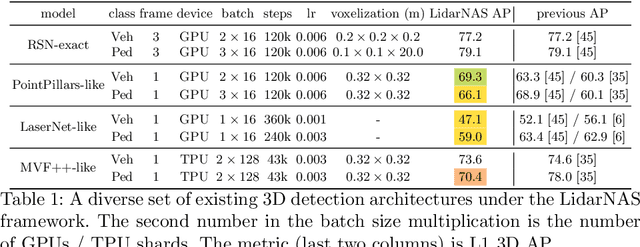

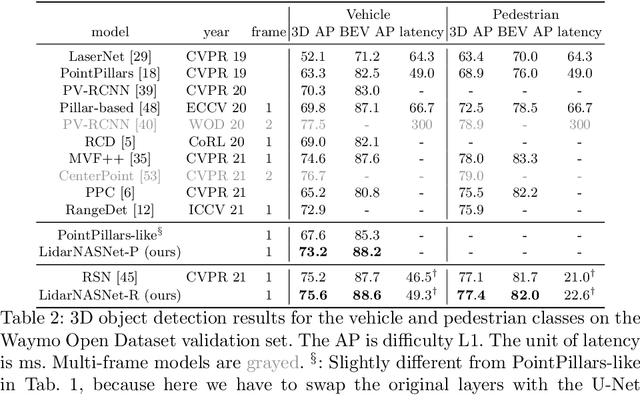
Developing neural models that accurately understand objects in 3D point clouds is essential for the success of robotics and autonomous driving. However, arguably due to the higher-dimensional nature of the data (as compared to images), existing neural architectures exhibit a large variety in their designs, including but not limited to the views considered, the format of the neural features, and the neural operations used. Lack of a unified framework and interpretation makes it hard to put these designs in perspective, as well as systematically explore new ones. In this paper, we begin by proposing a unified framework of such, with the key idea being factorizing the neural networks into a series of view transforms and neural layers. We demonstrate that this modular framework can reproduce a variety of existing works while allowing a fair comparison of backbone designs. Then, we show how this framework can easily materialize into a concrete neural architecture search (NAS) space, allowing a principled NAS-for-3D exploration. In performing evolutionary NAS on the 3D object detection task on the Waymo Open Dataset, not only do we outperform the state-of-the-art models, but also report the interesting finding that NAS tends to discover the same macro-level architecture concept for both the vehicle and pedestrian classes.