 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Modelwith Spatio-Temporal Visual Representation
May 30, 2025

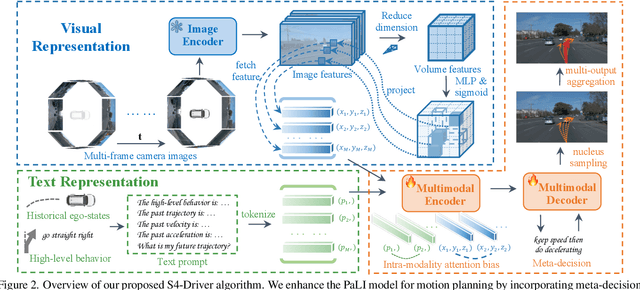

The latest advancements in multi-modal large language models (MLLMs) have spurred a strong renewed interest in end-to-end motion planning approaches for autonomous driving. Many end-to-end approaches rely on human annotations to learn intermediate perception and prediction tasks, while purely self-supervised approaches--which directly learn from sensor inputs to generate planning trajectories without human annotations often underperform the state of the art. We observe a key gap in the input representation space: end-to-end approaches built on MLLMs are often pretrained with reasoning tasks in 2D image space rather than the native 3D space in which autonomous vehicles plan. To this end, we propose S4-Driver, a scalable self-supervised motion planning algorithm with spatio-temporal visual representation, based on the popular PaLI multimodal large language model. S4-Driver uses a novel sparse volume strategy to seamlessly transform the strong visual representation of MLLMs from perspective view to 3D space without the need to finetune the vision encoder. This representation aggregates multi-view and multi-frame visual inputs and enables better prediction of planning trajectories in 3D space. To validate our method, we run experiments on both nuScenes and Waymo Open Motion Dataset (with in-house camera data). Results show that S4-Driver performs favorably against existing supervised multi-task approaches while requiring no human annotations. It also demonstrates great scalability when pretrained on large volumes of unannotated driving logs.
PVTransformer: Point-to-Voxel Transformer for Scalable 3D Object Detection
May 05, 2024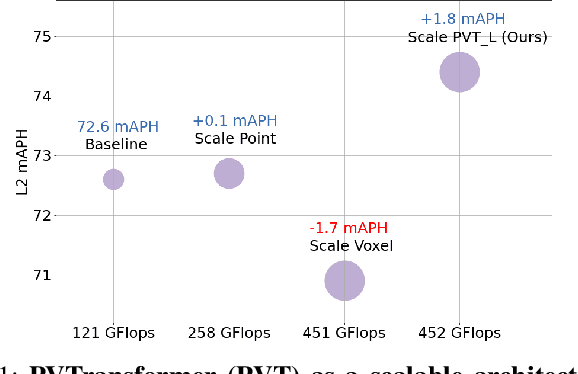
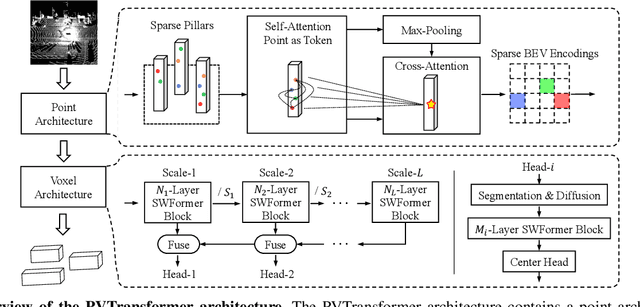
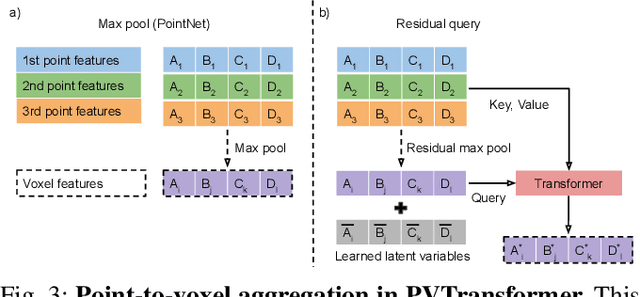
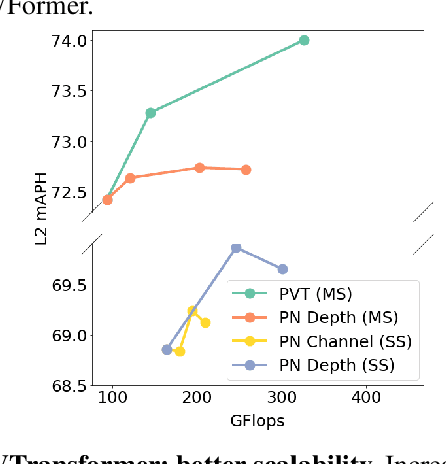
3D object detectors for point clouds often rely on a pooling-based PointNet to encode sparse points into grid-like voxels or pillars. In this paper, we identify that the common PointNet design introduces an information bottleneck that limits 3D object detection accuracy and scalability. To address this limitation, we propose PVTransformer: a transformer-based point-to-voxel architecture for 3D detection. Our key idea is to replace the PointNet pooling operation with an attention module, leading to a better point-to-voxel aggregation function. Our design respects the permutation invariance of sparse 3D points while being more expressive than the pooling-based PointNet. Experimental results show our PVTransformer achieves much better performance compared to the latest 3D object detectors. On the widely used Waymo Open Dataset, our PVTransformer achieves state-of-the-art 76.5 mAPH L2, outperforming the prior art of SWFormer by +1.7 mAPH L2.
LEF: Late-to-Early Temporal Fusion for LiDAR 3D Object Detection
Sep 28, 2023



We propose a late-to-early recurrent feature fusion scheme for 3D object detection using temporal LiDAR point clouds. Our main motivation is fusing object-aware latent embeddings into the early stages of a 3D object detector. This feature fusion strategy enables the model to better capture the shapes and poses for challenging objects, compared with learning from raw points directly. Our method conducts late-to-early feature fusion in a recurrent manner. This is achieved by enforcing window-based attention blocks upon temporally calibrated and aligned sparse pillar tokens. Leveraging bird's eye view foreground pillar segmentation, we reduce the number of sparse history features that our model needs to fuse into its current frame by 10$\times$. We also propose a stochastic-length FrameDrop training technique, which generalizes the model to variable frame lengths at inference for improved performance without retraining. We evaluate our method on the widely adopted Waymo Open Dataset and demonstrate improvement on 3D object detection against the baseline model, especially for the challenging category of large objects.
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.
PseudoAugment: Learning to Use Unlabeled Data for Data Augmentation in Point Clouds
Oct 24, 2022Data augmentation is an important technique to improve data efficiency and save labeling cost for 3D detection in point clouds. Yet, existing augmentation policies have so far been designed to only utilize labeled data, which limits the data diversity. In this paper, we recognize that pseudo labeling and data augmentation are complementary, thus propose to leverage unlabeled data for data augmentation to enrich the training data. In particular, we design three novel pseudo-label based data augmentation policies (PseudoAugments) to fuse both labeled and pseudo-labeled scenes, including frames (PseudoFrame), objecta (PseudoBBox), and background (PseudoBackground). PseudoAugments outperforms pseudo labeling by mitigating pseudo labeling errors and generating diverse fused training scenes. We demonstrate PseudoAugments generalize across point-based and voxel-based architectures, different model capacity and both KITTI and Waymo Open Dataset. To alleviate the cost of hyperparameter tuning and iterative pseudo labeling, we develop a population-based data augmentation framework for 3D detection, named AutoPseudoAugment. Unlike previous works that perform pseudo-labeling offline, our framework performs PseudoAugments and hyperparameter tuning in one shot to reduce computational cost. Experimental results on the large-scale Waymo Open Dataset show our method outperforms state-of-the-art auto data augmentation method (PPBA) and self-training method (pseudo labeling). In particular, AutoPseudoAugment is about 3X and 2X data efficient on vehicle and pedestrian tasks compared to prior arts. Notably, AutoPseudoAugment nearly matches the full dataset training results, with just 10% of the labeled run segments on the vehicle detection task.
LidarAugment: Searching for Scalable 3D LiDAR Data Augmentations
Oct 24, 2022



Data augmentations are important in training high-performance 3D object detectors for point clouds. Despite recent efforts on designing new data augmentations, perhaps surprisingly, most state-of-the-art 3D detectors only use a few simple data augmentations. In particular, different from 2D image data augmentations, 3D data augmentations need to account for different representations of input data and require being customized for different models, which introduces significant overhead. In this paper, we resort to a search-based approach, and propose LidarAugment, a practical and effective data augmentation strategy for 3D object detection. Unlike previous approaches where all augmentation policies are tuned in an exponentially large search space, we propose to factorize and align the search space of each data augmentation, which cuts down the 20+ hyperparameters to 2, and significantly reduces the search complexity. We show LidarAugment can be customized for different model architectures with different input representations by a simple 2D grid search, and consistently improve both convolution-based UPillars/StarNet/RSN and transformer-based SWFormer. Furthermore, LidarAugment mitigates overfitting and allows us to scale up 3D detectors to much larger capacity. In particular, by combining with latest 3D detectors, our LidarAugment achieves a new state-of-the-art 74.8 mAPH L2 on Waymo Open Dataset.
SWFormer: Sparse Window Transformer for 3D Object Detection in Point Clouds
Oct 13, 2022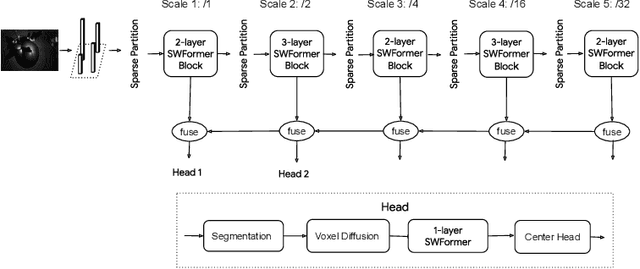
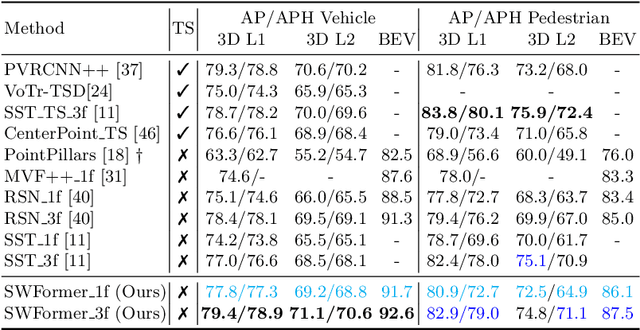
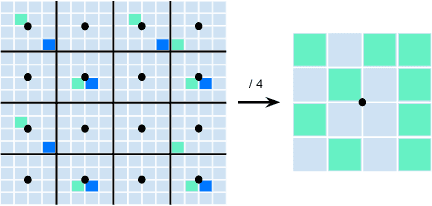

3D object detection in point clouds is a core component for modern robotics and autonomous driving systems. A key challenge in 3D object detection comes from the inherent sparse nature of point occupancy within the 3D scene. In this paper, we propose Sparse Window Transformer (SWFormer ), a scalable and accurate model for 3D object detection, which can take full advantage of the sparsity of point clouds. Built upon the idea of window-based Transformers, SWFormer converts 3D points into sparse voxels and windows, and then processes these variable-length sparse windows efficiently using a bucketing scheme. In addition to self-attention within each spatial window, our SWFormer also captures cross-window correlation with multi-scale feature fusion and window shifting operations. To further address the unique challenge of detecting 3D objects accurately from sparse features, we propose a new voxel diffusion technique. Experimental results on the Waymo Open Dataset show our SWFormer achieves state-of-the-art 73.36 L2 mAPH on vehicle and pedestrian for 3D object detection on the official test set, outperforming all previous single-stage and two-stage models, while being much more efficient.
LidarNAS: Unifying and Searching Neural Architectures for 3D Point Clouds
Oct 10, 2022
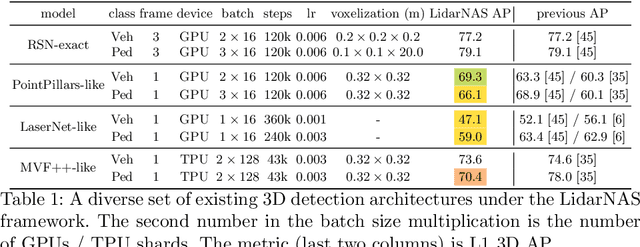

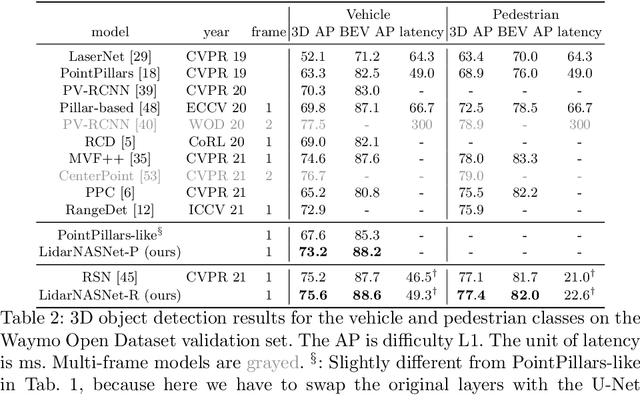
Developing neural models that accurately understand objects in 3D point clouds is essential for the success of robotics and autonomous driving. However, arguably due to the higher-dimensional nature of the data (as compared to images), existing neural architectures exhibit a large variety in their designs, including but not limited to the views considered, the format of the neural features, and the neural operations used. Lack of a unified framework and interpretation makes it hard to put these designs in perspective, as well as systematically explore new ones. In this paper, we begin by proposing a unified framework of such, with the key idea being factorizing the neural networks into a series of view transforms and neural layers. We demonstrate that this modular framework can reproduce a variety of existing works while allowing a fair comparison of backbone designs. Then, we show how this framework can easily materialize into a concrete neural architecture search (NAS) space, allowing a principled NAS-for-3D exploration. In performing evolutionary NAS on the 3D object detection task on the Waymo Open Dataset, not only do we outperform the state-of-the-art models, but also report the interesting finding that NAS tends to discover the same macro-level architecture concept for both the vehicle and pedestrian classes.
Multi-Class 3D Object Detection with Single-Class Supervision
May 11, 2022


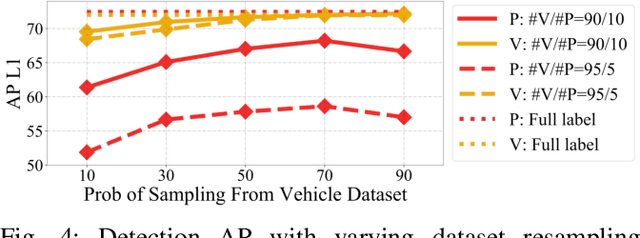
While multi-class 3D detectors are needed in many robotics applications, training them with fully labeled datasets can be expensive in labeling cost. An alternative approach is to have targeted single-class labels on disjoint data samples. In this paper, we are interested in training a multi-class 3D object detection model, while using these single-class labeled data. We begin by detailing the unique stance of our "Single-Class Supervision" (SCS) setting with respect to related concepts such as partial supervision and semi supervision. Then, based on the case study of training the multi-class version of Range Sparse Net (RSN), we adapt a spectrum of algorithms -- from supervised learning to pseudo-labeling -- to fully exploit the properties of our SCS setting, and perform extensive ablation studies to identify the most effective algorithm and practice. Empirical experiments on the Waymo Open Dataset show that proper training under SCS can approach or match full supervision training while saving labeling costs.
PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions
Apr 26, 2022
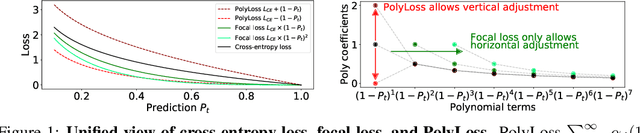

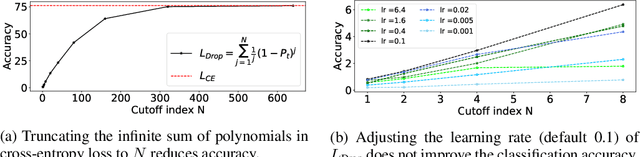
Cross-entropy loss and focal loss are the most common choices when training deep neural networks for classification problems. Generally speaking, however, a good loss function can take on much more flexible forms, and should be tailored for different tasks and datasets. Motivated by how functions can be approximated via Taylor expansion, we propose a simple framework, named PolyLoss, to view and design loss functions as a linear combination of polynomial functions. Our PolyLoss allows the importance of different polynomial bases to be easily adjusted depending on the targeting tasks and datasets, while naturally subsuming the aforementioned cross-entropy loss and focal loss as special cases. Extensive experimental results show that the optimal choice within the PolyLoss is indeed dependent on the task and dataset. Simply by introducing one extra hyperparameter and adding one line of code, our Poly-1 formulation outperforms the cross-entropy loss and focal loss on 2D image classification, instance segmentation, object detection, and 3D object detection tasks, sometimes by a large margin.