 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive My Way: Preference Alignment of Vision-Language-Action Model for Personalized Driving
Mar 26, 2026Human driving behavior is inherently personal, which is shaped by long-term habits and influenced by short-term intentions. Individuals differ in how they accelerate, brake, merge, yield, and overtake across diverse situations. However, existing end-to-end autonomous driving systems either optimize for generic objectives or rely on fixed driving modes, lacking the ability to adapt to individual preferences or interpret natural language intent. To address this gap, we propose Drive My Way (DMW), a personalized Vision-Language-Action (VLA) driving framework that aligns with users' long-term driving habits and adapts to real-time user instructions. DMW learns a user embedding from our personalized driving dataset collected across multiple real drivers and conditions the policy on this embedding during planning, while natural language instructions provide additional short-term guidance. Closed-loop evaluation on the Bench2Drive benchmark demonstrates that DMW improves style instruction adaptation, and user studies show that its generated behaviors are recognizable as each driver's own style, highlighting personalization as a key capability for human-centered autonomous driving. Our data and code are available at https://dmw-cvpr.github.io/.
COOPERTRIM: Adaptive Data Selection for Uncertainty-Aware Cooperative Perception
Feb 07, 2026Cooperative perception enables autonomous agents to share encoded representations over wireless communication to enhance each other's live situational awareness. However, the tension between the limited communication bandwidth and the rich sensor information hinders its practical deployment. Recent studies have explored selection strategies that share only a subset of features per frame while striving to keep the performance on par. Nevertheless, the bandwidth requirement still stresses current wireless technologies. To fundamentally ease the tension, we take a proactive approach, exploiting the temporal continuity to identify features that capture environment dynamics, while avoiding repetitive and redundant transmission of static information. By incorporating temporal awareness, agents are empowered to dynamically adapt the sharing quantity according to environment complexity. We instantiate this intuition into an adaptive selection framework, COOPERTRIM, which introduces a novel conformal temporal uncertainty metric to gauge feature relevance, and a data-driven mechanism to dynamically determine the sharing quantity. To evaluate COOPERTRIM, we take semantic segmentation and 3D detection as example tasks. Across multiple open-source cooperative segmentation and detection models, COOPERTRIM achieves up to 80.28% and 72.52% bandwidth reduction respectively while maintaining a comparable accuracy. Relative to other selection strategies, COOPERTRIM also improves IoU by as much as 45.54% with up to 72% less bandwidth. Combined with compression strategies, COOPERTRIM can further reduce bandwidth usage to as low as 1.46% without compromising IoU performance. Qualitative results show COOPERTRIM gracefully adapts to environmental dynamics, localization error, and communication latency, demonstrating flexibility and paving the way for real-world deployment.
Towards Natural Language Communication for Cooperative Autonomous Driving via Self-Play
May 23, 2025



Past work has demonstrated that autonomous vehicles can drive more safely if they communicate with one another than if they do not. However, their communication has often not been human-understandable. Using natural language as a vehicle-to-vehicle (V2V) communication protocol offers the potential for autonomous vehicles to drive cooperatively not only with each other but also with human drivers. In this work, we propose a suite of traffic tasks in autonomous driving where vehicles in a traffic scenario need to communicate in natural language to facilitate coordination in order to avoid an imminent collision and/or support efficient traffic flow. To this end, this paper introduces a novel method, LLM+Debrief, to learn a message generation and high-level decision-making policy for autonomous vehicles through multi-agent discussion. To evaluate LLM agents for driving, we developed a gym-like simulation environment that contains a range of driving scenarios. Our experimental results demonstrate that LLM+Debrief is more effective at generating meaningful and human-understandable natural language messages to facilitate cooperation and coordination than a zero-shot LLM agent. Our code and demo videos are available at https://talking-vehicles.github.io/.
FluidML: Fast and Memory Efficient Inference Optimization
Nov 14, 2024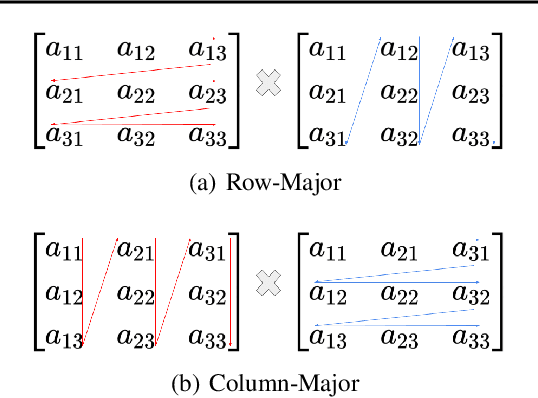
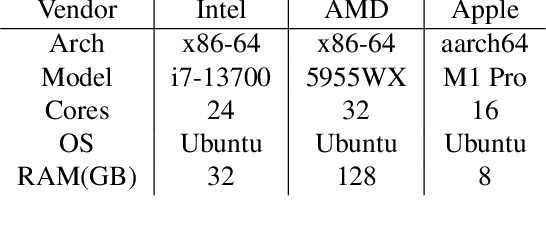
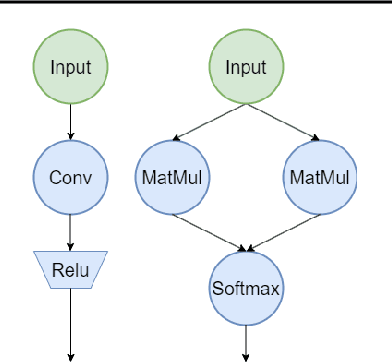
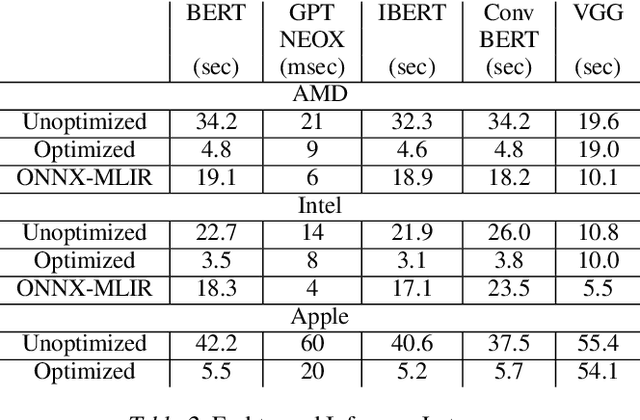
Machine learning models deployed on edge devices have enabled numerous exciting new applications, such as humanoid robots, AR glasses, and autonomous vehicles. However, the computing resources available on these edge devices are not catching up with the ever-growing number of parameters in these models. As the models become bigger and more complicated, the novel yet sophisticated structure challenges the inference runtime optimization. We present FluidML, a generic runtime memory management and optimization framework that can flexibly transform the model execution blueprint to achieve faster and more memory-efficient inference. Evaluations across different platforms show that FluidML can consistently reduce the end-to-end inference latency by up to 25.38% for popular language models and reduce peak memory usage by up to 41.47%, compared to state-of-the-art approaches. FluidML is of ~30K line of codes, built for general-purpose usage, and will be released as an open-source inference runtime optimization framework to the community.
Can We Remove the Ground? Obstacle-aware Point Cloud Compression for Remote Object Detection
Oct 01, 2024
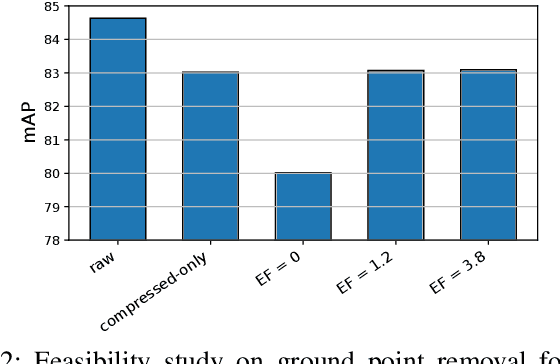
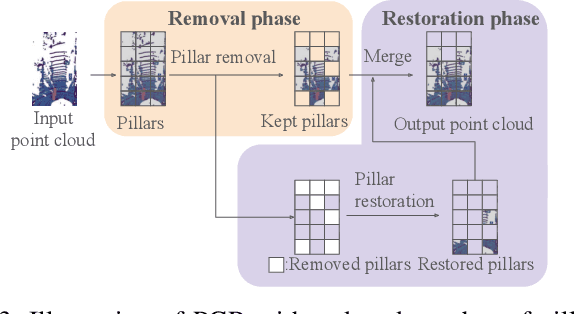
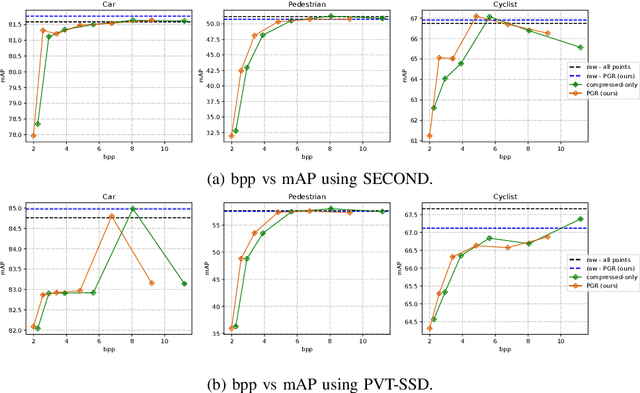
Efficient point cloud (PC) compression is crucial for streaming applications, such as augmented reality and cooperative perception. Classic PC compression techniques encode all the points in a frame. Tailoring compression towards perception tasks at the receiver side, we ask the question, "Can we remove the ground points during transmission without sacrificing the detection performance?" Our study reveals a strong dependency on the ground from state-of-the-art (SOTA) 3D object detection models, especially on those points below and around the object. In this work, we propose a lightweight obstacle-aware Pillar-based Ground Removal (PGR) algorithm. PGR filters out ground points that do not provide context to object recognition, significantly improving compression ratio without sacrificing the receiver side perception performance. Not using heavy object detection or semantic segmentation models, PGR is light-weight, highly parallelizable, and effective. Our evaluations on KITTI and Waymo Open Dataset show that SOTA detection models work equally well with PGR removing 20-30% of the points, with a speeding of 86 FPS.
CMP: Cooperative Motion Prediction with Multi-Agent Communication
Mar 26, 2024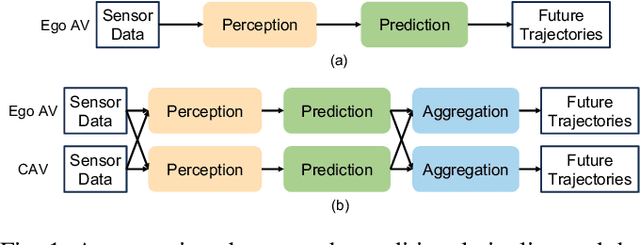
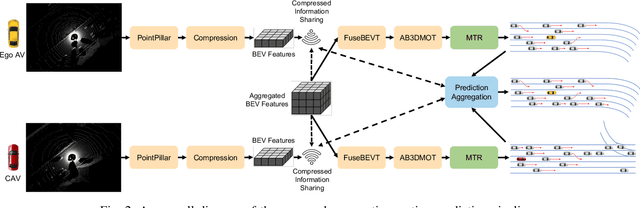
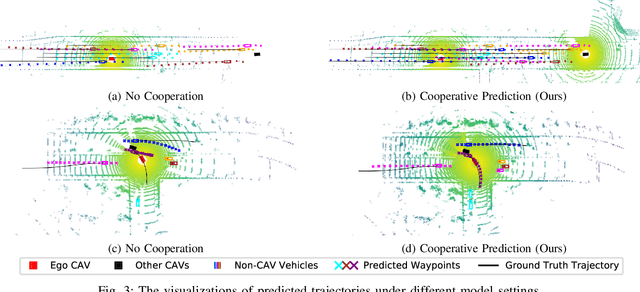
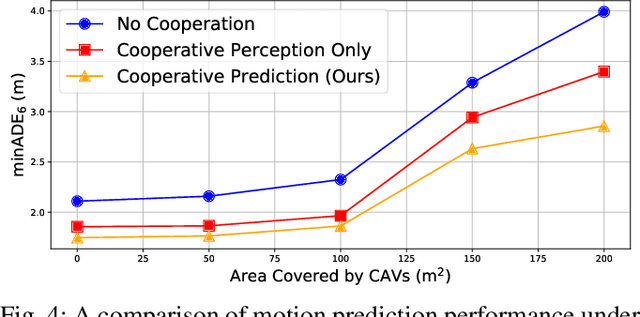
The confluence of the advancement of Autonomous Vehicles (AVs) and the maturity of Vehicle-to-Everything (V2X) communication has enabled the capability of cooperative connected and automated vehicles (CAVs). Building on top of cooperative perception, this paper explores the feasibility and effectiveness of cooperative motion prediction. Our method, CMP, takes LiDAR signals as input to enhance tracking and prediction capabilities. Unlike previous work that focuses separately on either cooperative perception or motion prediction, our framework, to the best of our knowledge, is the first to address the unified problem where CAVs share information in both perception and prediction modules. Incorporated into our design is the unique capability to tolerate realistic V2X bandwidth limitations and transmission delays, while dealing with bulky perception representations. We also propose a prediction aggregation module, which unifies the predictions obtained by different CAVs and generates the final prediction. Through extensive experiments and ablation studies, we demonstrate the effectiveness of our method in cooperative perception, tracking, and motion prediction tasks. In particular, CMP reduces the average prediction error by 17.2\% with fewer missing detections compared with the no cooperation setting. Our work marks a significant step forward in the cooperative capabilities of CAVs, showcasing enhanced performance in complex scenarios.
Embodied Understanding of Driving Scenarios
Mar 07, 2024
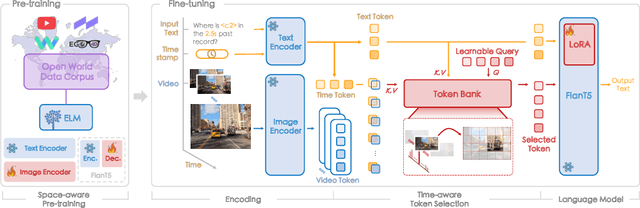
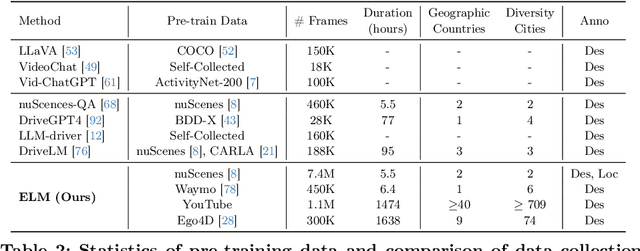
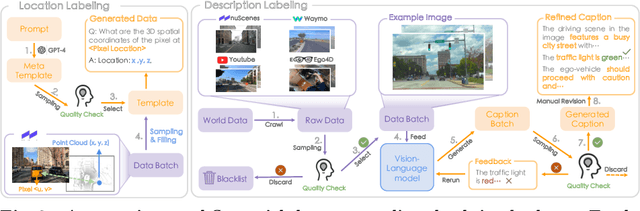
Embodied scene understanding serves as the cornerstone for autonomous agents to perceive, interpret, and respond to open driving scenarios. Such understanding is typically founded upon Vision-Language Models (VLMs). Nevertheless, existing VLMs are restricted to the 2D domain, devoid of spatial awareness and long-horizon extrapolation proficiencies. We revisit the key aspects of autonomous driving and formulate appropriate rubrics. Hereby, we introduce the Embodied Language Model (ELM), a comprehensive framework tailored for agents' understanding of driving scenes with large spatial and temporal spans. ELM incorporates space-aware pre-training to endow the agent with robust spatial localization capabilities. Besides, the model employs time-aware token selection to accurately inquire about temporal cues. We instantiate ELM on the reformulated multi-faced benchmark, and it surpasses previous state-of-the-art approaches in all aspects. All code, data, and models will be publicly shared.
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.
COOPERNAUT: End-to-End Driving with Cooperative Perception for Networked Vehicles
May 04, 2022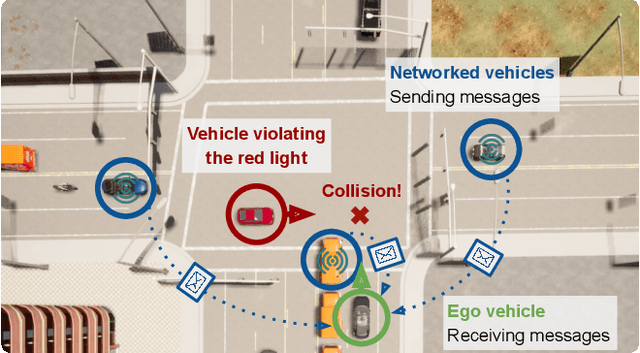

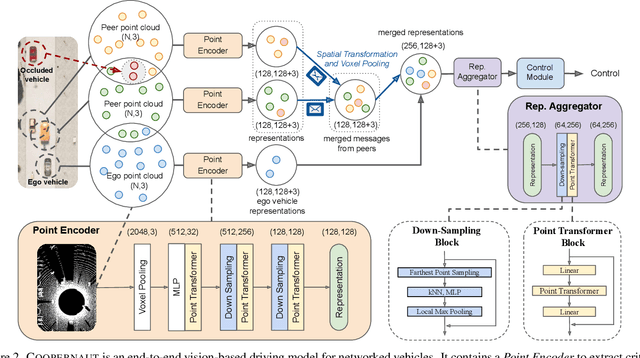

Optical sensors and learning algorithms for autonomous vehicles have dramatically advanced in the past few years. Nonetheless, the reliability of today's autonomous vehicles is hindered by the limited line-of-sight sensing capability and the brittleness of data-driven methods in handling extreme situations. With recent developments of telecommunication technologies, cooperative perception with vehicle-to-vehicle communications has become a promising paradigm to enhance autonomous driving in dangerous or emergency situations. We introduce COOPERNAUT, an end-to-end learning model that uses cross-vehicle perception for vision-based cooperative driving. Our model encodes LiDAR information into compact point-based representations that can be transmitted as messages between vehicles via realistic wireless channels. To evaluate our model, we develop AutoCastSim, a network-augmented driving simulation framework with example accident-prone scenarios. Our experiments on AutoCastSim suggest that our cooperative perception driving models lead to a 40% improvement in average success rate over egocentric driving models in these challenging driving situations and a 5 times smaller bandwidth requirement than prior work V2VNet. COOPERNAUT and AUTOCASTSIM are available at https://ut-austin-rpl.github.io/Coopernaut/.
Personalized Federated Learning of Driver Prediction Models for Autonomous Driving
Dec 02, 2021
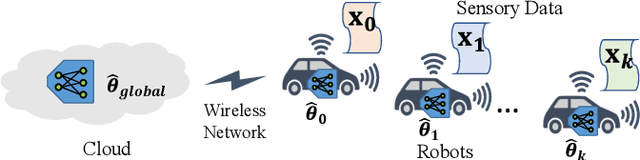
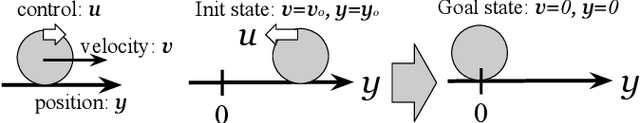
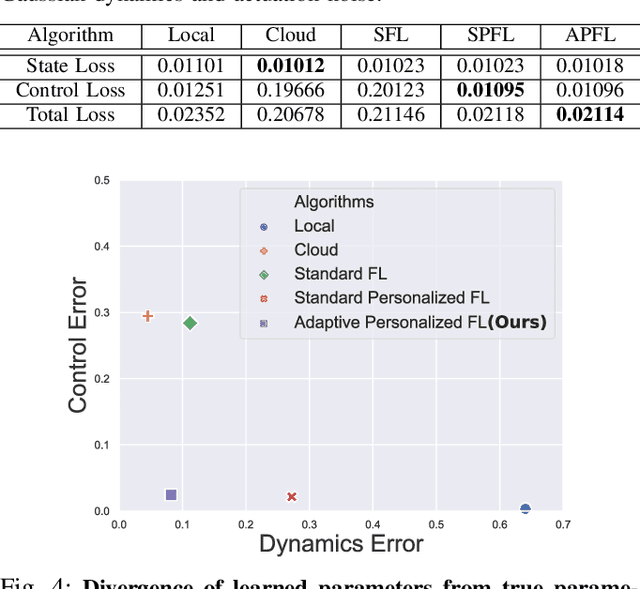
Autonomous vehicles (AVs) must interact with a diverse set of human drivers in heterogeneous geographic areas. Ideally, fleets of AVs should share trajectory data to continually re-train and improve trajectory forecasting models from collective experience using cloud-based distributed learning. At the same time, these robots should ideally avoid uploading raw driver interaction data in order to protect proprietary policies (when sharing insights with other companies) or protect driver privacy from insurance companies. Federated learning (FL) is a popular mechanism to learn models in cloud servers from diverse users without divulging private local data. However, FL is often not robust -- it learns sub-optimal models when user data comes from highly heterogeneous distributions, which is a key hallmark of human-robot interactions. In this paper, we present a novel variant of personalized FL to specialize robust robot learning models to diverse user distributions. Our algorithm outperforms standard FL benchmarks by up to 2x in real user studies that we conducted where human-operated vehicles must gracefully merge lanes with simulated AVs in the standard CARLA and CARLO AV simulators.