 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Federated Learning of Driver Prediction Models for Autonomous Driving
Dec 02, 2021
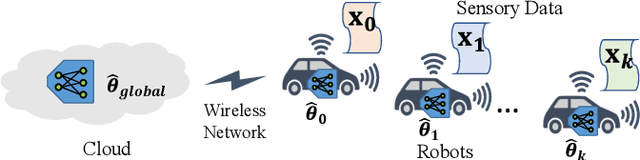
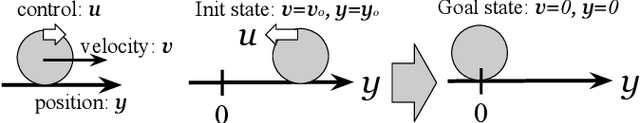
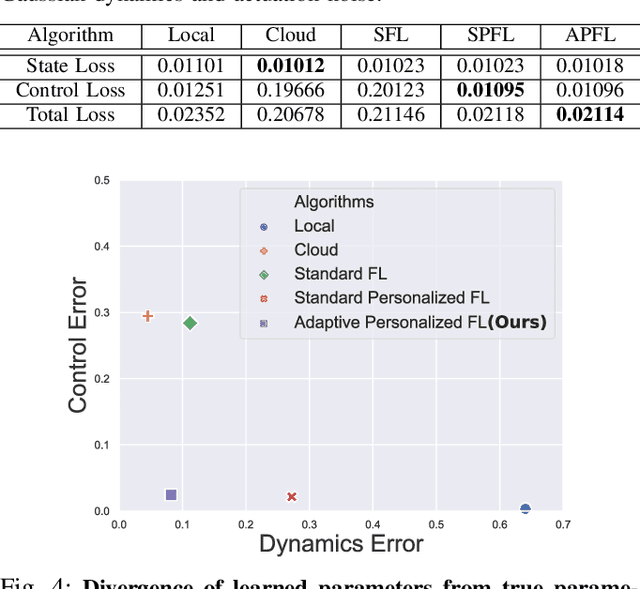
Autonomous vehicles (AVs) must interact with a diverse set of human drivers in heterogeneous geographic areas. Ideally, fleets of AVs should share trajectory data to continually re-train and improve trajectory forecasting models from collective experience using cloud-based distributed learning. At the same time, these robots should ideally avoid uploading raw driver interaction data in order to protect proprietary policies (when sharing insights with other companies) or protect driver privacy from insurance companies. Federated learning (FL) is a popular mechanism to learn models in cloud servers from diverse users without divulging private local data. However, FL is often not robust -- it learns sub-optimal models when user data comes from highly heterogeneous distributions, which is a key hallmark of human-robot interactions. In this paper, we present a novel variant of personalized FL to specialize robust robot learning models to diverse user distributions. Our algorithm outperforms standard FL benchmarks by up to 2x in real user studies that we conducted where human-operated vehicles must gracefully merge lanes with simulated AVs in the standard CARLA and CARLO AV simulators.
Sampling Training Data for Continual Learning Between Robots and the Cloud
Dec 12, 2020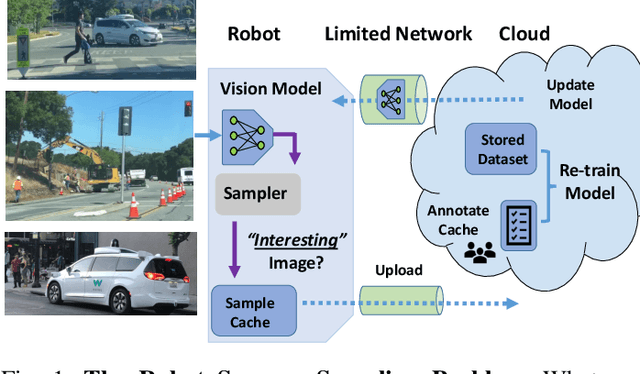
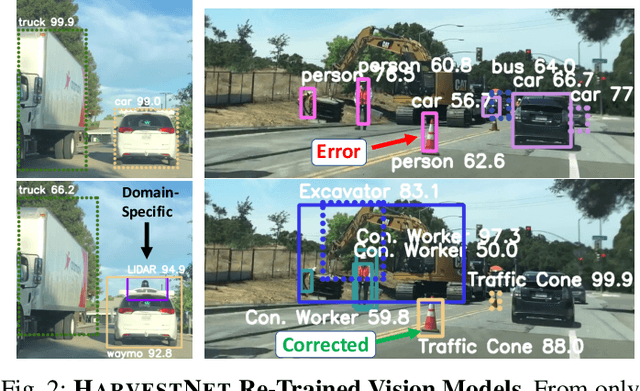
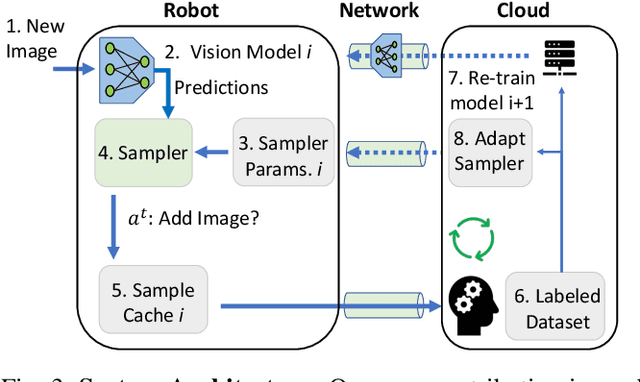
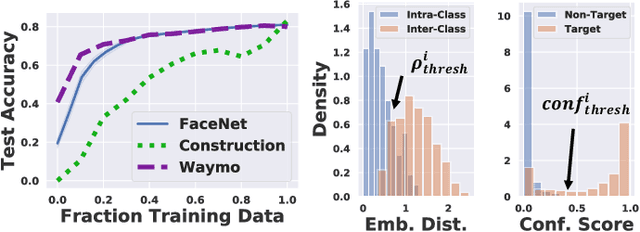
Today's robotic fleets are increasingly measuring high-volume video and LIDAR sensory streams, which can be mined for valuable training data, such as rare scenes of road construction sites, to steadily improve robotic perception models. However, re-training perception models on growing volumes of rich sensory data in central compute servers (or the "cloud") places an enormous time and cost burden on network transfer, cloud storage, human annotation, and cloud computing resources. Hence, we introduce HarvestNet, an intelligent sampling algorithm that resides on-board a robot and reduces system bottlenecks by only storing rare, useful events to steadily improve perception models re-trained in the cloud. HarvestNet significantly improves the accuracy of machine-learning models on our novel dataset of road construction sites, field testing of self-driving cars, and streaming face recognition, while reducing cloud storage, dataset annotation time, and cloud compute time by between 65.7-81.3%. Further, it is between 1.05-2.58x more accurate than baseline algorithms and scalably runs on embedded deep learning hardware. We provide a suite of compute-efficient perception models for the Google Edge Tensor Processing Unit (TPU), an extended technical report, and a novel video dataset to the research community at https://sites.google.com/view/harvestnet.
Task-relevant Representation Learning for Networked Robotic Perception
Nov 06, 2020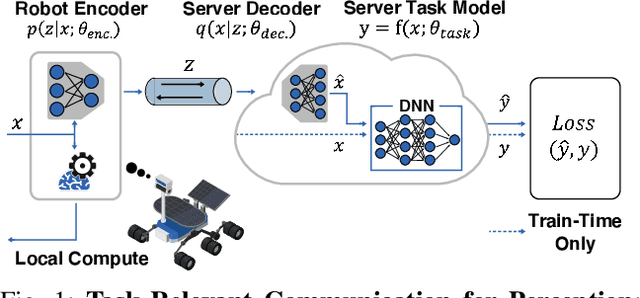
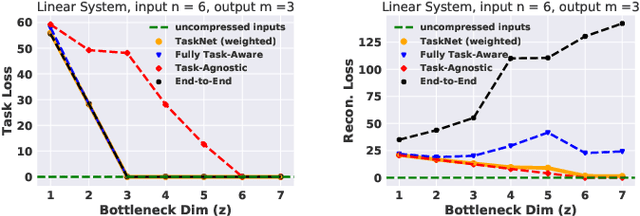
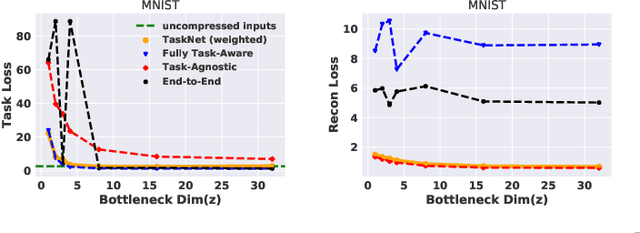
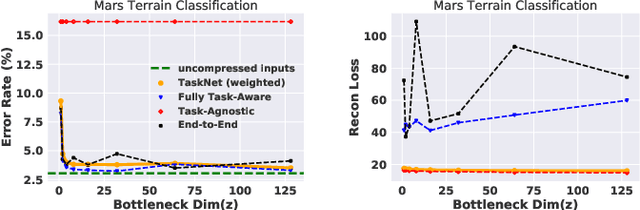
Today, even the most compute-and-power constrained robots can measure complex, high data-rate video and LIDAR sensory streams. Often, such robots, ranging from low-power drones to space and subterranean rovers, need to transmit high-bitrate sensory data to a remote compute server if they are uncertain or cannot scalably run complex perception or mapping tasks locally. However, today's representations for sensory data are mostly designed for human, not robotic, perception and thus often waste precious compute or wireless network resources to transmit unimportant parts of a scene that are unnecessary for a high-level robotic task. This paper presents an algorithm to learn task-relevant representations of sensory data that are co-designed with a pre-trained robotic perception model's ultimate objective. Our algorithm aggressively compresses robotic sensory data by up to 11x more than competing methods. Further, it achieves high accuracy and robust generalization on diverse tasks including Mars terrain classification with low-power deep learning accelerators, neural motion planning, and environmental timeseries classification.