 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Models: Constructing Evasive Attacks on Edge Models
Apr 22, 2022
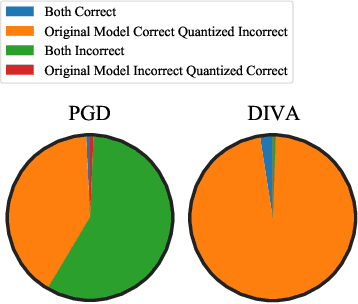
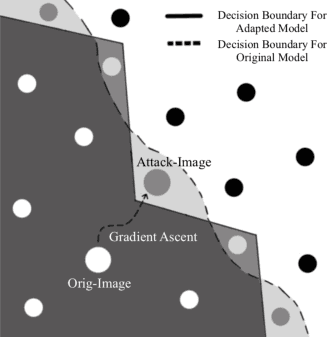
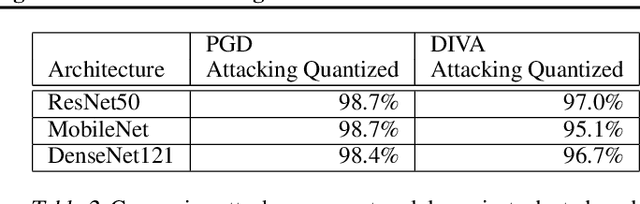
Full-precision deep learning models are typically too large or costly to deploy on edge devices. To accommodate to the limited hardware resources, models are adapted to the edge using various edge-adaptation techniques, such as quantization and pruning. While such techniques may have a negligible impact on top-line accuracy, the adapted models exhibit subtle differences in output compared to the original model from which they are derived. In this paper, we introduce a new evasive attack, DIVA, that exploits these differences in edge adaptation, by adding adversarial noise to input data that maximizes the output difference between the original and adapted model. Such an attack is particularly dangerous, because the malicious input will trick the adapted model running on the edge, but will be virtually undetectable by the original model, which typically serves as the authoritative model version, used for validation, debugging and retraining. We compare DIVA to a state-of-the-art attack, PGD, and show that DIVA is only 1.7-3.6% worse on attacking the adapted model but 1.9-4.2 times more likely not to be detected by the the original model under a whitebox and semi-blackbox setting, compared to PGD.
Sampling Training Data for Continual Learning Between Robots and the Cloud
Dec 12, 2020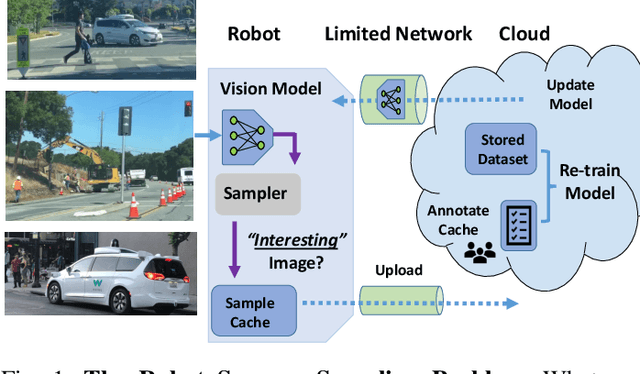
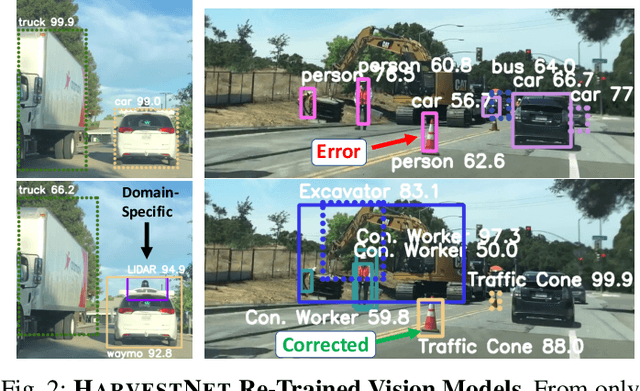
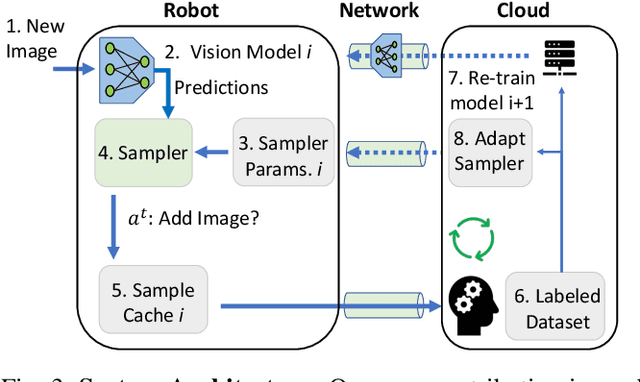
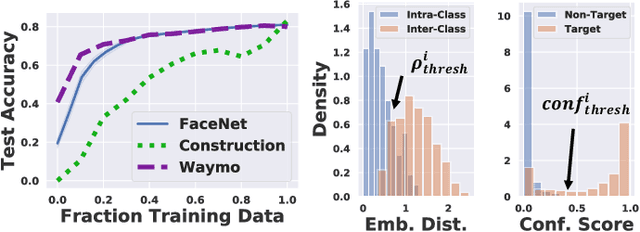
Today's robotic fleets are increasingly measuring high-volume video and LIDAR sensory streams, which can be mined for valuable training data, such as rare scenes of road construction sites, to steadily improve robotic perception models. However, re-training perception models on growing volumes of rich sensory data in central compute servers (or the "cloud") places an enormous time and cost burden on network transfer, cloud storage, human annotation, and cloud computing resources. Hence, we introduce HarvestNet, an intelligent sampling algorithm that resides on-board a robot and reduces system bottlenecks by only storing rare, useful events to steadily improve perception models re-trained in the cloud. HarvestNet significantly improves the accuracy of machine-learning models on our novel dataset of road construction sites, field testing of self-driving cars, and streaming face recognition, while reducing cloud storage, dataset annotation time, and cloud compute time by between 65.7-81.3%. Further, it is between 1.05-2.58x more accurate than baseline algorithms and scalably runs on embedded deep learning hardware. We provide a suite of compute-efficient perception models for the Google Edge Tensor Processing Unit (TPU), an extended technical report, and a novel video dataset to the research community at https://sites.google.com/view/harvestnet.
Characterizing and Taming Model Instability Across Edge Devices
Oct 18, 2020

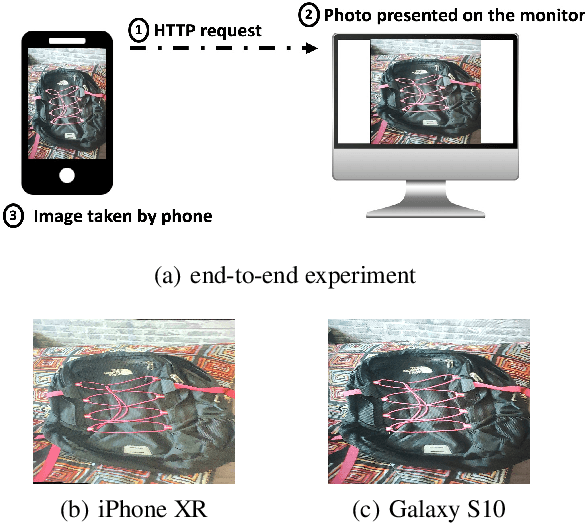
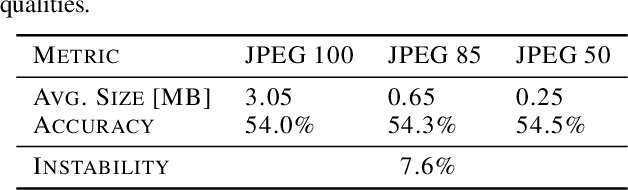
The same machine learning model running on different edge devices may produce highly-divergent outputs on a nearly-identical input. Possible reasons for the divergence include differences in the device sensors, the device's signal processing hardware and software, and its operating system and processors. This paper presents the first methodical characterization of the variations in model prediction across real-world mobile devices. We demonstrate that accuracy is not a useful metric to characterize prediction divergence, and introduce a new metric, instability, which captures this variation. We characterize different sources for instability, and show that differences in compression formats and image signal processing account for significant instability in object classification models. Notably, in our experiments, 14-17% of images produced divergent classifications across one or more phone models. We evaluate three different techniques for reducing instability. In particular, we adapt prior work on making models robust to noise in order to fine-tune models to be robust to variations across edge devices. We demonstrate our fine-tuning techniques reduce instability by 75%.
Network Offloading Policies for Cloud Robotics: a Learning-based Approach
Feb 15, 2019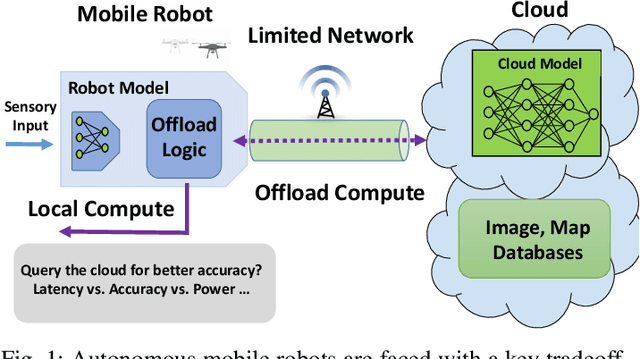
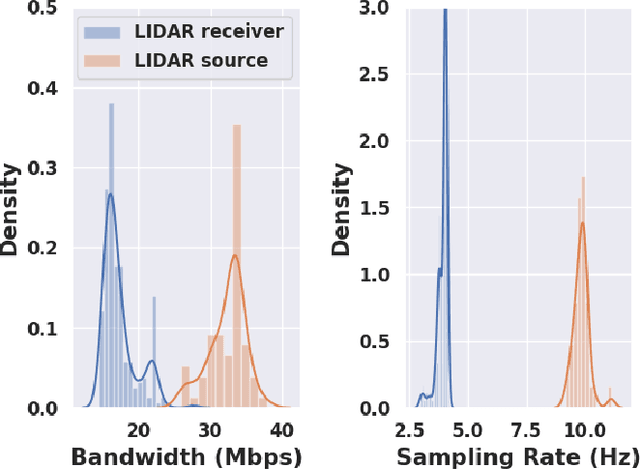
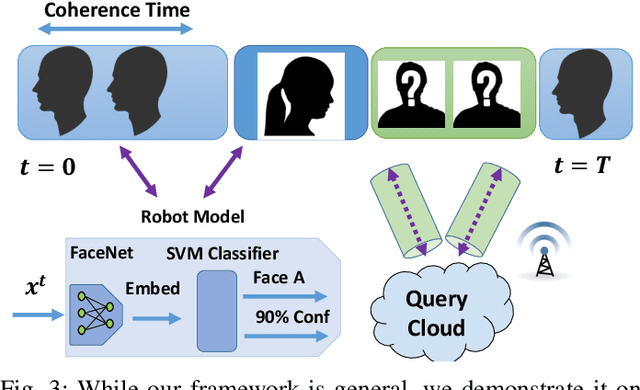
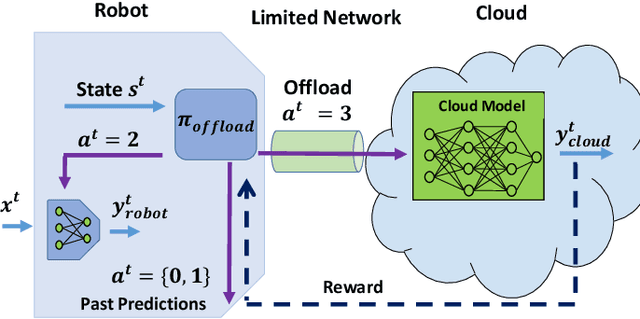
Today's robotic systems are increasingly turning to computationally expensive models such as deep neural networks (DNNs) for tasks like localization, perception, planning, and object detection. However, resource-constrained robots, like low-power drones, often have insufficient on-board compute resources or power reserves to scalably run the most accurate, state-of-the art neural network compute models. Cloud robotics allows mobile robots the benefit of offloading compute to centralized servers if they are uncertain locally or want to run more accurate, compute-intensive models. However, cloud robotics comes with a key, often understated cost: communicating with the cloud over congested wireless networks may result in latency or loss of data. In fact, sending high data-rate video or LIDAR from multiple robots over congested networks can lead to prohibitive delay for real-time applications, which we measure experimentally. In this paper, we formulate a novel Robot Offloading Problem --- how and when should robots offload sensing tasks, especially if they are uncertain, to improve accuracy while minimizing the cost of cloud communication? We formulate offloading as a sequential decision making problem for robots, and propose a solution using deep reinforcement learning. In both simulations and hardware experiments using state-of-the art vision DNNs, our offloading strategy improves vision task performance by between 1.3-2.6x of benchmark offloading strategies, allowing robots the potential to significantly transcend their on-board sensing accuracy but with limited cost of cloud communication.