 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIM: Video Coding using Perceptual Importance Maps
Dec 20, 2022Human perception is at the core of lossy video compression, with numerous approaches developed for perceptual quality assessment and improvement over the past two decades. In the determination of perceptual quality, different spatio-temporal regions of the video differ in their relative importance to the human viewer. However, since it is challenging to infer or even collect such fine-grained information, it is often not used during compression beyond low-level heuristics. We present a framework which facilitates research into fine-grained subjective importance in compressed videos, which we then utilize to improve the rate-distortion performance of an existing video codec (x264). The contributions of this work are threefold: (1) we introduce a web-tool which allows scalable collection of fine-grained perceptual importance, by having users interactively paint spatio-temporal maps over encoded videos; (2) we use this tool to collect a dataset with 178 videos with a total of 14443 frames of human annotated spatio-temporal importance maps over the videos; and (3) we use our curated dataset to train a lightweight machine learning model which can predict these spatio-temporal importance regions. We demonstrate via a subjective study that encoding the videos in our dataset while taking into account the importance maps leads to higher perceptual quality at the same bitrate, with the videos encoded with importance maps preferred $2.1 \times$ over the baseline videos. Similarly, we show that for the 18 videos in test set, the importance maps predicted by our model lead to higher perceptual quality videos, $2 \times$ preferred over the baseline at the same bitrate.
An Interactive Annotation Tool for Perceptual Video Compression
May 08, 2022


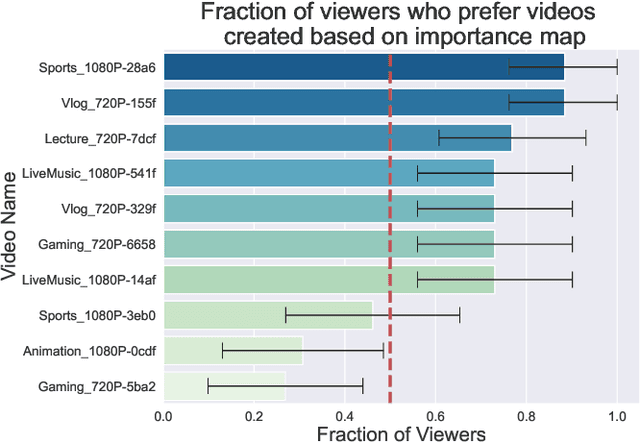
Human perception is at the core of lossy video compression and yet, it is challenging to collect data that is sufficiently dense to drive compression. In perceptual quality assessment, human feedback is typically collected as a single scalar quality score indicating preference of one distorted video over another. In reality, some videos may be better in some parts but not in others. We propose an approach to collecting finer-grained feedback by asking users to use an interactive tool to directly optimize for perceptual quality given a fixed bitrate. To this end, we built a novel web-tool which allows users to paint these spatio-temporal importance maps over videos. The tool allows for interactive successive refinement: we iteratively re-encode the original video according to the painted importance maps, while maintaining the same bitrate, thus allowing the user to visually see the trade-off of assigning higher importance to one spatio-temporal part of the video at the cost of others. We use this tool to collect data in-the-wild (10 videos, 17 users) and utilize the obtained importance maps in the context of x264 coding to demonstrate that the tool can indeed be used to generate videos which, at the same bitrate, look perceptually better through a subjective study - and are 1.9 times more likely to be preferred by viewers. The code for the tool and dataset can be found at https://github.com/jenyap/video-annotation-tool.git
ML-EXray: Visibility into ML Deployment on the Edge
Nov 08, 2021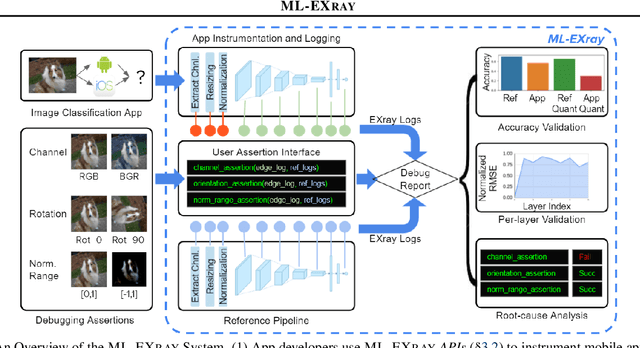
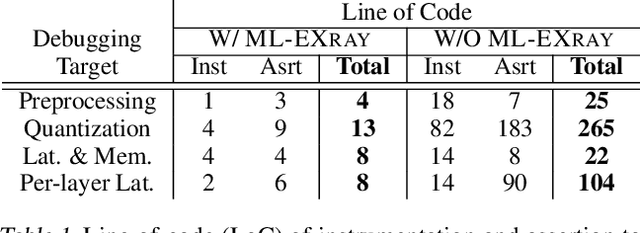
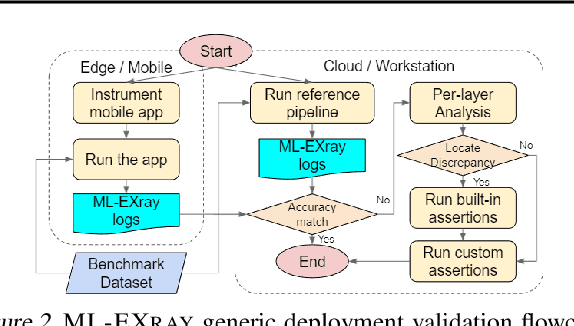
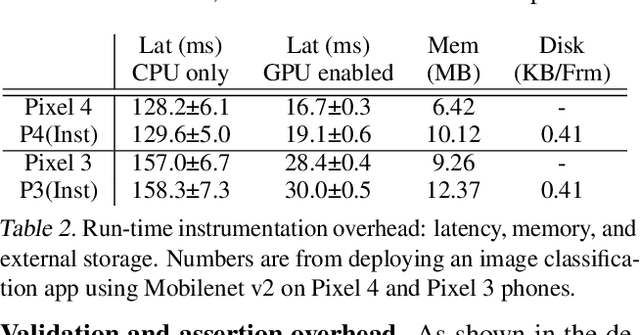
Benefiting from expanding cloud infrastructure, deep neural networks (DNNs) today have increasingly high performance when trained in the cloud. Researchers spend months of effort competing for an extra few percentage points of model accuracy. However, when these models are actually deployed on edge devices in practice, very often, the performance can abruptly drop over 10% without obvious reasons. The key challenge is that there is not much visibility into ML inference execution on edge devices, and very little awareness of potential issues during the edge deployment process. We present ML-EXray, an end-to-end framework, which provides visibility into layer-level details of the ML execution, and helps developers analyze and debug cloud-to-edge deployment issues. More often than not, the reason for sub-optimal edge performance does not only lie in the model itself, but every operation throughout the data flow and the deployment process. Evaluations show that ML-EXray can effectively catch deployment issues, such as pre-processing bugs, quantization issues, suboptimal kernels, etc. Using ML-EXray, users need to write less than 15 lines of code to fully examine the edge deployment pipeline. Eradicating these issues, ML-EXray can correct model performance by up to 30%, pinpoint error-prone layers, and guide users to optimize kernel execution latency by two orders of magnitude. Code and APIs will be released as an open-source multi-lingual instrumentation library and a Python deployment validation library.
Sampling Training Data for Continual Learning Between Robots and the Cloud
Dec 12, 2020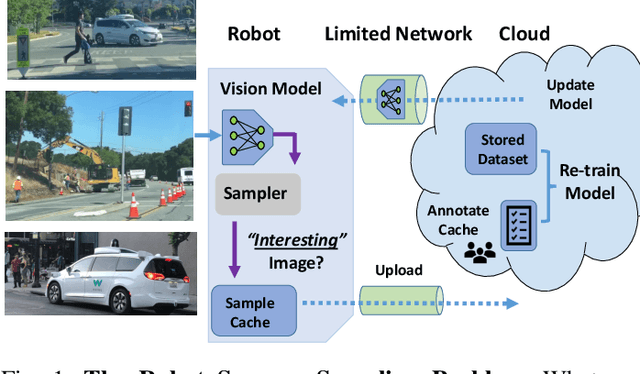
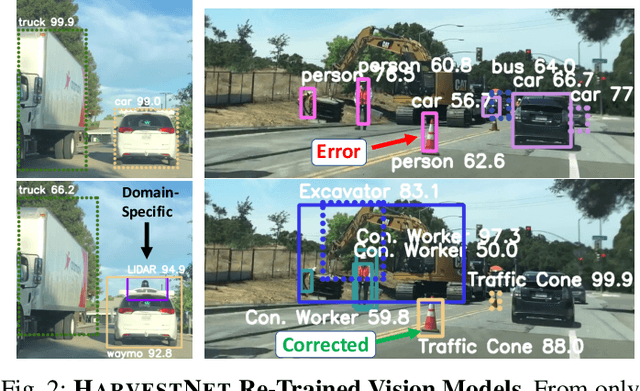
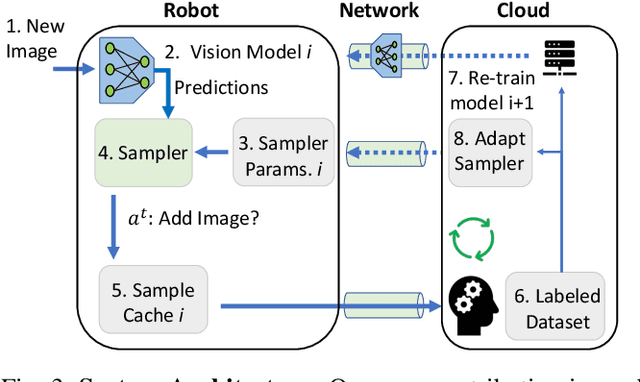
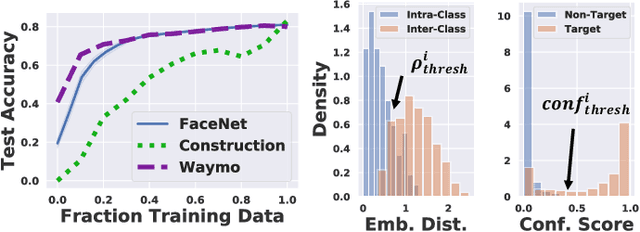
Today's robotic fleets are increasingly measuring high-volume video and LIDAR sensory streams, which can be mined for valuable training data, such as rare scenes of road construction sites, to steadily improve robotic perception models. However, re-training perception models on growing volumes of rich sensory data in central compute servers (or the "cloud") places an enormous time and cost burden on network transfer, cloud storage, human annotation, and cloud computing resources. Hence, we introduce HarvestNet, an intelligent sampling algorithm that resides on-board a robot and reduces system bottlenecks by only storing rare, useful events to steadily improve perception models re-trained in the cloud. HarvestNet significantly improves the accuracy of machine-learning models on our novel dataset of road construction sites, field testing of self-driving cars, and streaming face recognition, while reducing cloud storage, dataset annotation time, and cloud compute time by between 65.7-81.3%. Further, it is between 1.05-2.58x more accurate than baseline algorithms and scalably runs on embedded deep learning hardware. We provide a suite of compute-efficient perception models for the Google Edge Tensor Processing Unit (TPU), an extended technical report, and a novel video dataset to the research community at https://sites.google.com/view/harvestnet.
Characterizing and Taming Model Instability Across Edge Devices
Oct 18, 2020

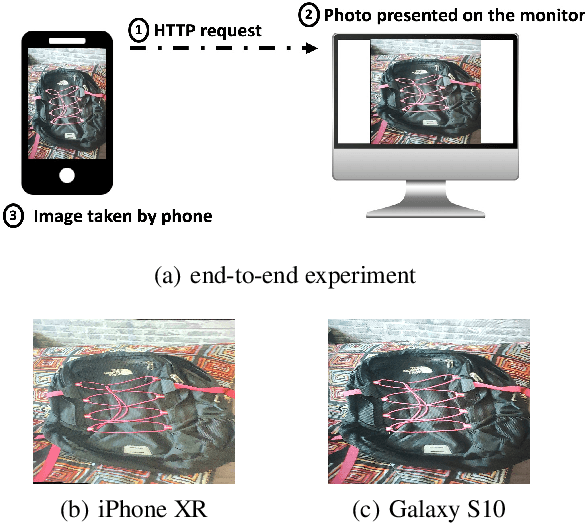
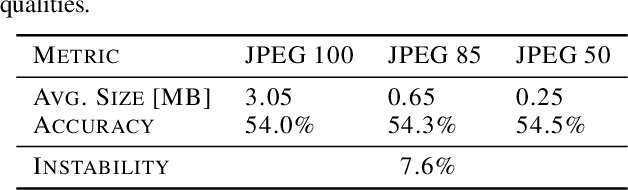
The same machine learning model running on different edge devices may produce highly-divergent outputs on a nearly-identical input. Possible reasons for the divergence include differences in the device sensors, the device's signal processing hardware and software, and its operating system and processors. This paper presents the first methodical characterization of the variations in model prediction across real-world mobile devices. We demonstrate that accuracy is not a useful metric to characterize prediction divergence, and introduce a new metric, instability, which captures this variation. We characterize different sources for instability, and show that differences in compression formats and image signal processing account for significant instability in object classification models. Notably, in our experiments, 14-17% of images produced divergent classifications across one or more phone models. We evaluate three different techniques for reducing instability. In particular, we adapt prior work on making models robust to noise in order to fine-tune models to be robust to variations across edge devices. We demonstrate our fine-tuning techniques reduce instability by 75%.
Network Offloading Policies for Cloud Robotics: a Learning-based Approach
Feb 15, 2019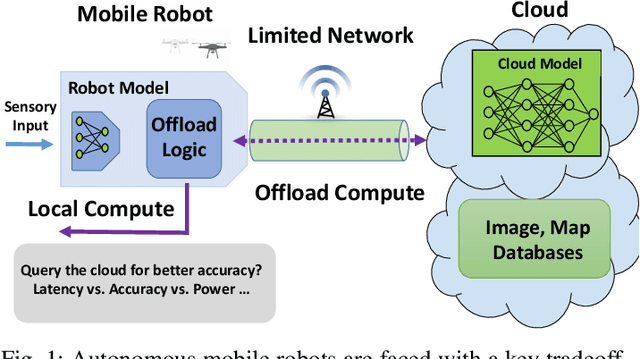
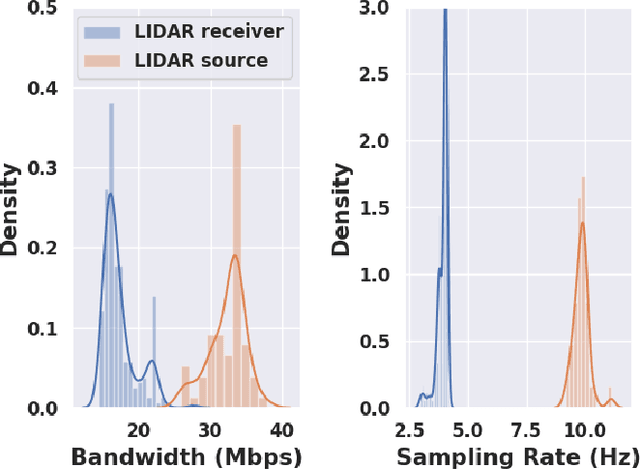
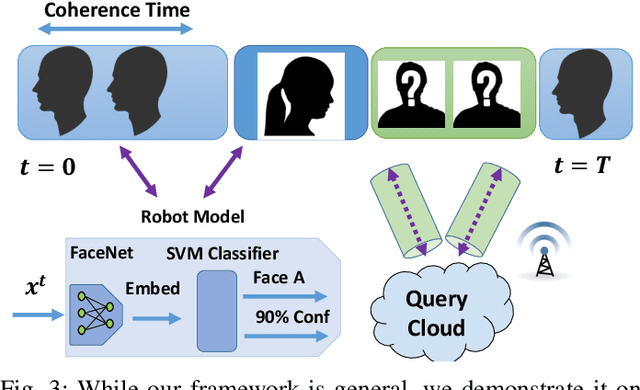
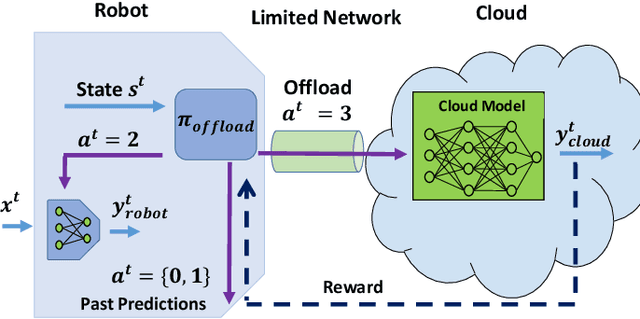
Today's robotic systems are increasingly turning to computationally expensive models such as deep neural networks (DNNs) for tasks like localization, perception, planning, and object detection. However, resource-constrained robots, like low-power drones, often have insufficient on-board compute resources or power reserves to scalably run the most accurate, state-of-the art neural network compute models. Cloud robotics allows mobile robots the benefit of offloading compute to centralized servers if they are uncertain locally or want to run more accurate, compute-intensive models. However, cloud robotics comes with a key, often understated cost: communicating with the cloud over congested wireless networks may result in latency or loss of data. In fact, sending high data-rate video or LIDAR from multiple robots over congested networks can lead to prohibitive delay for real-time applications, which we measure experimentally. In this paper, we formulate a novel Robot Offloading Problem --- how and when should robots offload sensing tasks, especially if they are uncertain, to improve accuracy while minimizing the cost of cloud communication? We formulate offloading as a sequential decision making problem for robots, and propose a solution using deep reinforcement learning. In both simulations and hardware experiments using state-of-the art vision DNNs, our offloading strategy improves vision task performance by between 1.3-2.6x of benchmark offloading strategies, allowing robots the potential to significantly transcend their on-board sensing accuracy but with limited cost of cloud communication.