 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonshine v2: Ergodic Streaming Encoder ASR for Latency-Critical Speech Applications
Feb 12, 2026Latency-critical speech applications (e.g., live transcription, voice commands, and real-time translation) demand low time-to-first-token (TTFT) and high transcription accuracy, particularly on resource-constrained edge devices. Full-attention Transformer encoders remain a strong accuracy baseline for automatic speech recognition (ASR) because every frame can directly attend to every other frame, which resolves otherwise locally ambiguous acoustics using distant lexical context. However, this global dependency incurs quadratic complexity in sequence length, inducing an inherent "encode-the-whole-utterance" latency profile. For streaming use cases, this causes TTFT to grow linearly with utterance length as the encoder must process the entire prefix before any decoder token can be emitted. To better meet the needs of on-device, streaming ASR use cases we introduce Moonshine v2, an ergodic streaming-encoder ASR model that employs sliding-window self-attention to achieve bounded, low-latency inference while preserving strong local context. Our models achieve state of the art word error rates across standard benchmarks, attaining accuracy on-par with models 6x their size while running significantly faster. These results demonstrate that carefully designed local attention is competitive with the accuracy of full attention at a fraction of the size and latency cost, opening new possibilities for interactive speech interfaces on edge devices.
Moonshine: Speech Recognition for Live Transcription and Voice Commands
Oct 21, 2024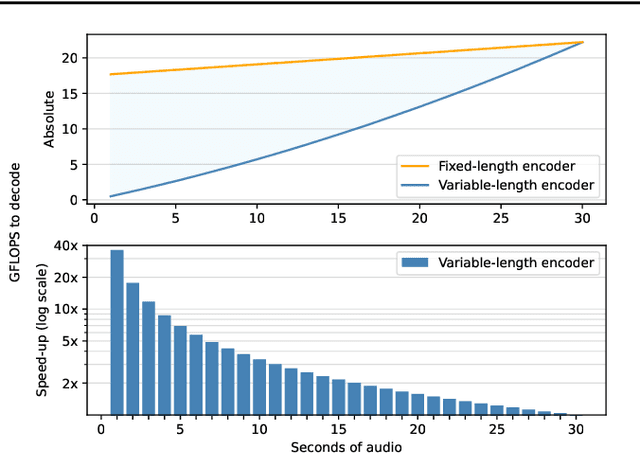
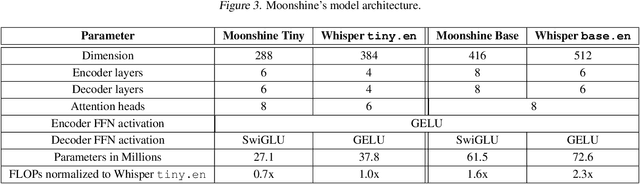
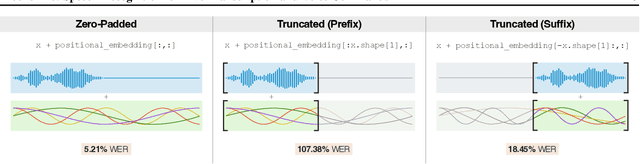
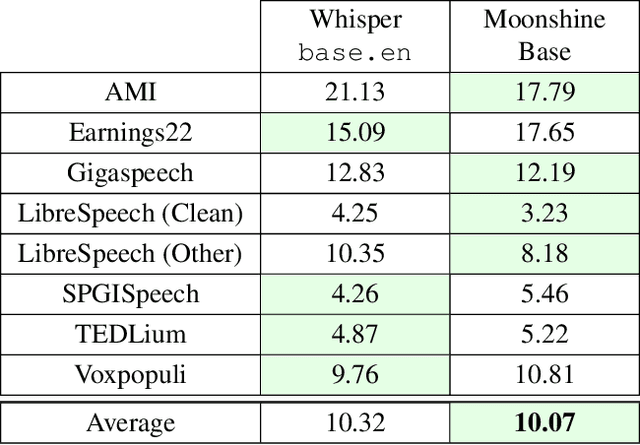
This paper introduces Moonshine, a family of speech recognition models optimized for live transcription and voice command processing. Moonshine is based on an encoder-decoder transformer architecture and employs Rotary Position Embedding (RoPE) instead of traditional absolute position embeddings. The model is trained on speech segments of various lengths, but without using zero-padding, leading to greater efficiency for the encoder during inference time. When benchmarked against OpenAI's Whisper tiny.en, Moonshine Tiny demonstrates a 5x reduction in compute requirements for transcribing a 10-second speech segment while incurring no increase in word error rates across standard evaluation datasets. These results highlight Moonshine's potential for real-time and resource-constrained applications.
Wake Vision: A Large-scale, Diverse Dataset and Benchmark Suite for TinyML Person Detection
May 01, 2024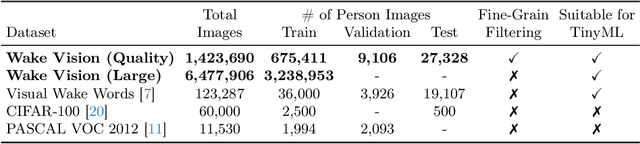



Machine learning applications on extremely low-power devices, commonly referred to as tiny machine learning (TinyML), promises a smarter and more connected world. However, the advancement of current TinyML research is hindered by the limited size and quality of pertinent datasets. To address this challenge, we introduce Wake Vision, a large-scale, diverse dataset tailored for person detection -- the canonical task for TinyML visual sensing. Wake Vision comprises over 6 million images, which is a hundredfold increase compared to the previous standard, and has undergone thorough quality filtering. Using Wake Vision for training results in a 2.41\% increase in accuracy compared to the established benchmark. Alongside the dataset, we provide a collection of five detailed benchmark sets that assess model performance on specific segments of the test data, such as varying lighting conditions, distances from the camera, and demographic characteristics of subjects. These novel fine-grained benchmarks facilitate the evaluation of model quality in challenging real-world scenarios that are often ignored when focusing solely on overall accuracy. Through an evaluation of a MobileNetV2 TinyML model on the benchmarks, we show that the input resolution plays a more crucial role than the model width in detecting distant subjects and that the impact of quantization on model robustness is minimal, thanks to the dataset quality. These findings underscore the importance of a detailed evaluation to identify essential factors for model development. The dataset, benchmark suite, code, and models are publicly available under the CC-BY 4.0 license, enabling their use for commercial use cases.
Datasheets for Machine Learning Sensors
Jun 15, 2023Machine learning (ML) sensors offer a new paradigm for sensing that enables intelligence at the edge while empowering end-users with greater control of their data. As these ML sensors play a crucial role in the development of intelligent devices, clear documentation of their specifications, functionalities, and limitations is pivotal. This paper introduces a standard datasheet template for ML sensors and discusses its essential components including: the system's hardware, ML model and dataset attributes, end-to-end performance metrics, and environmental impact. We provide an example datasheet for our own ML sensor and discuss each section in detail. We highlight how these datasheets can facilitate better understanding and utilization of sensor data in ML applications, and we provide objective measures upon which system performance can be evaluated and compared. Together, ML sensors and their datasheets provide greater privacy, security, transparency, explainability, auditability, and user-friendliness for ML-enabled embedded systems. We conclude by emphasizing the need for standardization of datasheets across the broader ML community to ensure the responsible and effective use of sensor data.
Is TinyML Sustainable? Assessing the Environmental Impacts of Machine Learning on Microcontrollers
Jan 27, 2023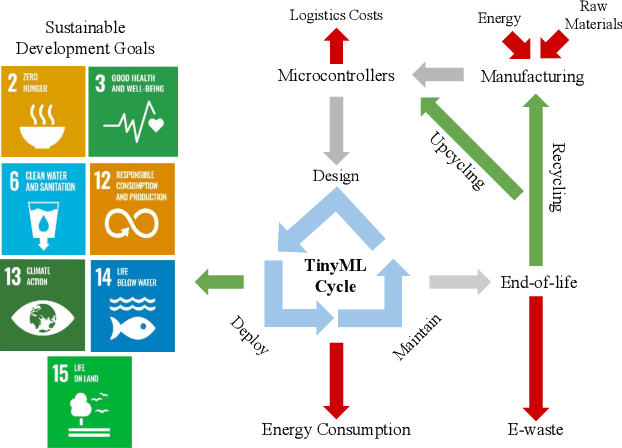
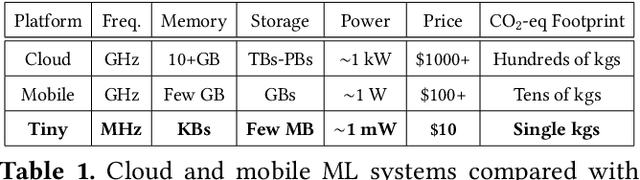
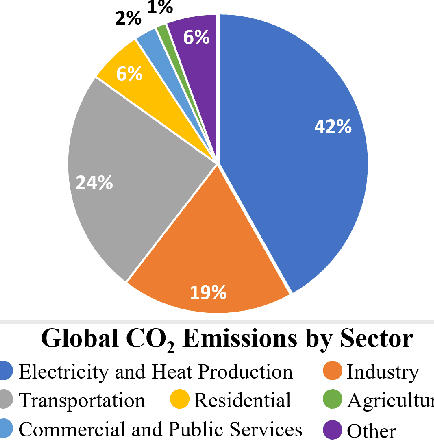
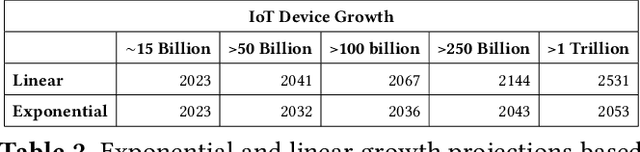
The sustained growth of carbon emissions and global waste elicits significant sustainability concerns for our environment's future. The growing Internet of Things (IoT) has the potential to exacerbate this issue. However, an emerging area known as Tiny Machine Learning (TinyML) has the opportunity to help address these environmental challenges through sustainable computing practices. TinyML, the deployment of machine learning (ML) algorithms onto low-cost, low-power microcontroller systems, enables on-device sensor analytics that unlocks numerous always-on ML applications. This article discusses the potential of these TinyML applications to address critical sustainability challenges. Moreover, the footprint of this emerging technology is assessed through a complete life cycle analysis of TinyML systems. From this analysis, TinyML presents opportunities to offset its carbon emissions by enabling applications that reduce the emissions of other sectors. Nevertheless, when globally scaled, the carbon footprint of TinyML systems is not negligible, necessitating that designers factor in environmental impact when formulating new devices. Finally, research directions for enabling further opportunities for TinyML to contribute to a sustainable future are outlined.
Machine Learning Sensors
Jun 07, 2022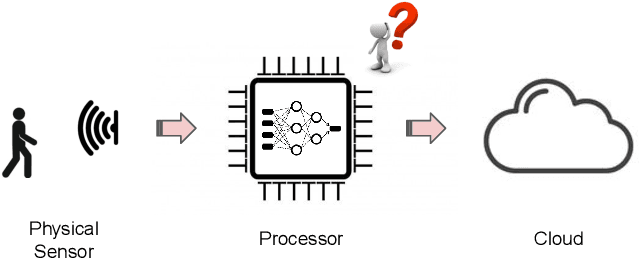
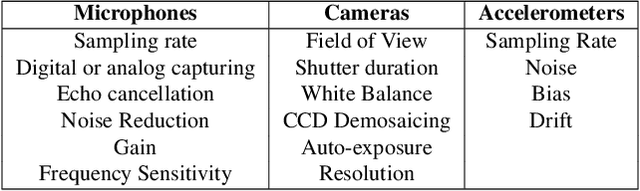
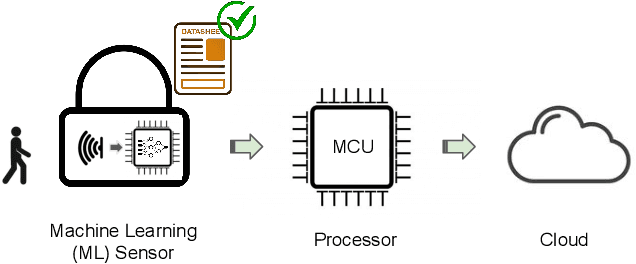
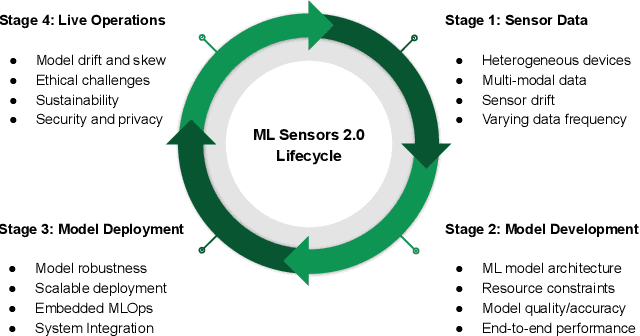
Machine learning sensors represent a paradigm shift for the future of embedded machine learning applications. Current instantiations of embedded machine learning (ML) suffer from complex integration, lack of modularity, and privacy and security concerns from data movement. This article proposes a more data-centric paradigm for embedding sensor intelligence on edge devices to combat these challenges. Our vision for "sensor 2.0" entails segregating sensor input data and ML processing from the wider system at the hardware level and providing a thin interface that mimics traditional sensors in functionality. This separation leads to a modular and easy-to-use ML sensor device. We discuss challenges presented by the standard approach of building ML processing into the software stack of the controlling microprocessor on an embedded system and how the modularity of ML sensors alleviates these problems. ML sensors increase privacy and accuracy while making it easier for system builders to integrate ML into their products as a simple component. We provide examples of prospective ML sensors and an illustrative datasheet as a demonstration and hope that this will build a dialogue to progress us towards sensor 2.0.
CFU Playground: Full-Stack Open-Source Framework for Tiny Machine Learning (tinyML) Acceleration on FPGAs
Jan 05, 2022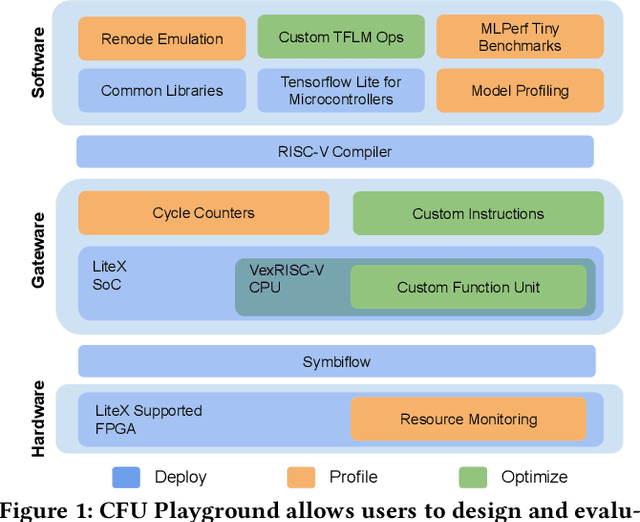
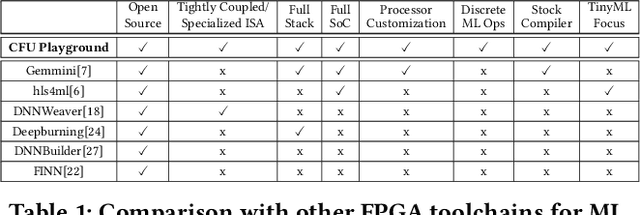
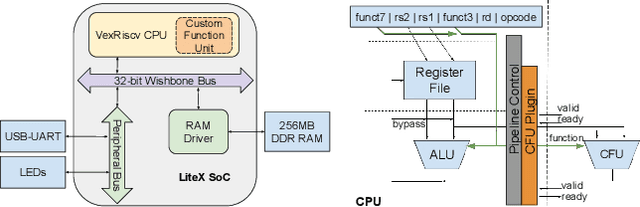
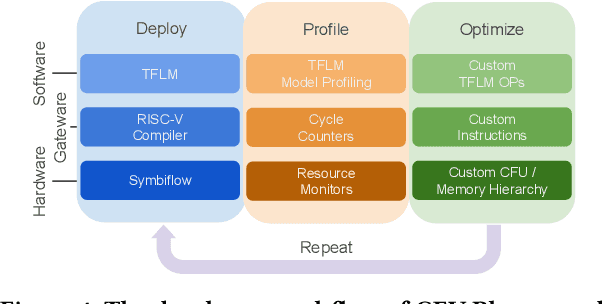
We present CFU Playground, a full-stack open-source framework that enables rapid and iterative design of machine learning (ML) accelerators for embedded ML systems. Our toolchain tightly integrates open-source software, RTL generators, and FPGA tools for synthesis, place, and route. This full-stack development framework gives engineers access to explore bespoke architectures that are customized and co-optimized for embedded ML. The rapid, deploy-profile-optimization feedback loop lets ML hardware and software developers achieve significant returns out of a relatively small investment in customization. Using CFU Playground's design loop, we show substantial speedups (55x-75x) and design space exploration between the CPU and accelerator.
ML-EXray: Visibility into ML Deployment on the Edge
Nov 08, 2021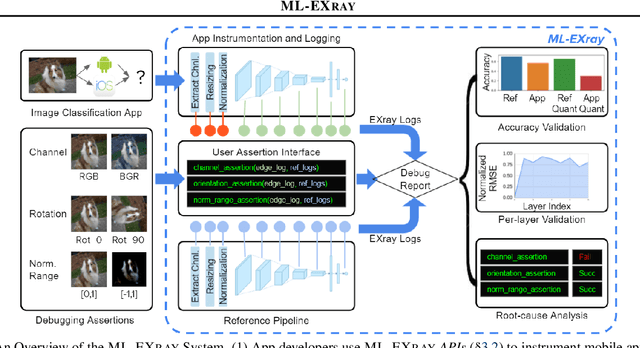
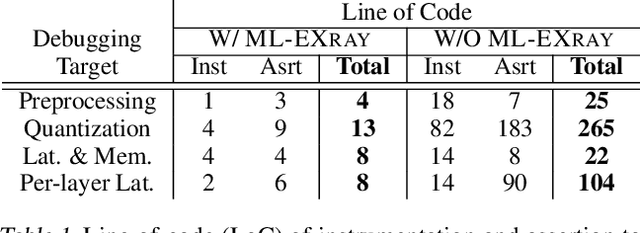
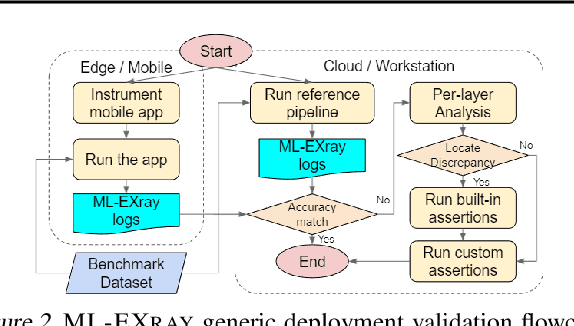
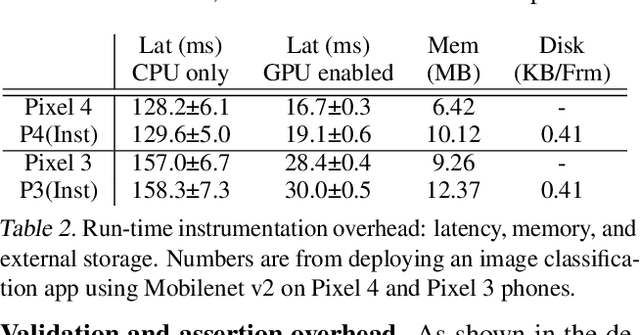
Benefiting from expanding cloud infrastructure, deep neural networks (DNNs) today have increasingly high performance when trained in the cloud. Researchers spend months of effort competing for an extra few percentage points of model accuracy. However, when these models are actually deployed on edge devices in practice, very often, the performance can abruptly drop over 10% without obvious reasons. The key challenge is that there is not much visibility into ML inference execution on edge devices, and very little awareness of potential issues during the edge deployment process. We present ML-EXray, an end-to-end framework, which provides visibility into layer-level details of the ML execution, and helps developers analyze and debug cloud-to-edge deployment issues. More often than not, the reason for sub-optimal edge performance does not only lie in the model itself, but every operation throughout the data flow and the deployment process. Evaluations show that ML-EXray can effectively catch deployment issues, such as pre-processing bugs, quantization issues, suboptimal kernels, etc. Using ML-EXray, users need to write less than 15 lines of code to fully examine the edge deployment pipeline. Eradicating these issues, ML-EXray can correct model performance by up to 30%, pinpoint error-prone layers, and guide users to optimize kernel execution latency by two orders of magnitude. Code and APIs will be released as an open-source multi-lingual instrumentation library and a Python deployment validation library.
Widening Access to Applied Machine Learning with TinyML
Jun 09, 2021
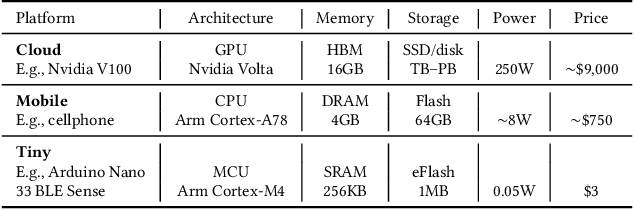

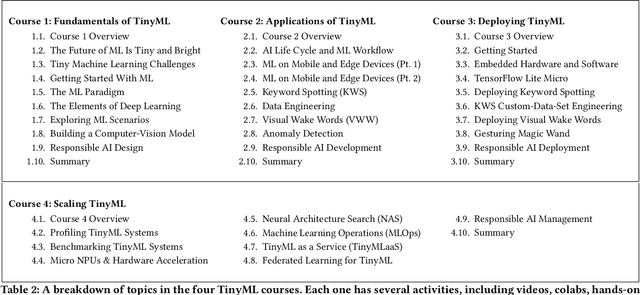
Broadening access to both computational and educational resources is critical to diffusing machine-learning (ML) innovation. However, today, most ML resources and experts are siloed in a few countries and organizations. In this paper, we describe our pedagogical approach to increasing access to applied ML through a massive open online course (MOOC) on Tiny Machine Learning (TinyML). We suggest that TinyML, ML on resource-constrained embedded devices, is an attractive means to widen access because TinyML both leverages low-cost and globally accessible hardware, and encourages the development of complete, self-contained applications, from data collection to deployment. To this end, a collaboration between academia (Harvard University) and industry (Google) produced a four-part MOOC that provides application-oriented instruction on how to develop solutions using TinyML. The series is openly available on the edX MOOC platform, has no prerequisites beyond basic programming, and is designed for learners from a global variety of backgrounds. It introduces pupils to real-world applications, ML algorithms, data-set engineering, and the ethical considerations of these technologies via hands-on programming and deployment of TinyML applications in both the cloud and their own microcontrollers. To facilitate continued learning, community building, and collaboration beyond the courses, we launched a standalone website, a forum, a chat, and an optional course-project competition. We also released the course materials publicly, hoping they will inspire the next generation of ML practitioners and educators and further broaden access to cutting-edge ML technologies.
Few-Shot Keyword Spotting in Any Language
Apr 22, 2021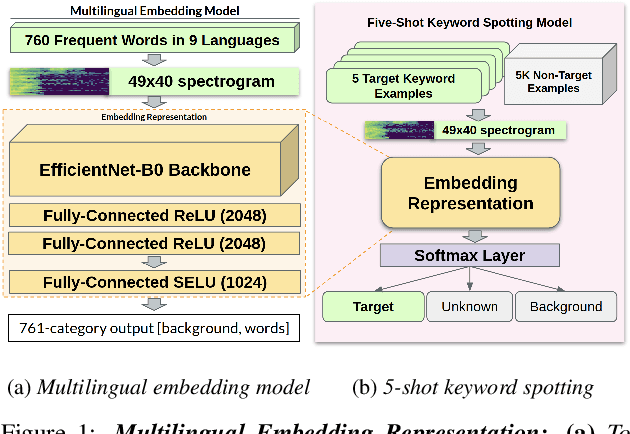

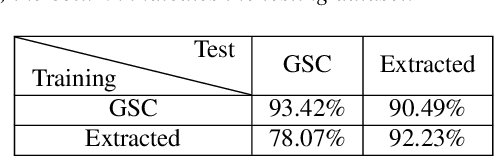
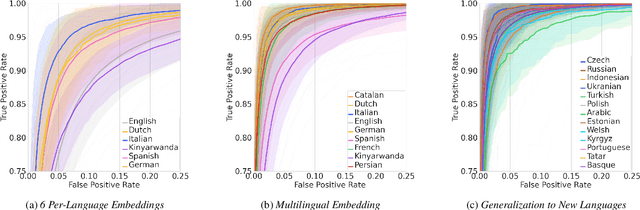
We introduce a few-shot transfer learning method for keyword spotting in any language. Leveraging open speech corpora in nine languages, we automate the extraction of a large multilingual keyword bank and use it to train an embedding model. With just five training examples, we fine-tune the embedding model for keyword spotting and achieve an average F1 score of 0.75 on keyword classification for 180 new keywords unseen by the embedding model in these nine languages. This embedding model also generalizes to new languages. We achieve an average F1 score of 0.65 on 5-shot models for 260 keywords sampled across 13 new languages unseen by the embedding model. We investigate streaming accuracy for our 5-shot models in two contexts: keyword spotting and keyword search. Across 440 keywords in 22 languages, we achieve an average streaming keyword spotting accuracy of 85.2% with a false acceptance rate of 1.2%, and observe promising initial results on keyword search.