 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonshine: Speech Recognition for Live Transcription and Voice Commands
Oct 21, 2024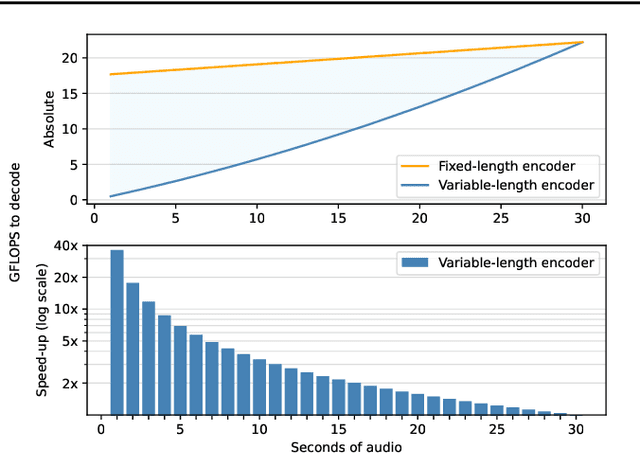
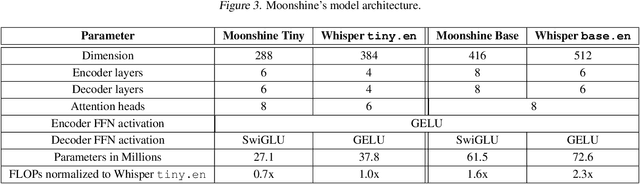
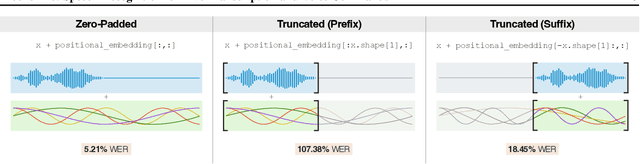
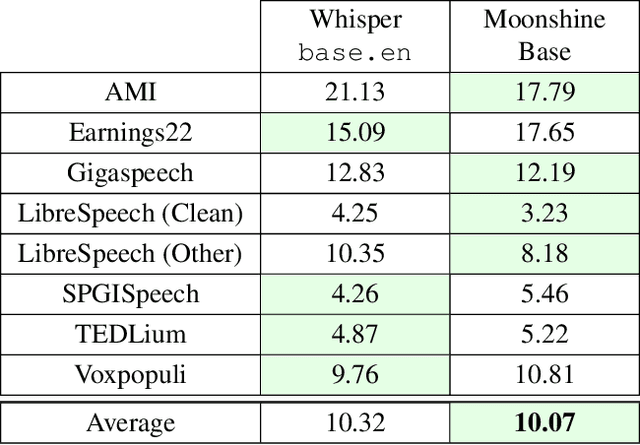
This paper introduces Moonshine, a family of speech recognition models optimized for live transcription and voice command processing. Moonshine is based on an encoder-decoder transformer architecture and employs Rotary Position Embedding (RoPE) instead of traditional absolute position embeddings. The model is trained on speech segments of various lengths, but without using zero-padding, leading to greater efficiency for the encoder during inference time. When benchmarked against OpenAI's Whisper tiny.en, Moonshine Tiny demonstrates a 5x reduction in compute requirements for transcribing a 10-second speech segment while incurring no increase in word error rates across standard evaluation datasets. These results highlight Moonshine's potential for real-time and resource-constrained applications.
Wake Vision: A Large-scale, Diverse Dataset and Benchmark Suite for TinyML Person Detection
May 01, 2024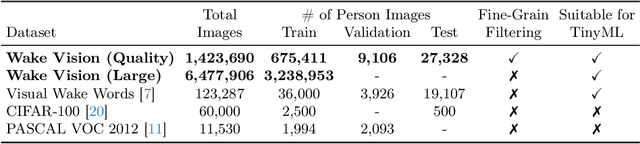



Machine learning applications on extremely low-power devices, commonly referred to as tiny machine learning (TinyML), promises a smarter and more connected world. However, the advancement of current TinyML research is hindered by the limited size and quality of pertinent datasets. To address this challenge, we introduce Wake Vision, a large-scale, diverse dataset tailored for person detection -- the canonical task for TinyML visual sensing. Wake Vision comprises over 6 million images, which is a hundredfold increase compared to the previous standard, and has undergone thorough quality filtering. Using Wake Vision for training results in a 2.41\% increase in accuracy compared to the established benchmark. Alongside the dataset, we provide a collection of five detailed benchmark sets that assess model performance on specific segments of the test data, such as varying lighting conditions, distances from the camera, and demographic characteristics of subjects. These novel fine-grained benchmarks facilitate the evaluation of model quality in challenging real-world scenarios that are often ignored when focusing solely on overall accuracy. Through an evaluation of a MobileNetV2 TinyML model on the benchmarks, we show that the input resolution plays a more crucial role than the model width in detecting distant subjects and that the impact of quantization on model robustness is minimal, thanks to the dataset quality. These findings underscore the importance of a detailed evaluation to identify essential factors for model development. The dataset, benchmark suite, code, and models are publicly available under the CC-BY 4.0 license, enabling their use for commercial use cases.
Dynamic Control Flow in Large-Scale Machine Learning
May 04, 2018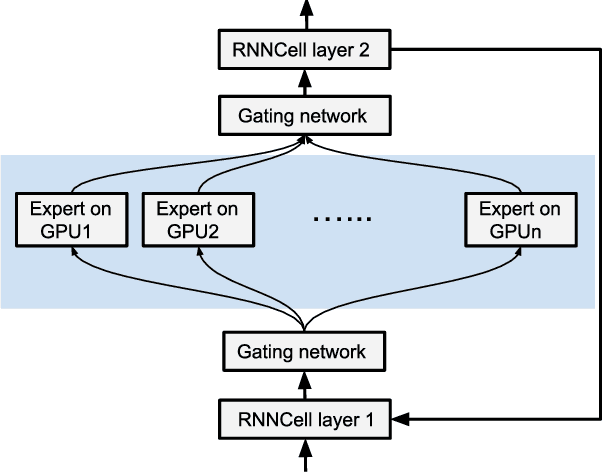

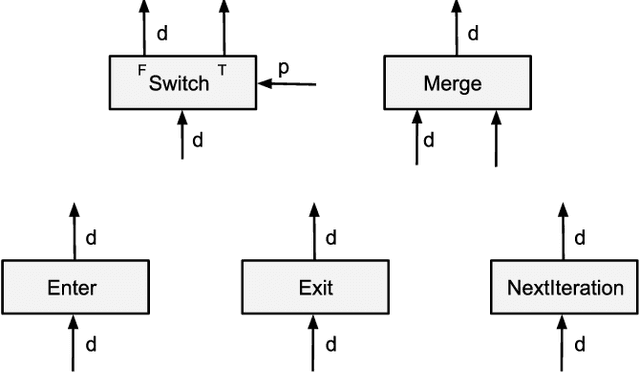
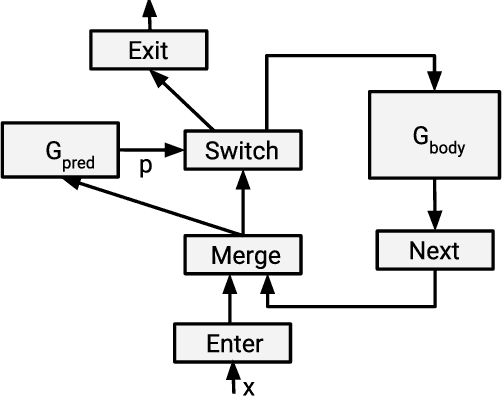
Many recent machine learning models rely on fine-grained dynamic control flow for training and inference. In particular, models based on recurrent neural networks and on reinforcement learning depend on recurrence relations, data-dependent conditional execution, and other features that call for dynamic control flow. These applications benefit from the ability to make rapid control-flow decisions across a set of computing devices in a distributed system. For performance, scalability, and expressiveness, a machine learning system must support dynamic control flow in distributed and heterogeneous environments. This paper presents a programming model for distributed machine learning that supports dynamic control flow. We describe the design of the programming model, and its implementation in TensorFlow, a distributed machine learning system. Our approach extends the use of dataflow graphs to represent machine learning models, offering several distinctive features. First, the branches of conditionals and bodies of loops can be partitioned across many machines to run on a set of heterogeneous devices, including CPUs, GPUs, and custom ASICs. Second, programs written in our model support automatic differentiation and distributed gradient computations, which are necessary for training machine learning models that use control flow. Third, our choice of non-strict semantics enables multiple loop iterations to execute in parallel across machines, and to overlap compute and I/O operations. We have done our work in the context of TensorFlow, and it has been used extensively in research and production. We evaluate it using several real-world applications, and demonstrate its performance and scalability.
* Appeared in EuroSys 2018. 14 pages, 16 figures
Exploring the structure of a real-time, arbitrary neural artistic stylization network
Aug 24, 2017



In this paper, we present a method which combines the flexibility of the neural algorithm of artistic style with the speed of fast style transfer networks to allow real-time stylization using any content/style image pair. We build upon recent work leveraging conditional instance normalization for multi-style transfer networks by learning to predict the conditional instance normalization parameters directly from a style image. The model is successfully trained on a corpus of roughly 80,000 paintings and is able to generalize to paintings previously unobserved. We demonstrate that the learned embedding space is smooth and contains a rich structure and organizes semantic information associated with paintings in an entirely unsupervised manner.
A Learned Representation For Artistic Style
Feb 09, 2017

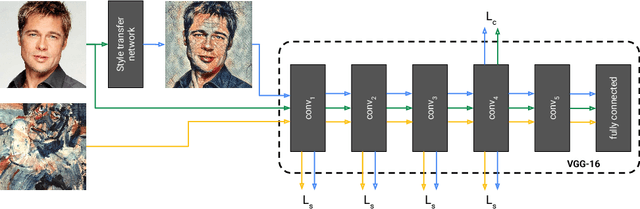
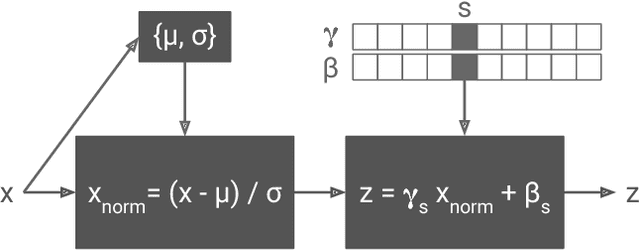
The diversity of painting styles represents a rich visual vocabulary for the construction of an image. The degree to which one may learn and parsimoniously capture this visual vocabulary measures our understanding of the higher level features of paintings, if not images in general. In this work we investigate the construction of a single, scalable deep network that can parsimoniously capture the artistic style of a diversity of paintings. We demonstrate that such a network generalizes across a diversity of artistic styles by reducing a painting to a point in an embedding space. Importantly, this model permits a user to explore new painting styles by arbitrarily combining the styles learned from individual paintings. We hope that this work provides a useful step towards building rich models of paintings and offers a window on to the structure of the learned representation of artistic style.
TensorFlow: A system for large-scale machine learning
May 31, 2016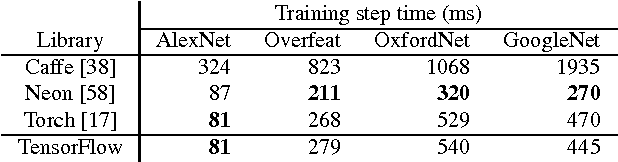

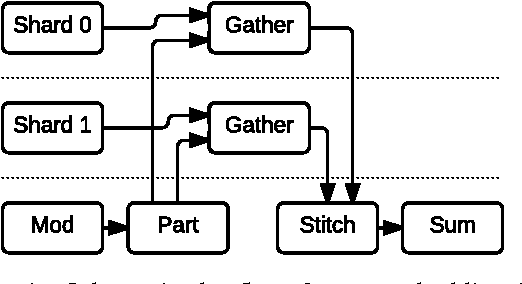
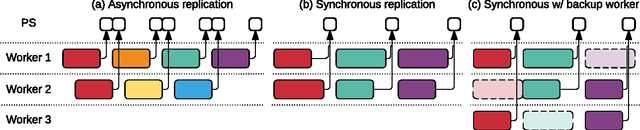
TensorFlow is a machine learning system that operates at large scale and in heterogeneous environments. TensorFlow uses dataflow graphs to represent computation, shared state, and the operations that mutate that state. It maps the nodes of a dataflow graph across many machines in a cluster, and within a machine across multiple computational devices, including multicore CPUs, general-purpose GPUs, and custom designed ASICs known as Tensor Processing Units (TPUs). This architecture gives flexibility to the application developer: whereas in previous "parameter server" designs the management of shared state is built into the system, TensorFlow enables developers to experiment with novel optimizations and training algorithms. TensorFlow supports a variety of applications, with particularly strong support for training and inference on deep neural networks. Several Google services use TensorFlow in production, we have released it as an open-source project, and it has become widely used for machine learning research. In this paper, we describe the TensorFlow dataflow model in contrast to existing systems, and demonstrate the compelling performance that TensorFlow achieves for several real-world applications.
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016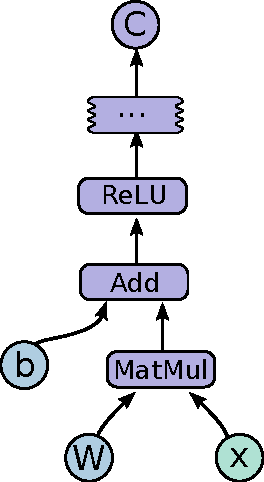

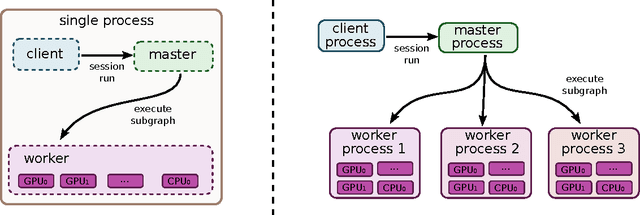
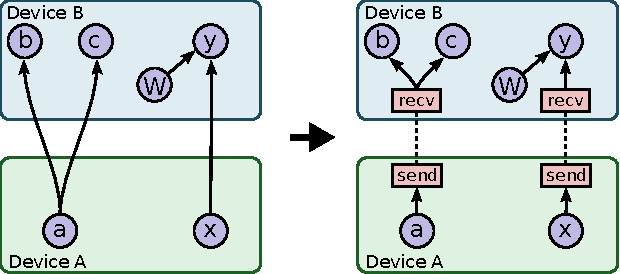
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.
Order Matters: Sequence to sequence for sets
Feb 23, 2016



Sequences have become first class citizens in supervised learning thanks to the resurgence of recurrent neural networks. Many complex tasks that require mapping from or to a sequence of observations can now be formulated with the sequence-to-sequence (seq2seq) framework which employs the chain rule to efficiently represent the joint probability of sequences. In many cases, however, variable sized inputs and/or outputs might not be naturally expressed as sequences. For instance, it is not clear how to input a set of numbers into a model where the task is to sort them; similarly, we do not know how to organize outputs when they correspond to random variables and the task is to model their unknown joint probability. In this paper, we first show using various examples that the order in which we organize input and/or output data matters significantly when learning an underlying model. We then discuss an extension of the seq2seq framework that goes beyond sequences and handles input sets in a principled way. In addition, we propose a loss which, by searching over possible orders during training, deals with the lack of structure of output sets. We show empirical evidence of our claims regarding ordering, and on the modifications to the seq2seq framework on benchmark language modeling and parsing tasks, as well as two artificial tasks -- sorting numbers and estimating the joint probability of unknown graphical models.