 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonshine v2: Ergodic Streaming Encoder ASR for Latency-Critical Speech Applications
Feb 12, 2026Latency-critical speech applications (e.g., live transcription, voice commands, and real-time translation) demand low time-to-first-token (TTFT) and high transcription accuracy, particularly on resource-constrained edge devices. Full-attention Transformer encoders remain a strong accuracy baseline for automatic speech recognition (ASR) because every frame can directly attend to every other frame, which resolves otherwise locally ambiguous acoustics using distant lexical context. However, this global dependency incurs quadratic complexity in sequence length, inducing an inherent "encode-the-whole-utterance" latency profile. For streaming use cases, this causes TTFT to grow linearly with utterance length as the encoder must process the entire prefix before any decoder token can be emitted. To better meet the needs of on-device, streaming ASR use cases we introduce Moonshine v2, an ergodic streaming-encoder ASR model that employs sliding-window self-attention to achieve bounded, low-latency inference while preserving strong local context. Our models achieve state of the art word error rates across standard benchmarks, attaining accuracy on-par with models 6x their size while running significantly faster. These results demonstrate that carefully designed local attention is competitive with the accuracy of full attention at a fraction of the size and latency cost, opening new possibilities for interactive speech interfaces on edge devices.
Moonshine: Speech Recognition for Live Transcription and Voice Commands
Oct 21, 2024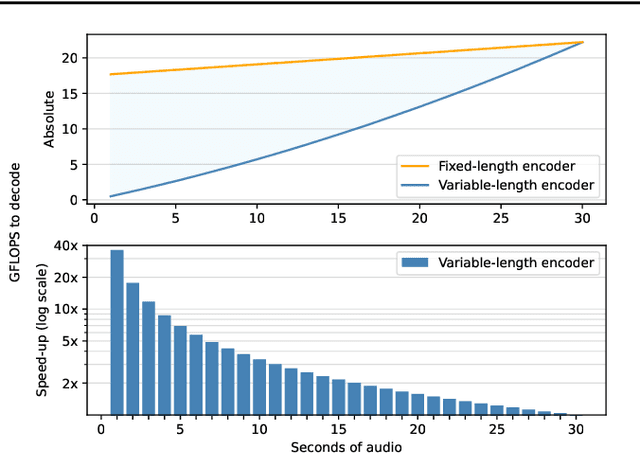
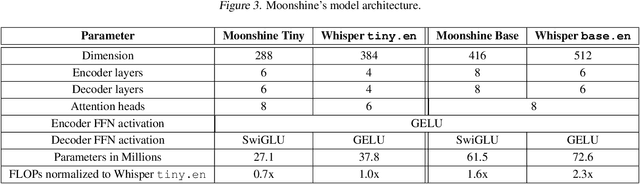
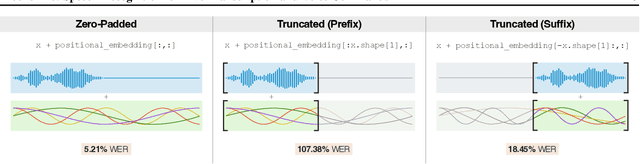
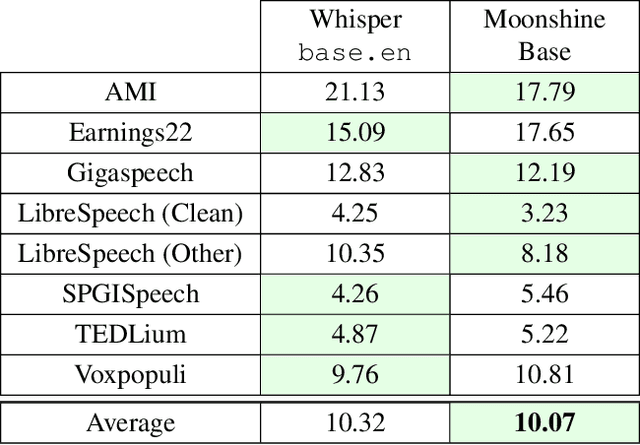
This paper introduces Moonshine, a family of speech recognition models optimized for live transcription and voice command processing. Moonshine is based on an encoder-decoder transformer architecture and employs Rotary Position Embedding (RoPE) instead of traditional absolute position embeddings. The model is trained on speech segments of various lengths, but without using zero-padding, leading to greater efficiency for the encoder during inference time. When benchmarked against OpenAI's Whisper tiny.en, Moonshine Tiny demonstrates a 5x reduction in compute requirements for transcribing a 10-second speech segment while incurring no increase in word error rates across standard evaluation datasets. These results highlight Moonshine's potential for real-time and resource-constrained applications.
Thoughtful Things: Building Human-Centric Smart Devices with Small Language Models
May 06, 2024



Everyday devices like light bulbs and kitchen appliances are now embedded with so many features and automated behaviors that they have become complicated to actually use. While such "smart" capabilities can better support users' goals, the task of learning the "ins and outs" of different devices is daunting. Voice assistants aim to solve this problem by providing a natural language interface to devices, yet such assistants cannot understand loosely-constrained commands, they lack the ability to reason about and explain devices' behaviors to users, and they rely on connectivity to intrusive cloud infrastructure. Toward addressing these issues, we propose thoughtful things: devices that leverage lightweight, on-device language models to take actions and explain their behaviors in response to unconstrained user commands. We propose an end-to-end framework that leverages formal modeling, automated training data synthesis, and generative language models to create devices that are both capable and thoughtful in the presence of unconstrained user goals and inquiries. Our framework requires no labeled data and can be deployed on-device, with no cloud dependency. We implement two thoughtful things (a lamp and a thermostat) and deploy them on real hardware, evaluating their practical performance.
Cheating off your neighbors: Improving activity recognition through corroboration
May 27, 2023Understanding the complexity of human activities solely through an individual's data can be challenging. However, in many situations, surrounding individuals are likely performing similar activities, while existing human activity recognition approaches focus almost exclusively on individual measurements and largely ignore the context of the activity. Consider two activities: attending a small group meeting and working at an office desk. From solely an individual's perspective, it can be difficult to differentiate between these activities as they may appear very similar, even though they are markedly different. Yet, by observing others nearby, it can be possible to distinguish between these activities. In this paper, we propose an approach to enhance the prediction accuracy of an individual's activities by incorporating insights from surrounding individuals. We have collected a real-world dataset from 20 participants with over 58 hours of data including activities such as attending lectures, having meetings, working in the office, and eating together. Compared to observing a single person in isolation, our proposed approach significantly improves accuracy. We regard this work as a first step in collaborative activity recognition, opening new possibilities for understanding human activity in group settings.
Sasha: creative goal-oriented reasoning in smart homes with large language models
May 16, 2023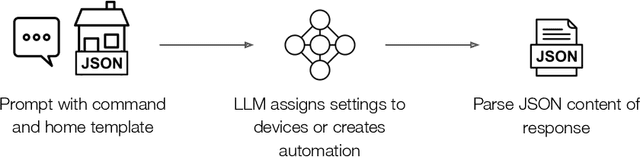
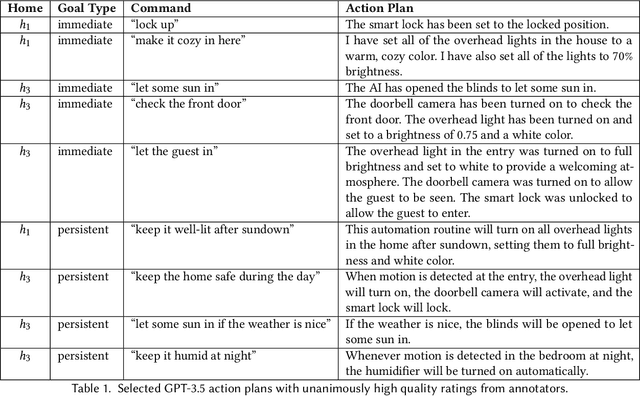

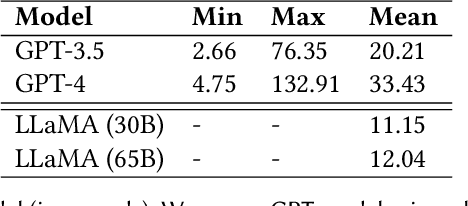
Every smart home user interaction has an explicit or implicit goal. Existing home assistants easily achieve explicit goals, e.g., "turn on the light". In more natural communication, however, humans tend to describe implicit goals. We can, for example, ask someone to "make it cozy" rather than describe the specific steps involved. Current systems struggle with this ambiguity since it requires them to relate vague intent to specific devices. We approach this problem of flexibly achieving user goals from the perspective of general-purpose large language models (LLMs) trained on gigantic corpora and adapted to downstream tasks with remarkable flexibility. We explore the use of LLMs for controlling devices and creating automation routines to meet the implicit goals of user commands. In a user-focused study, we find that LLMs can reason creatively to achieve challenging goals, while also revealing gaps that diminish their usefulness. We address these gaps with Sasha: a system for creative, goal-oriented reasoning in smart homes. Sasha responds to commands like "make it cozy" or "help me sleep better" by executing plans to achieve user goals, e.g., setting a mood with available devices, or devising automation routines. We demonstrate Sasha in a real smart home.
"Get ready for a party": Exploring smarter smart spaces with help from large language models
Mar 24, 2023


The right response to someone who says "get ready for a party" is deeply influenced by meaning and context. For a smart home assistant (e.g., Google Home), the ideal response might be to survey the available devices in the home and change their state to create a festive atmosphere. Current practical systems cannot service such requests since they require the ability to (1) infer meaning behind an abstract statement and (2) map that inference to a concrete course of action appropriate for the context (e.g., changing the settings of specific devices). In this paper, we leverage the observation that recent task-agnostic large language models (LLMs) like GPT-3 embody a vast amount of cross-domain, sometimes unpredictable contextual knowledge that existing rule-based home assistant systems lack, which can make them powerful tools for inferring user intent and generating appropriate context-dependent responses during smart home interactions. We first explore the feasibility of a system that places an LLM at the center of command inference and action planning, showing that LLMs have the capacity to infer intent behind vague, context-dependent commands like "get ready for a party" and respond with concrete, machine-parseable instructions that can be used to control smart devices. We furthermore demonstrate a proof-of-concept implementation that puts an LLM in control of real devices, showing its ability to infer intent and change device state appropriately with no fine-tuning or task-specific training. Our work hints at the promise of LLM-driven systems for context-awareness in smart environments, motivating future research in this area.