 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Migration-Assisted Deep Learning Scheme for Imaging Defects Inside Cylindrical Structures via GPR: A Case Study for Tree Trunks
Feb 05, 2026Ground-penetrating radar (GPR) has emerged as a prominent tool for imaging internal defects in cylindrical structures, such as columns, utility poles, and tree trunks. However, accurately reconstructing both the shape and permittivity of the defects inside cylindrical structures remains challenging due to complex wave scattering phenomena and the limited accuracy of the existing signal processing and deep learning techniques. To address these issues, this study proposes a migration-assisted deep learning scheme for reconstructing the shape and permittivity of defects within cylindrical structures. The proposed scheme involves three stages of GPR data processing. First, a dual-permittivity estimation network extracts the permittivity values of the defect and the cylindrical structure, the latter of which is estimated with the help of a novel structural similarity index measure-based autofocusing technique. Second, a modified Kirchhoff migration incorporating the extracted permittivity of the cylindrical structure maps the signals reflected from the defect to the imaging domain. Third, a shape reconstruction network processes the migrated image to recover the precise shape of the defect. The image of the interior defect is finally obtained by combining the reconstructed shape and extracted permittivity of the defect. The proposed scheme is validated using both synthetic and experimental data from a laboratory trunk model and real tree trunk samples. Comparative results show superior performance over existing deep learning methods, while generalization tests on live trees confirm its feasibility for in-field deployment. The underlying principle can further be applied to other circumferential GPR imaging scenarios. The code and database are available at: https://github.com/jwqian54/Migration-Assisted-DL.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Synthetic CT Generation from Time-of-Flight Non-Attenutaion-Corrected PET for Whole-Body PET Attenuation Correction
Apr 10, 2025Positron Emission Tomography (PET) imaging requires accurate attenuation correction (AC) to account for photon loss due to tissue density variations. In PET/MR systems, computed tomography (CT), which offers a straightforward estimation of AC is not available. This study presents a deep learning approach to generate synthetic CT (sCT) images directly from Time-of-Flight (TOF) non-attenuation corrected (NAC) PET images, enhancing AC for PET/MR. We first evaluated models pre-trained on large-scale natural image datasets for a CT-to-CT reconstruction task, finding that the pre-trained model outperformed those trained solely on medical datasets. The pre-trained model was then fine-tuned using an institutional dataset of 35 TOF NAC PET and CT volume pairs, achieving the lowest mean absolute error (MAE) of 74.49 HU and highest peak signal-to-noise ratio (PSNR) of 28.66 dB within the body contour region. Visual assessments demonstrated improved reconstruction of both bone and soft tissue structures from TOF NAC PET images. This work highlights the effectiveness of using pre-trained deep learning models for medical image translation tasks. Future work will assess the impact of sCT on PET attenuation correction and explore additional neural network architectures and datasets to further enhance performance and practical applications in PET imaging.
Logarithmic Regret for Nonlinear Control
Jan 17, 2025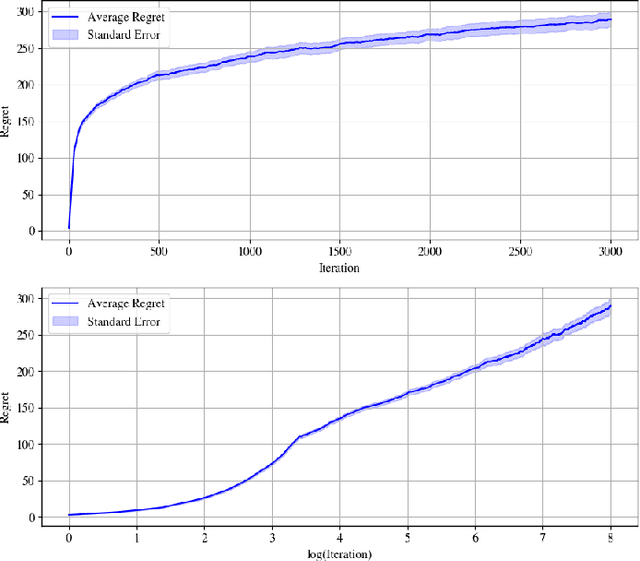
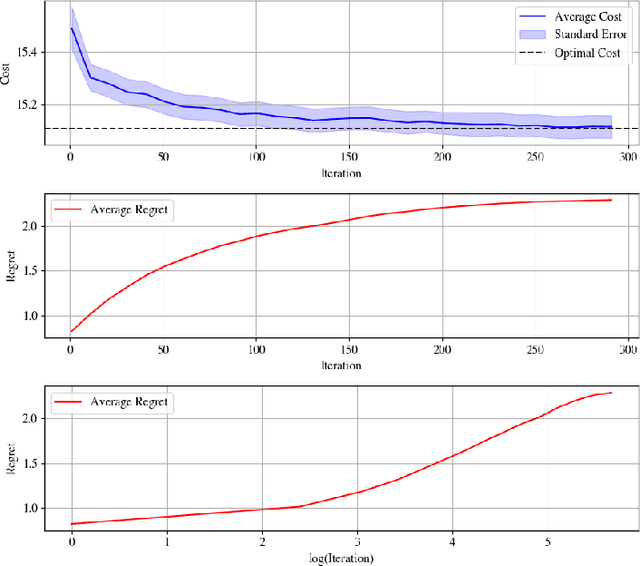
We address the problem of learning to control an unknown nonlinear dynamical system through sequential interactions. Motivated by high-stakes applications in which mistakes can be catastrophic, such as robotics and healthcare, we study situations where it is possible for fast sequential learning to occur. Fast sequential learning is characterized by the ability of the learning agent to incur logarithmic regret relative to a fully-informed baseline. We demonstrate that fast sequential learning is achievable in a diverse class of continuous control problems where the system dynamics depend smoothly on unknown parameters, provided the optimal control policy is persistently exciting. Additionally, we derive a regret bound which grows with the square root of the number of interactions for cases where the optimal policy is not persistently exciting. Our results provide the first regret bounds for controlling nonlinear dynamical systems depending nonlinearly on unknown parameters. We validate the trends our theory predicts in simulation on a simple dynamical system.
Moonshine: Speech Recognition for Live Transcription and Voice Commands
Oct 21, 2024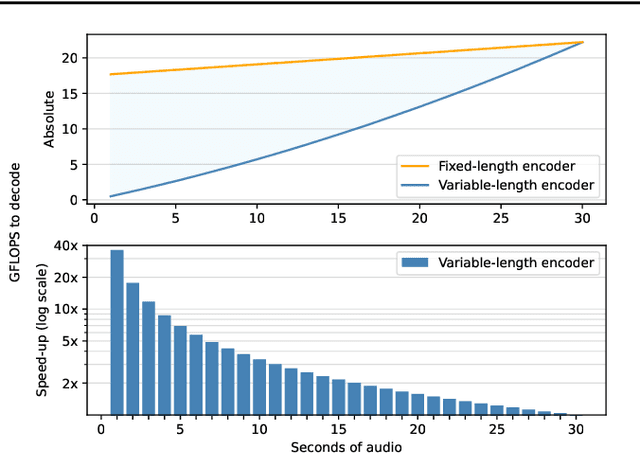
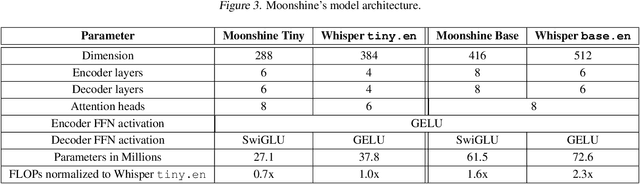
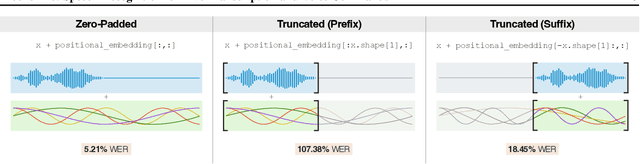
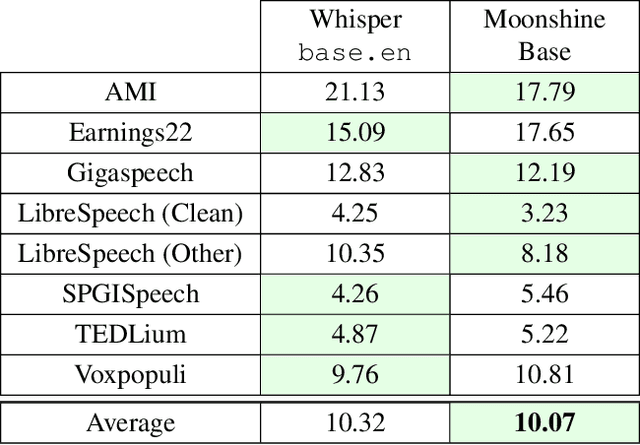
This paper introduces Moonshine, a family of speech recognition models optimized for live transcription and voice command processing. Moonshine is based on an encoder-decoder transformer architecture and employs Rotary Position Embedding (RoPE) instead of traditional absolute position embeddings. The model is trained on speech segments of various lengths, but without using zero-padding, leading to greater efficiency for the encoder during inference time. When benchmarked against OpenAI's Whisper tiny.en, Moonshine Tiny demonstrates a 5x reduction in compute requirements for transcribing a 10-second speech segment while incurring no increase in word error rates across standard evaluation datasets. These results highlight Moonshine's potential for real-time and resource-constrained applications.
RAFT: Realistic Attacks to Fool Text Detectors
Oct 04, 2024



Large language models (LLMs) have exhibited remarkable fluency across various tasks. However, their unethical applications, such as disseminating disinformation, have become a growing concern. Although recent works have proposed a number of LLM detection methods, their robustness and reliability remain unclear. In this paper, we present RAFT: a grammar error-free black-box attack against existing LLM detectors. In contrast to previous attacks for language models, our method exploits the transferability of LLM embeddings at the word-level while preserving the original text quality. We leverage an auxiliary embedding to greedily select candidate words to perturb against the target detector. Experiments reveal that our attack effectively compromises all detectors in the study across various domains by up to 99%, and are transferable across source models. Manual human evaluation studies show our attacks are realistic and indistinguishable from original human-written text. We also show that examples generated by RAFT can be used to train adversarially robust detectors. Our work shows that current LLM detectors are not adversarially robust, underscoring the urgent need for more resilient detection mechanisms.
MUG: Multi-human Graph Network for 3D Mesh Reconstruction from 2D Pose
May 25, 2022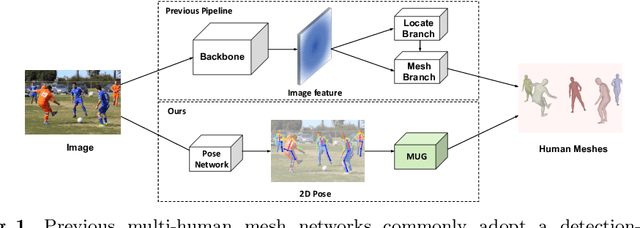
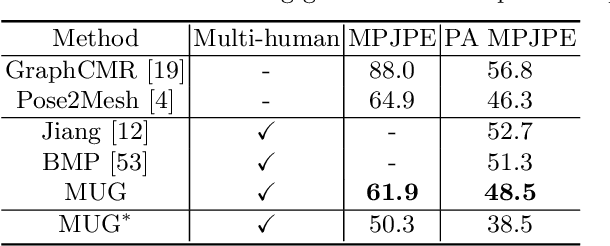
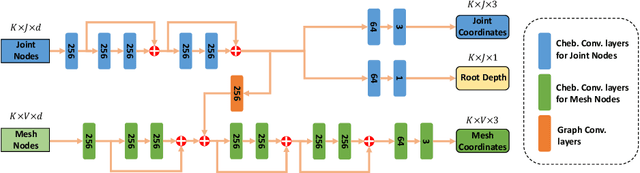
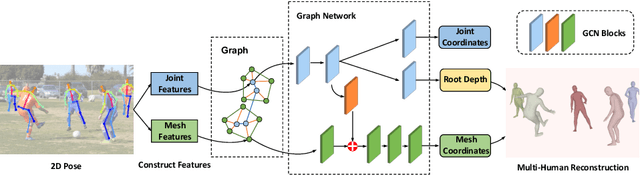
Reconstructing multi-human body mesh from a single monocular image is an important but challenging computer vision problem. In addition to the individual body mesh models, we need to estimate relative 3D positions among subjects to generate a coherent representation. In this work, through a single graph neural network, named MUG (Multi-hUman Graph network), we construct coherent multi-human meshes using only multi-human 2D pose as input. Compared with existing methods, which adopt a detection-style pipeline (i.e., extracting image features and then locating human instances and recovering body meshes from that) and suffer from the significant domain gap between lab-collected training datasets and in-the-wild testing datasets, our method benefits from the 2D pose which has a relatively consistent geometric property across datasets. Our method works like the following: First, to model the multi-human environment, it processes multi-human 2D poses and builds a novel heterogeneous graph, where nodes from different people and within one person are connected to capture inter-human interactions and draw the body geometry (i.e., skeleton and mesh structure). Second, it employs a dual-branch graph neural network structure -- one for predicting inter-human depth relation and the other one for predicting root-joint-relative mesh coordinates. Finally, the entire multi-human 3D meshes are constructed by combining the output from both branches. Extensive experiments demonstrate that MUG outperforms previous multi-human mesh estimation methods on standard 3D human benchmarks -- Panoptic, MuPoTS-3D and 3DPW.
Causal Transportability for Visual Recognition
Apr 26, 2022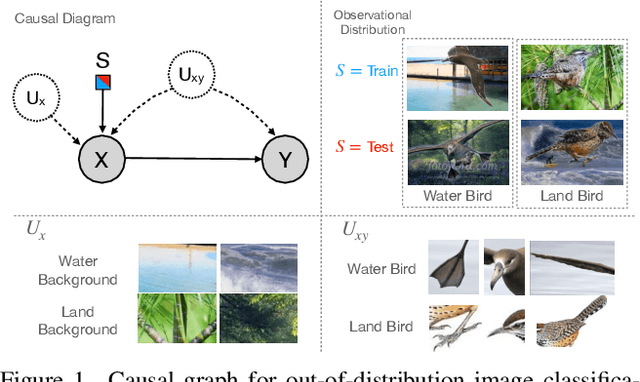
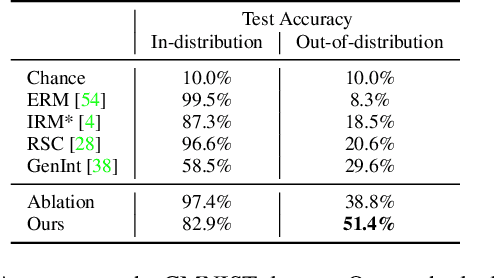
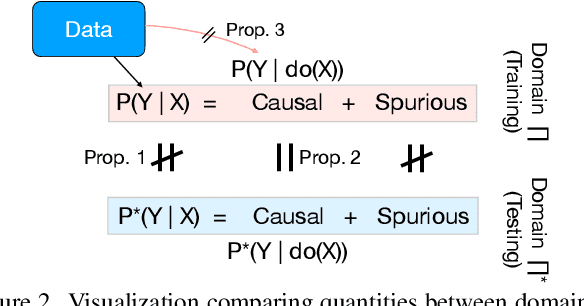
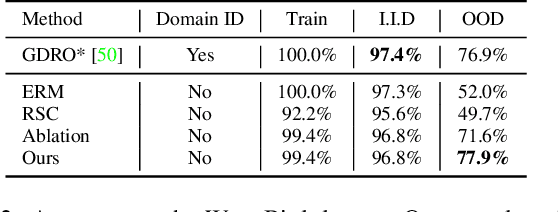
Visual representations underlie object recognition tasks, but they often contain both robust and non-robust features. Our main observation is that image classifiers may perform poorly on out-of-distribution samples because spurious correlations between non-robust features and labels can be changed in a new environment. By analyzing procedures for out-of-distribution generalization with a causal graph, we show that standard classifiers fail because the association between images and labels is not transportable across settings. However, we then show that the causal effect, which severs all sources of confounding, remains invariant across domains. This motivates us to develop an algorithm to estimate the causal effect for image classification, which is transportable (i.e., invariant) across source and target environments. Without observing additional variables, we show that we can derive an estimand for the causal effect under empirical assumptions using representations in deep models as proxies. Theoretical analysis, empirical results, and visualizations show that our approach captures causal invariances and improves overall generalization.
With Greater Distance Comes Worse Performance: On the Perspective of Layer Utilization and Model Generalization
Jan 28, 2022
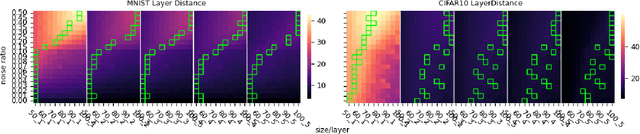
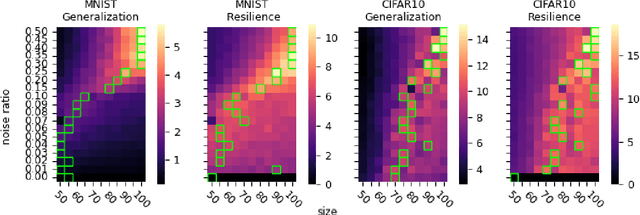
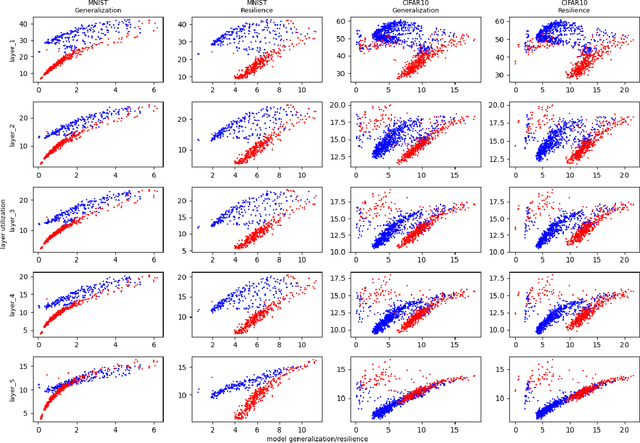
Generalization of deep neural networks remains one of the main open problems in machine learning. Previous theoretical works focused on deriving tight bounds of model complexity, while empirical works revealed that neural networks exhibit double descent with respect to both training sample counts and the neural network size. In this paper, we empirically examined how different layers of neural networks contribute differently to the model; we found that early layers generally learn representations relevant to performance on both training data and testing data. Contrarily, deeper layers only minimize training risks and fail to generalize well with testing or mislabeled data. We further illustrate the distance of trained weights to its initial value of final layers has high correlation to generalization errors and can serve as an indicator of an overfit of model. Moreover, we show evidence to support post-training regularization by re-initializing weights of final layers. Our findings provide an efficient method to estimate the generalization capability of neural networks, and the insight of those quantitative results may inspire derivation to better generalization bounds that take the internal structure of neural networks into consideration.
MEBOW: Monocular Estimation of Body Orientation In the Wild
Nov 27, 2020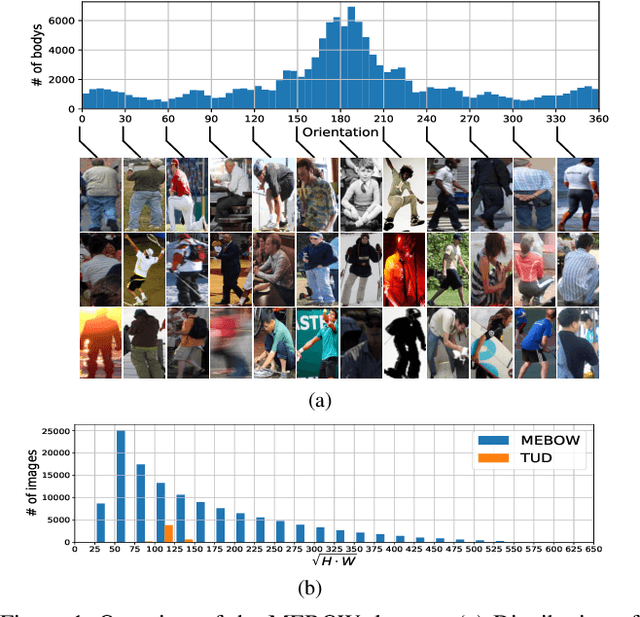
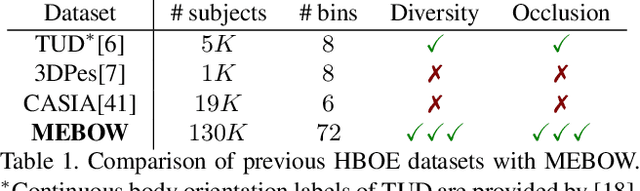
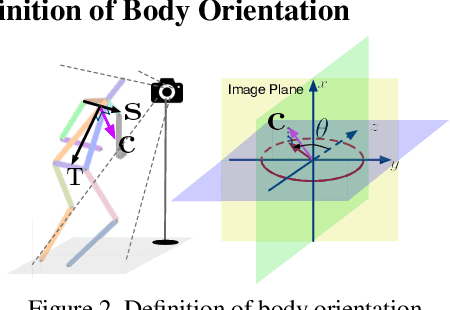
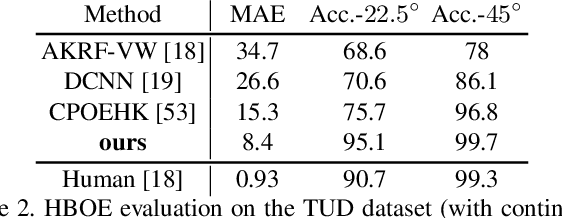
Body orientation estimation provides crucial visual cues in many applications, including robotics and autonomous driving. It is particularly desirable when 3-D pose estimation is difficult to infer due to poor image resolution, occlusion or indistinguishable body parts. We present COCO-MEBOW (Monocular Estimation of Body Orientation in the Wild), a new large-scale dataset for orientation estimation from a single in-the-wild image. The body-orientation labels for around 130K human bodies within 55K images from the COCO dataset have been collected using an efficient and high-precision annotation pipeline. We also validated the benefits of the dataset. First, we show that our dataset can substantially improve the performance and the robustness of a human body orientation estimation model, the development of which was previously limited by the scale and diversity of the available training data. Additionally, we present a novel triple-source solution for 3-D human pose estimation, where 3-D pose labels, 2-D pose labels, and our body-orientation labels are all used in joint training. Our model significantly outperforms state-of-the-art dual-source solutions for monocular 3-D human pose estimation, where training only uses 3-D pose labels and 2-D pose labels. This substantiates an important advantage of MEBOW for 3-D human pose estimation, which is particularly appealing because the per-instance labeling cost for body orientations is far less than that for 3-D poses. The work demonstrates high potential of MEBOW in addressing real-world challenges involving understanding human behaviors. Further information of this work is available at https://chenyanwu.github.io/MEBOW/.