 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Real-Time Colonoscopic Polyp Segmentation on Commodity CPUs via Ultra-Lightweight Architecture
Feb 04, 2026Early detection of colorectal cancer hinges on real-time, accurate polyp identification and resection. Yet current high-precision segmentation models rely on GPUs, making them impractical to deploy in primary hospitals, mobile endoscopy units, or capsule robots. To bridge this gap, we present the UltraSeg family, operating in an extreme-compression regime (<0.3 M parameters). UltraSeg-108K (0.108 M parameters) is optimized for single-center data, while UltraSeg-130K (0.13 M parameters) generalizes to multi-center, multi-modal images. By jointly optimizing encoder-decoder widths, incorporating constrained dilated convolutions to enlarge receptive fields, and integrating a cross-layer lightweight fusion module, the models achieve 90 FPS on a single CPU core without sacrificing accuracy. Evaluated on seven public datasets, UltraSeg retains >94% of the Dice score of a 31 M-parameter U-Net while utilizing only 0.4% of its parameters, establishing a strong, clinically viable baseline for the extreme-compression domain and offering an immediately deployable solution for resource-constrained settings. This work provides not only a CPU-native solution for colonoscopy but also a reproducible blueprint for broader minimally invasive surgical vision applications. Source code is publicly available to ensure reproducibility and facilitate future benchmarking.
AI-driven Prediction of Insulin Resistance in Normal Populations: Comparing Models and Criteria
Mar 07, 2025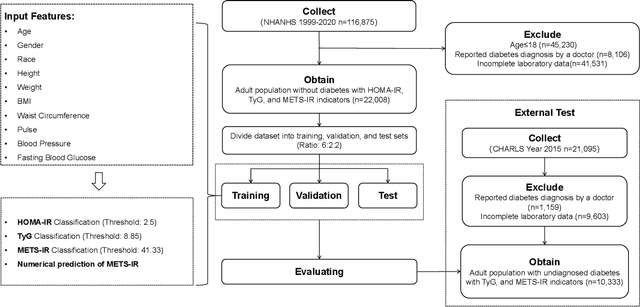
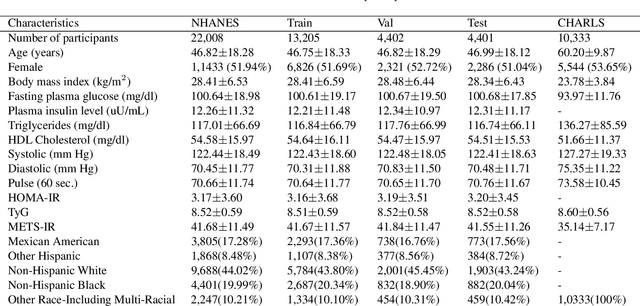
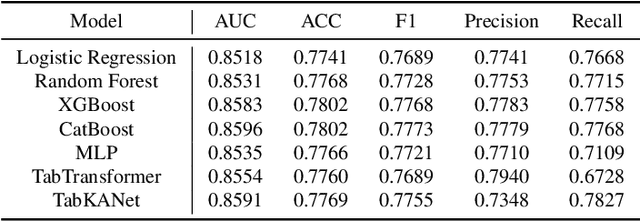
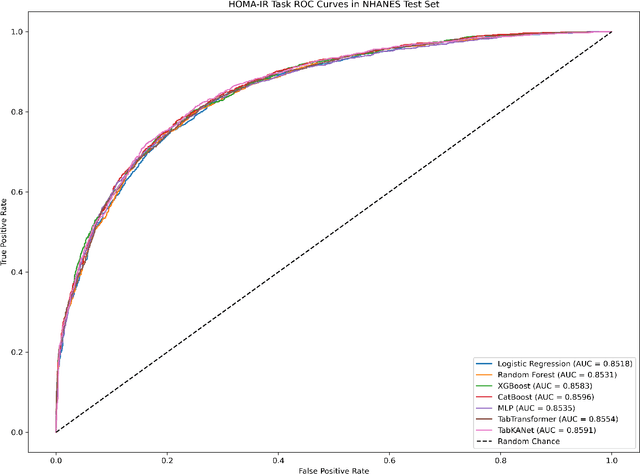
Insulin resistance (IR) is a key precursor to diabetes and a significant risk factor for cardiovascular disease. Traditional IR assessment methods require multiple blood tests. We developed a simple AI model using only fasting blood glucose to predict IR in non-diabetic populations. Data from the NHANES (1999-2020) and CHARLS (2015) studies were used for model training and validation. Input features included age, gender, height, weight, blood pressure, waist circumference, and fasting blood glucose. The CatBoost algorithm achieved AUC values of 0.8596 (HOMA-IR) and 0.7777 (TyG index) in NHANES, with an external AUC of 0.7442 for TyG. For METS-IR prediction, the model achieved AUC values of 0.9731 (internal) and 0.9591 (external), with RMSE values of 3.2643 (internal) and 3.057 (external). SHAP analysis highlighted waist circumference as a key predictor of IR. This AI model offers a minimally invasive and effective tool for IR prediction, supporting early diabetes and cardiovascular disease prevention.
Acquire Precise and Comparable Fundus Image Quality Score: FTHNet and FQS Dataset
Nov 19, 2024The retinal fundus images are utilized extensively in the diagnosis, and their quality can directly affect the diagnosis results. However, due to the insufficient dataset and algorithm application, current fundus image quality assessment (FIQA) methods are not powerful enough to meet ophthalmologists` demands. In this paper, we address the limitations of datasets and algorithms in FIQA. First, we establish a new FIQA dataset, Fundus Quality Score(FQS), which includes 2246 fundus images with two labels: a continuous Mean Opinion Score varying from 0 to 100 and a three-level quality label. Then, we propose a FIQA Transformer-based Hypernetwork (FTHNet) to solve these tasks with regression results rather than classification results in conventional FIQA works. The FTHNet is optimized for the FIQA tasks with extensive experiments. Results on our FQS dataset show that the FTHNet can give quality scores for fundus images with PLCC of 0.9423 and SRCC of 0.9488, significantly outperforming other methods with fewer parameters and less computation complexity.We successfully build a dataset and model addressing the problems of current FIQA methods. Furthermore, the model deployment experiments demonstrate its potential in automatic medical image quality control. All experiments are carried out with 10-fold cross-validation to ensure the significance of the results.
Versatile Cataract Fundus Image Restoration Model Utilizing Unpaired Cataract and High-quality Images
Nov 19, 2024



Cataract is one of the most common blinding eye diseases and can be treated by surgery. However, because cataract patients may also suffer from other blinding eye diseases, ophthalmologists must diagnose them before surgery. The cloudy lens of cataract patients forms a hazy degeneration in the fundus images, making it challenging to observe the patient's fundus vessels, which brings difficulties to the diagnosis process. To address this issue, this paper establishes a new cataract image restoration method named Catintell. It contains a cataract image synthesizing model, Catintell-Syn, and a restoration model, Catintell-Res. Catintell-Syn uses GAN architecture with fully unsupervised data to generate paired cataract-like images with realistic style and texture rather than the conventional Gaussian degradation algorithm. Meanwhile, Catintell-Res is an image restoration network that can improve the quality of real cataract fundus images using the knowledge learned from synthetic cataract images. Extensive experiments show that Catintell-Res outperforms other cataract image restoration methods in PSNR with 39.03 and SSIM with 0.9476. Furthermore, the universal restoration ability that Catintell-Res gained from unpaired cataract images can process cataract images from various datasets. We hope the models can help ophthalmologists identify other blinding eye diseases of cataract patients and inspire more medical image restoration methods in the future.
TabKANet: Tabular Data Modelling with Kolmogorov-Arnold Network and Transformer
Sep 13, 2024



Tabular data is the most common type of data in real-life scenarios. In this study, we propose a method based on the TabKANet architecture, which utilizes the Kolmogorov-Arnold network to encode numerical features and merge them with categorical features, enabling unified modeling of tabular data on the Transformer architecture. This model demonstrates outstanding performance in six widely used binary classification tasks, suggesting that TabKANet has the potential to become a standard approach for tabular modeling, surpassing traditional neural networks. Furthermore, this research reveals the significant advantages of the Kolmogorov-Arnold network in encoding numerical features. The code of our work is available at https://github.com/tsinghuamedgao20/TabKANet.
CSCPR: Cross-Source-Context Indoor RGB-D Place Recognition
Jul 24, 2024



We present a new algorithm, Cross-Source-Context Place Recognition (CSCPR), for RGB-D indoor place recognition that integrates global retrieval and reranking into a single end-to-end model. Unlike prior approaches that primarily focus on the RGB domain, CSCPR is designed to handle the RGB-D data. We extend the Context-of-Clusters (CoCs) for handling noisy colorized point clouds and introduce two novel modules for reranking: the Self-Context Cluster (SCC) and Cross Source Context Cluster (CSCC), which enhance feature representation and match query-database pairs based on local features, respectively. We also present two new datasets, ScanNetIPR and ARKitIPR. Our experiments demonstrate that CSCPR significantly outperforms state-of-the-art models on these datasets by at least 36.5% in Recall@1 at ScanNet-PR dataset and 44% in new datasets. Code and datasets will be released.
PoCo: Point Context Cluster for RGBD Indoor Place Recognition
Apr 03, 2024We present a novel end-to-end algorithm (PoCo) for the indoor RGB-D place recognition task, aimed at identifying the most likely match for a given query frame within a reference database. The task presents inherent challenges attributed to the constrained field of view and limited range of perception sensors. We propose a new network architecture, which generalizes the recent Context of Clusters (CoCs) to extract global descriptors directly from the noisy point clouds through end-to-end learning. Moreover, we develop the architecture by integrating both color and geometric modalities into the point features to enhance the global descriptor representation. We conducted evaluations on public datasets ScanNet-PR and ARKit with 807 and 5047 scenarios, respectively. PoCo achieves SOTA performance: on ScanNet-PR, we achieve R@1 of 64.63%, a 5.7% improvement from the best-published result CGis (61.12%); on Arkit, we achieve R@1 of 45.12%, a 13.3% improvement from the best-published result CGis (39.82%). In addition, PoCo shows higher efficiency than CGis in inference time (1.75X-faster), and we demonstrate the effectiveness of PoCo in recognizing places within a real-world laboratory environment.
Tabletop Transparent Scene Reconstruction via Epipolar-Guided Optical Flow with Monocular Depth Completion Prior
Oct 15, 2023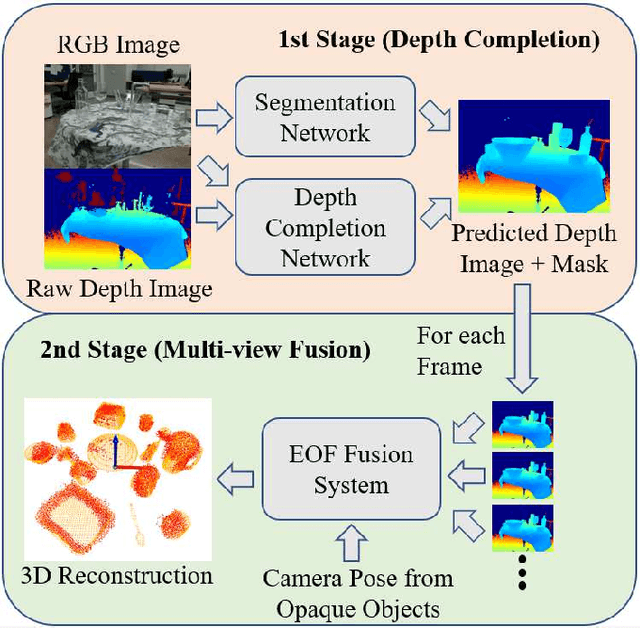


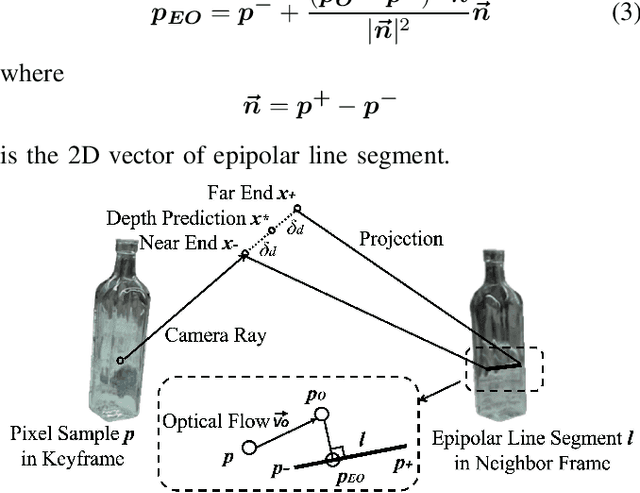
Reconstructing transparent objects using affordable RGB-D cameras is a persistent challenge in robotic perception due to inconsistent appearances across views in the RGB domain and inaccurate depth readings in each single-view. We introduce a two-stage pipeline for reconstructing transparent objects tailored for mobile platforms. In the first stage, off-the-shelf monocular object segmentation and depth completion networks are leveraged to predict the depth of transparent objects, furnishing single-view shape prior. Subsequently, we propose Epipolar-guided Optical Flow (EOF) to fuse several single-view shape priors from the first stage to a cross-view consistent 3D reconstruction given camera poses estimated from opaque part of the scene. Our key innovation lies in EOF which employs boundary-sensitive sampling and epipolar-line constraints into optical flow to accurately establish 2D correspondences across multiple views on transparent objects. Quantitative evaluations demonstrate that our pipeline significantly outperforms baseline methods in 3D reconstruction quality, paving the way for more adept robotic perception and interaction with transparent objects.
OphGLM: Training an Ophthalmology Large Language-and-Vision Assistant based on Instructions and Dialogue
Jun 22, 2023



Large multimodal language models (LMMs) have achieved significant success in general domains. However, due to the significant differences between medical images and text and general web content, the performance of LMMs in medical scenarios is limited. In ophthalmology, clinical diagnosis relies on multiple modalities of medical images, but unfortunately, multimodal ophthalmic large language models have not been explored to date. In this paper, we study and construct an ophthalmic large multimodal model. Firstly, we use fundus images as an entry point to build a disease assessment and diagnosis pipeline to achieve common ophthalmic disease diagnosis and lesion segmentation. Then, we establish a new ophthalmic multimodal instruction-following and dialogue fine-tuning dataset based on disease-related knowledge data and publicly available real-world medical dialogue. We introduce visual ability into the large language model to complete the ophthalmic large language and vision assistant (OphGLM). Our experimental results demonstrate that the OphGLM model performs exceptionally well, and it has the potential to revolutionize clinical applications in ophthalmology. The dataset, code, and models will be made publicly available at https://github.com/ML-AILab/OphGLM.
RFormer: Transformer-based Generative Adversarial Network for Real Fundus Image Restoration on A New Clinical Benchmark
Jan 03, 2022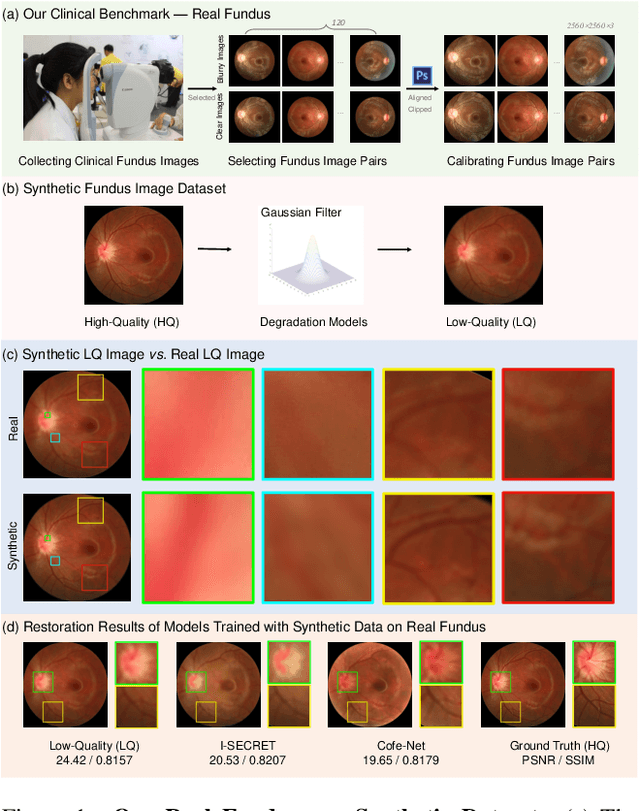

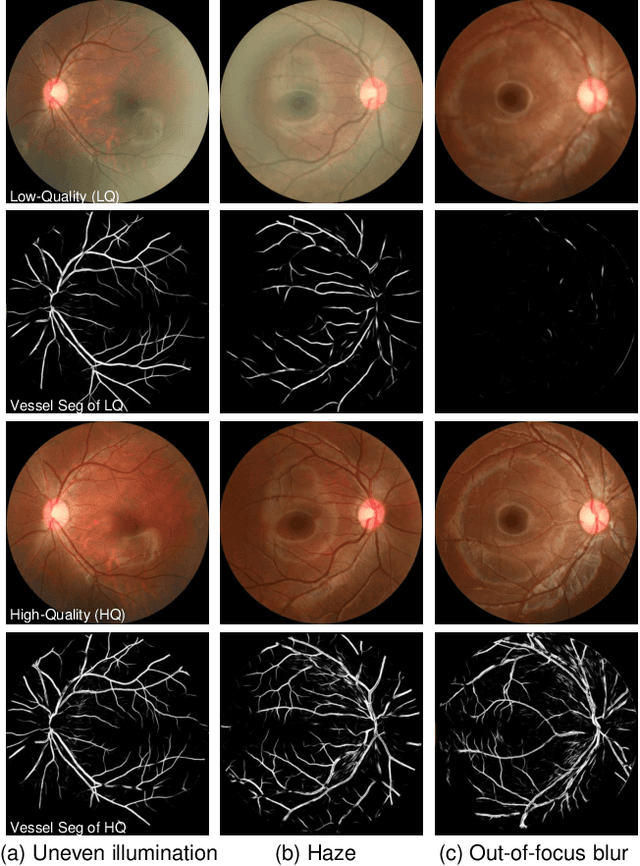

Ophthalmologists have used fundus images to screen and diagnose eye diseases. However, different equipments and ophthalmologists pose large variations to the quality of fundus images. Low-quality (LQ) degraded fundus images easily lead to uncertainty in clinical screening and generally increase the risk of misdiagnosis. Thus, real fundus image restoration is worth studying. Unfortunately, real clinical benchmark has not been explored for this task so far. In this paper, we investigate the real clinical fundus image restoration problem. Firstly, We establish a clinical dataset, Real Fundus (RF), including 120 low- and high-quality (HQ) image pairs. Then we propose a novel Transformer-based Generative Adversarial Network (RFormer) to restore the real degradation of clinical fundus images. The key component in our network is the Window-based Self-Attention Block (WSAB) which captures non-local self-similarity and long-range dependencies. To produce more visually pleasant results, a Transformer-based discriminator is introduced. Extensive experiments on our clinical benchmark show that the proposed RFormer significantly outperforms the state-of-the-art (SOTA) methods. In addition, experiments of downstream tasks such as vessel segmentation and optic disc/cup detection demonstrate that our proposed RFormer benefits clinical fundus image analysis and applications. The dataset, code, and models will be released.