 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Deep-learning-Based Approach For mRNA Optimization: High Fidelity, Computation Efficiency, and Multiple Optimization Factors
May 29, 2025The mRNA optimization is critical for therapeutic and biotechnological applications, since sequence features directly govern protein expression levels and efficacy. However, current methods face significant challenges in simultaneously achieving three key objectives: (1) fidelity (preventing unintended amino acid changes), (2) computational efficiency (speed and scalability), and (3) the scope of optimization variables considered (multi-objective capability). Furthermore, existing methods often fall short of comprehensively incorporating the factors related to the mRNA lifecycle and translation process, including intrinsic mRNA sequence properties, secondary structure, translation elongation kinetics, and tRNA availability. To address these limitations, we introduce \textbf{RNop}, a novel deep learning-based method for mRNA optimization. We collect a large-scale dataset containing over 3 million sequences and design four specialized loss functions, the GPLoss, CAILoss, tAILoss, and MFELoss, which simultaneously enable explicit control over sequence fidelity while optimizing species-specific codon adaptation, tRNA availability, and desirable mRNA secondary structure features. Then, we demonstrate RNop's effectiveness through extensive in silico and in vivo experiments. RNop ensures high sequence fidelity, achieves significant computational throughput up to 47.32 sequences/s, and yields optimized mRNA sequences resulting in a significant increase in protein expression for functional proteins compared to controls. RNop surpasses current methodologies in both quantitative metrics and experimental validation, enlightening a new dawn for efficient and effective mRNA design. Code and models will be available at https://github.com/HudenJear/RPLoss.
MMS-VPR: Multimodal Street-Level Visual Place Recognition Dataset and Benchmark
May 18, 2025Existing visual place recognition (VPR) datasets predominantly rely on vehicle-mounted imagery, lack multimodal diversity and underrepresent dense, mixed-use street-level spaces, especially in non-Western urban contexts. To address these gaps, we introduce MMS-VPR, a large-scale multimodal dataset for street-level place recognition in complex, pedestrian-only environments. The dataset comprises 78,575 annotated images and 2,512 video clips captured across 207 locations in a ~70,800 $\mathrm{m}^2$ open-air commercial district in Chengdu, China. Each image is labeled with precise GPS coordinates, timestamp, and textual metadata, and covers varied lighting conditions, viewpoints, and timeframes. MMS-VPR follows a systematic and replicable data collection protocol with minimal device requirements, lowering the barrier for scalable dataset creation. Importantly, the dataset forms an inherent spatial graph with 125 edges, 81 nodes, and 1 subgraph, enabling structure-aware place recognition. We further define two application-specific subsets -- Dataset_Edges and Dataset_Points -- to support fine-grained and graph-based evaluation tasks. Extensive benchmarks using conventional VPR models, graph neural networks, and multimodal baselines show substantial improvements when leveraging multimodal and structural cues. MMS-VPR facilitates future research at the intersection of computer vision, geospatial understanding, and multimodal reasoning. The dataset is publicly available at https://huggingface.co/datasets/Yiwei-Ou/MMS-VPR.
AI-driven Prediction of Insulin Resistance in Normal Populations: Comparing Models and Criteria
Mar 07, 2025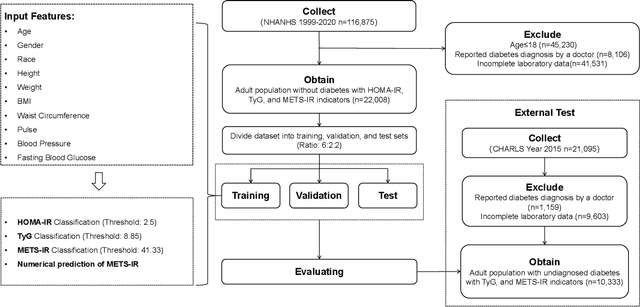
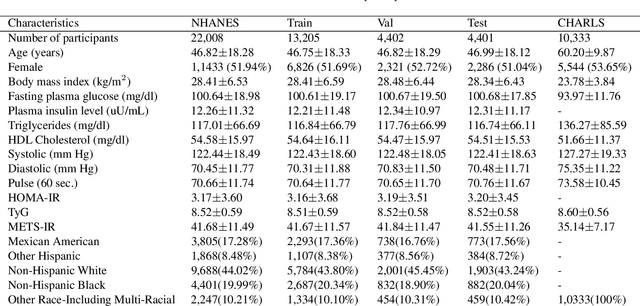
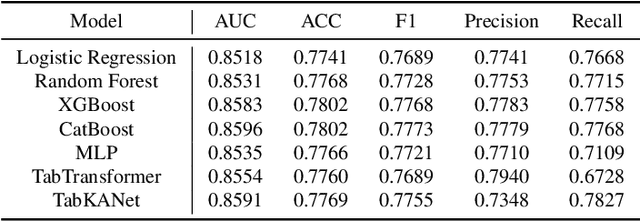
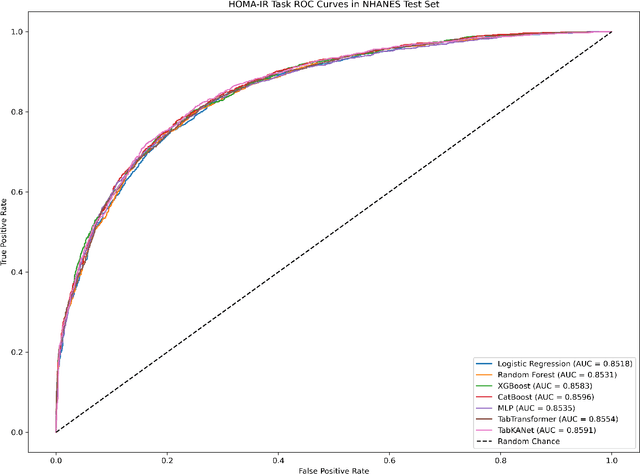
Insulin resistance (IR) is a key precursor to diabetes and a significant risk factor for cardiovascular disease. Traditional IR assessment methods require multiple blood tests. We developed a simple AI model using only fasting blood glucose to predict IR in non-diabetic populations. Data from the NHANES (1999-2020) and CHARLS (2015) studies were used for model training and validation. Input features included age, gender, height, weight, blood pressure, waist circumference, and fasting blood glucose. The CatBoost algorithm achieved AUC values of 0.8596 (HOMA-IR) and 0.7777 (TyG index) in NHANES, with an external AUC of 0.7442 for TyG. For METS-IR prediction, the model achieved AUC values of 0.9731 (internal) and 0.9591 (external), with RMSE values of 3.2643 (internal) and 3.057 (external). SHAP analysis highlighted waist circumference as a key predictor of IR. This AI model offers a minimally invasive and effective tool for IR prediction, supporting early diabetes and cardiovascular disease prevention.
Domain Adaptive Graph Classification
Dec 21, 2023Despite the remarkable accomplishments of graph neural networks (GNNs), they typically rely on task-specific labels, posing potential challenges in terms of their acquisition. Existing work have been made to address this issue through the lens of unsupervised domain adaptation, wherein labeled source graphs are utilized to enhance the learning process for target data. However, the simultaneous exploration of graph topology and reduction of domain disparities remains a substantial hurdle. In this paper, we introduce the Dual Adversarial Graph Representation Learning (DAGRL), which explore the graph topology from dual branches and mitigate domain discrepancies via dual adversarial learning. Our method encompasses a dual-pronged structure, consisting of a graph convolutional network branch and a graph kernel branch, which enables us to capture graph semantics from both implicit and explicit perspectives. Moreover, our approach incorporates adaptive perturbations into the dual branches, which align the source and target distribution to address domain discrepancies. Extensive experiments on a wild range graph classification datasets demonstrate the effectiveness of our proposed method.
Music Generation based on Generative Adversarial Networks with Transformer
Oct 03, 2023
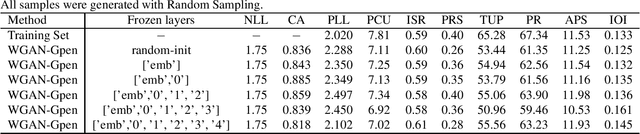
Autoregressive models based on Transformers have become the prevailing approach for generating music compositions that exhibit comprehensive musical structure. These models are typically trained by minimizing the negative log-likelihood (NLL) of the observed sequence in an autoregressive manner. However, when generating long sequences, the quality of samples from these models tends to significantly deteriorate due to exposure bias. To address this issue, we leverage classifiers trained to differentiate between real and sampled sequences to identify these failures. This observation motivates our exploration of adversarial losses as a complement to the NLL objective. We employ a pre-trained Span-BERT model as the discriminator in the Generative Adversarial Network (GAN) framework, which enhances training stability in our experiments. To optimize discrete sequences within the GAN framework, we utilize the Gumbel-Softmax trick to obtain a differentiable approximation of the sampling process. Additionally, we partition the sequences into smaller chunks to ensure that memory constraints are met. Through human evaluations and the introduction of a novel discriminative metric, we demonstrate that our approach outperforms a baseline model trained solely on likelihood maximization.