 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Generative Modeling with Manually Bridged Diffusion Models
Feb 27, 2025In this paper we describe a novel framework for diffusion-based generative modeling on constrained spaces. In particular, we introduce manual bridges, a framework that expands the kinds of constraints that can be practically used to form so-called diffusion bridges. We develop a mechanism for combining multiple such constraints so that the resulting multiply-constrained model remains a manual bridge that respects all constraints. We also develop a mechanism for training a diffusion model that respects such multiple constraints while also adapting it to match a data distribution. We develop and extend theory demonstrating the mathematical validity of our mechanisms. Additionally, we demonstrate our mechanism in constrained generative modeling tasks, highlighting a particular high-value application in modeling trajectory initializations for path planning and control in autonomous vehicles.
Sonicmesh: Enhancing 3D Human Mesh Reconstruction in Vision-Impaired Environments With Acoustic Signals
Dec 15, 20243D Human Mesh Reconstruction (HMR) from 2D RGB images faces challenges in environments with poor lighting, privacy concerns, or occlusions. These weaknesses of RGB imaging can be complemented by acoustic signals, which are widely available, easy to deploy, and capable of penetrating obstacles. However, no existing methods effectively combine acoustic signals with RGB data for robust 3D HMR. The primary challenges include the low-resolution images generated by acoustic signals and the lack of dedicated processing backbones. We introduce SonicMesh, a novel approach combining acoustic signals with RGB images to reconstruct 3D human mesh. To address the challenges of low resolution and the absence of dedicated processing backbones in images generated by acoustic signals, we modify an existing method, HRNet, for effective feature extraction. We also integrate a universal feature embedding technique to enhance the precision of cross-dimensional feature alignment, enabling SonicMesh to achieve high accuracy. Experimental results demonstrate that SonicMesh accurately reconstructs 3D human mesh in challenging environments such as occlusions, non-line-of-sight scenarios, and poor lighting.
TorchDriveEnv: A Reinforcement Learning Benchmark for Autonomous Driving with Reactive, Realistic, and Diverse Non-Playable Characters
May 07, 2024
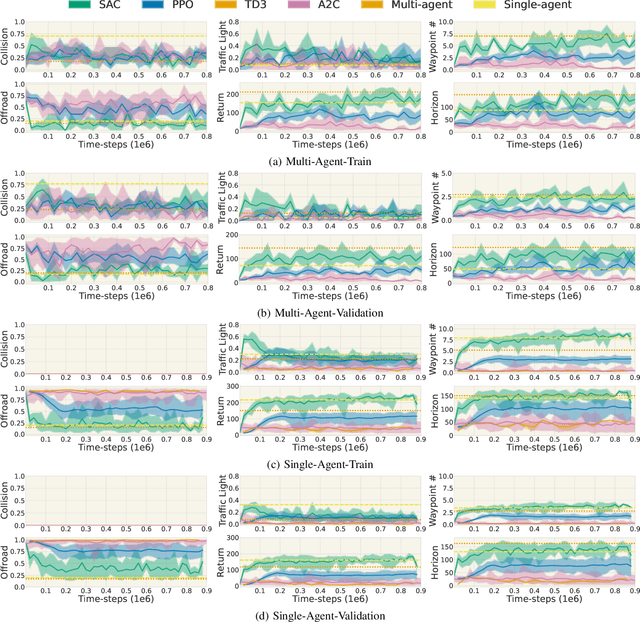
The training, testing, and deployment, of autonomous vehicles requires realistic and efficient simulators. Moreover, because of the high variability between different problems presented in different autonomous systems, these simulators need to be easy to use, and easy to modify. To address these problems we introduce TorchDriveSim and its benchmark extension TorchDriveEnv. TorchDriveEnv is a lightweight reinforcement learning benchmark programmed entirely in Python, which can be modified to test a number of different factors in learned vehicle behavior, including the effect of varying kinematic models, agent types, and traffic control patterns. Most importantly unlike many replay based simulation approaches, TorchDriveEnv is fully integrated with a state of the art behavioral simulation API. This allows users to train and evaluate driving models alongside data driven Non-Playable Characters (NPC) whose initializations and driving behavior are reactive, realistic, and diverse. We illustrate the efficiency and simplicity of TorchDriveEnv by evaluating common reinforcement learning baselines in both training and validation environments. Our experiments show that TorchDriveEnv is easy to use, but difficult to solve.
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Apr 30, 2024Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
Nearest Neighbour Score Estimators for Diffusion Generative Models
Feb 12, 2024



Score function estimation is the cornerstone of both training and sampling from diffusion generative models. Despite this fact, the most commonly used estimators are either biased neural network approximations or high variance Monte Carlo estimators based on the conditional score. We introduce a novel nearest neighbour score function estimator which utilizes multiple samples from the training set to dramatically decrease estimator variance. We leverage our low variance estimator in two compelling applications. Training consistency models with our estimator, we report a significant increase in both convergence speed and sample quality. In diffusion models, we show that our estimator can replace a learned network for probability-flow ODE integration, opening promising new avenues of future research.
Domain Adaptive Graph Classification
Dec 21, 2023Despite the remarkable accomplishments of graph neural networks (GNNs), they typically rely on task-specific labels, posing potential challenges in terms of their acquisition. Existing work have been made to address this issue through the lens of unsupervised domain adaptation, wherein labeled source graphs are utilized to enhance the learning process for target data. However, the simultaneous exploration of graph topology and reduction of domain disparities remains a substantial hurdle. In this paper, we introduce the Dual Adversarial Graph Representation Learning (DAGRL), which explore the graph topology from dual branches and mitigate domain discrepancies via dual adversarial learning. Our method encompasses a dual-pronged structure, consisting of a graph convolutional network branch and a graph kernel branch, which enables us to capture graph semantics from both implicit and explicit perspectives. Moreover, our approach incorporates adaptive perturbations into the dual branches, which align the source and target distribution to address domain discrepancies. Extensive experiments on a wild range graph classification datasets demonstrate the effectiveness of our proposed method.
Music Generation based on Generative Adversarial Networks with Transformer
Oct 03, 2023
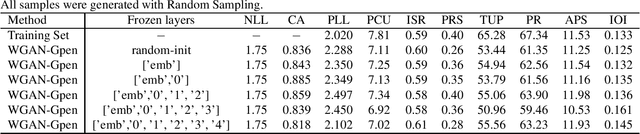
Autoregressive models based on Transformers have become the prevailing approach for generating music compositions that exhibit comprehensive musical structure. These models are typically trained by minimizing the negative log-likelihood (NLL) of the observed sequence in an autoregressive manner. However, when generating long sequences, the quality of samples from these models tends to significantly deteriorate due to exposure bias. To address this issue, we leverage classifiers trained to differentiate between real and sampled sequences to identify these failures. This observation motivates our exploration of adversarial losses as a complement to the NLL objective. We employ a pre-trained Span-BERT model as the discriminator in the Generative Adversarial Network (GAN) framework, which enhances training stability in our experiments. To optimize discrete sequences within the GAN framework, we utilize the Gumbel-Softmax trick to obtain a differentiable approximation of the sampling process. Additionally, we partition the sequences into smaller chunks to ensure that memory constraints are met. Through human evaluations and the introduction of a novel discriminative metric, we demonstrate that our approach outperforms a baseline model trained solely on likelihood maximization.
A Diffusion-Model of Joint Interactive Navigation
Sep 21, 2023



Simulation of autonomous vehicle systems requires that simulated traffic participants exhibit diverse and realistic behaviors. The use of prerecorded real-world traffic scenarios in simulation ensures realism but the rarity of safety critical events makes large scale collection of driving scenarios expensive. In this paper, we present DJINN - a diffusion based method of generating traffic scenarios. Our approach jointly diffuses the trajectories of all agents, conditioned on a flexible set of state observations from the past, present, or future. On popular trajectory forecasting datasets, we report state of the art performance on joint trajectory metrics. In addition, we demonstrate how DJINN flexibly enables direct test-time sampling from a variety of valuable conditional distributions including goal-based sampling, behavior-class sampling, and scenario editing.
Don't be so negative! Score-based Generative Modeling with Oracle-assisted Guidance
Jul 31, 2023The maximum likelihood principle advocates parameter estimation via optimization of the data likelihood function. Models estimated in this way can exhibit a variety of generalization characteristics dictated by, e.g. architecture, parameterization, and optimization bias. This work addresses model learning in a setting where there further exists side-information in the form of an oracle that can label samples as being outside the support of the true data generating distribution. Specifically we develop a new denoising diffusion probabilistic modeling (DDPM) methodology, Gen-neG, that leverages this additional side-information. Our approach builds on generative adversarial networks (GANs) and discriminator guidance in diffusion models to guide the generation process towards the positive support region indicated by the oracle. We empirically establish the utility of Gen-neG in applications including collision avoidance in self-driving simulators and safety-guarded human motion generation.
Realistically distributing object placements in synthetic training data improves the performance of vision-based object detection models
May 24, 2023When training object detection models on synthetic data, it is important to make the distribution of synthetic data as close as possible to the distribution of real data. We investigate specifically the impact of object placement distribution, keeping all other aspects of synthetic data fixed. Our experiment, training a 3D vehicle detection model in CARLA and testing on KITTI, demonstrates a substantial improvement resulting from improving the object placement distribution.