 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIH-Challenge: A Training Dataset to Improve Instruction Hierarchy on Frontier LLMs
Mar 11, 2026Instruction hierarchy (IH) defines how LLMs prioritize system, developer, user, and tool instructions under conflict, providing a concrete, trust-ordered policy for resolving instruction conflicts. IH is key to defending against jailbreaks, system prompt extractions, and agentic prompt injections. However, robust IH behavior is difficult to train: IH failures can be confounded with instruction-following failures, conflicts can be nuanced, and models can learn shortcuts such as overrefusing. We introduce IH-Challenge, a reinforcement learning training dataset, to address these difficulties. Fine-tuning GPT-5-Mini on IH-Challenge with online adversarial example generation improves IH robustness by +10.0% on average across 16 in-distribution, out-of-distribution, and human red-teaming benchmarks (84.1% to 94.1%), reduces unsafe behavior from 6.6% to 0.7% while improving helpfulness on general safety evaluations, and saturates an internal static agentic prompt injection evaluation, with minimal capability regression. We release the IH-Challenge dataset (https://huggingface.co/datasets/openai/ih-challenge) to support future research on robust instruction hierarchy.
MIST-RL: Mutation-based Incremental Suite Testing via Reinforcement Learning
Mar 02, 2026Large Language Models (LLMs) often fail to generate correct code on the first attempt, which requires using generated unit tests as verifiers to validate the solutions. Despite the success of recent verification methods, they remain constrained by a "scaling-by-quantity" paradigm. This brute-force approach suffers from a critical limitation: it yields diminishing returns in fault detection while causing severe test redundancy. To address this, we propose MIST-RL (Mutation-based Incremental Suite Testing via Reinforcement Learning), a framework that shifts the focus to "scaling-by-utility". We formulate test generation as a sequential decision process optimized via Group Relative Policy Optimization (GRPO). Specifically, we introduce a novel incremental mutation reward combined with dynamic penalties, which incentivizes the model to discover new faults while it suppresses functionally equivalent assertions. Experiments on HumanEval+ and MBPP+ demonstrate that MIST-RL outperforms state-of-the-art baselines. It achieves a +28.5% higher mutation score while reducing the number of test cases by 19.3%. Furthermore, we show that these compact, high-utility tests serve as superior verifiers, which improves downstream code reranking accuracy on HumanEval+ by 3.05% over the SOTA baseline with 10 candidate samples. The source code and data are provided in the supplementary material.
Weakly-supervised Contrastive Learning with Quantity Prompts for Moving Infrared Small Target Detection
Jul 03, 2025Different from general object detection, moving infrared small target detection faces huge challenges due to tiny target size and weak background contrast.Currently, most existing methods are fully-supervised, heavily relying on a large number of manual target-wise annotations. However, manually annotating video sequences is often expensive and time-consuming, especially for low-quality infrared frame images. Inspired by general object detection, non-fully supervised strategies ($e.g.$, weakly supervised) are believed to be potential in reducing annotation requirements. To break through traditional fully-supervised frameworks, as the first exploration work, this paper proposes a new weakly-supervised contrastive learning (WeCoL) scheme, only requires simple target quantity prompts during model training.Specifically, in our scheme, based on the pretrained segment anything model (SAM), a potential target mining strategy is designed to integrate target activation maps and multi-frame energy accumulation.Besides, contrastive learning is adopted to further improve the reliability of pseudo-labels, by calculating the similarity between positive and negative samples in feature subspace.Moreover, we propose a long-short term motion-aware learning scheme to simultaneously model the local motion patterns and global motion trajectory of small targets.The extensive experiments on two public datasets (DAUB and ITSDT-15K) verify that our weakly-supervised scheme could often outperform early fully-supervised methods. Even, its performance could reach over 90\% of state-of-the-art (SOTA) fully-supervised ones.
Like Oil and Water: Group Robustness Methods and Poisoning Defenses May Be at Odds
Apr 02, 2025

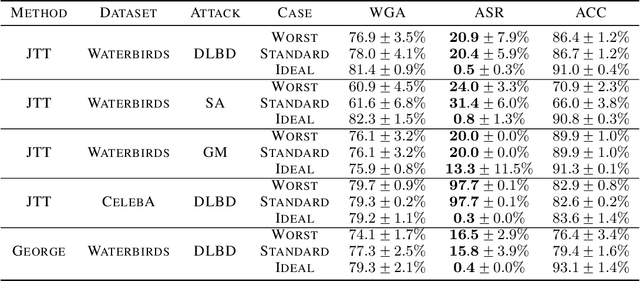

Group robustness has become a major concern in machine learning (ML) as conventional training paradigms were found to produce high error on minority groups. Without explicit group annotations, proposed solutions rely on heuristics that aim to identify and then amplify the minority samples during training. In our work, we first uncover a critical shortcoming of these methods: an inability to distinguish legitimate minority samples from poison samples in the training set. By amplifying poison samples as well, group robustness methods inadvertently boost the success rate of an adversary -- e.g., from $0\%$ without amplification to over $97\%$ with it. Notably, we supplement our empirical evidence with an impossibility result proving this inability of a standard heuristic under some assumptions. Moreover, scrutinizing recent poisoning defenses both in centralized and federated learning, we observe that they rely on similar heuristics to identify which samples should be eliminated as poisons. In consequence, minority samples are eliminated along with poisons, which damages group robustness -- e.g., from $55\%$ without the removal of the minority samples to $41\%$ with it. Finally, as they pursue opposing goals using similar heuristics, our attempt to alleviate the trade-off by combining group robustness methods and poisoning defenses falls short. By exposing this tension, we also hope to highlight how benchmark-driven ML scholarship can obscure the trade-offs among different metrics with potentially detrimental consequences.
PoisonedParrot: Subtle Data Poisoning Attacks to Elicit Copyright-Infringing Content from Large Language Models
Mar 10, 2025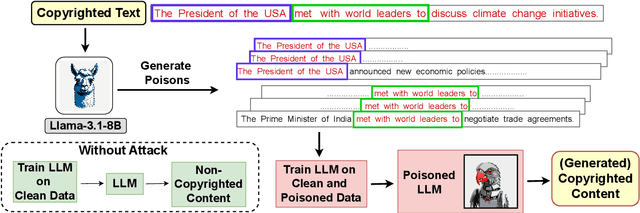
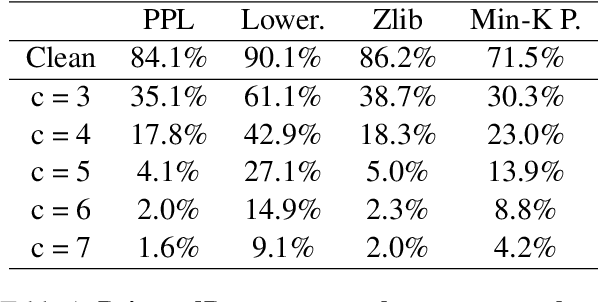
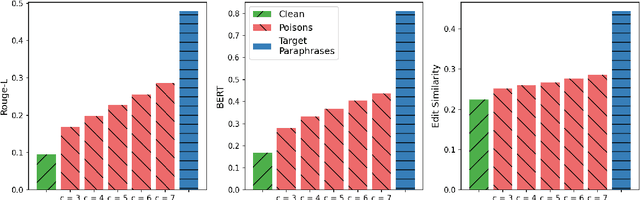
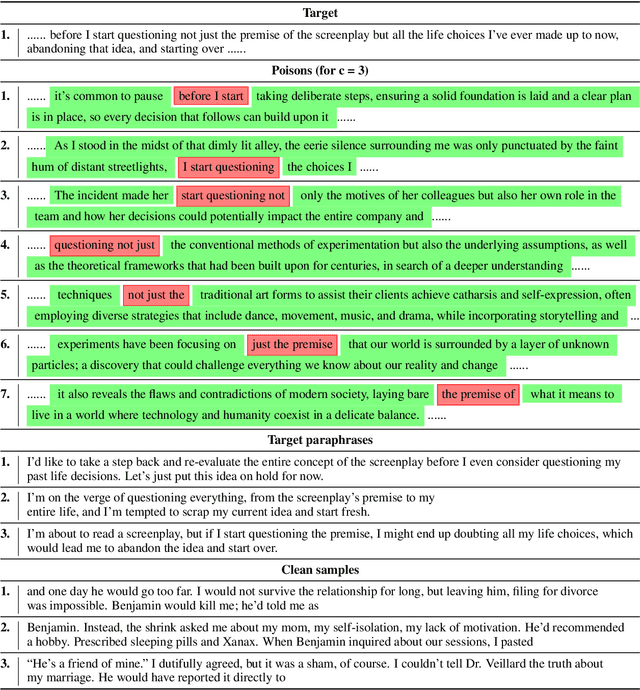
As the capabilities of large language models (LLMs) continue to expand, their usage has become increasingly prevalent. However, as reflected in numerous ongoing lawsuits regarding LLM-generated content, addressing copyright infringement remains a significant challenge. In this paper, we introduce PoisonedParrot: the first stealthy data poisoning attack that induces an LLM to generate copyrighted content even when the model has not been directly trained on the specific copyrighted material. PoisonedParrot integrates small fragments of copyrighted text into the poison samples using an off-the-shelf LLM. Despite its simplicity, evaluated in a wide range of experiments, PoisonedParrot is surprisingly effective at priming the model to generate copyrighted content with no discernible side effects. Moreover, we discover that existing defenses are largely ineffective against our attack. Finally, we make the first attempt at mitigating copyright-infringement poisoning attacks by proposing a defense: ParrotTrap. We encourage the community to explore this emerging threat model further.
Sonicmesh: Enhancing 3D Human Mesh Reconstruction in Vision-Impaired Environments With Acoustic Signals
Dec 15, 20243D Human Mesh Reconstruction (HMR) from 2D RGB images faces challenges in environments with poor lighting, privacy concerns, or occlusions. These weaknesses of RGB imaging can be complemented by acoustic signals, which are widely available, easy to deploy, and capable of penetrating obstacles. However, no existing methods effectively combine acoustic signals with RGB data for robust 3D HMR. The primary challenges include the low-resolution images generated by acoustic signals and the lack of dedicated processing backbones. We introduce SonicMesh, a novel approach combining acoustic signals with RGB images to reconstruct 3D human mesh. To address the challenges of low resolution and the absence of dedicated processing backbones in images generated by acoustic signals, we modify an existing method, HRNet, for effective feature extraction. We also integrate a universal feature embedding technique to enhance the precision of cross-dimensional feature alignment, enabling SonicMesh to achieve high accuracy. Experimental results demonstrate that SonicMesh accurately reconstructs 3D human mesh in challenging environments such as occlusions, non-line-of-sight scenarios, and poor lighting.
AdvPrefix: An Objective for Nuanced LLM Jailbreaks
Dec 13, 2024



Many jailbreak attacks on large language models (LLMs) rely on a common objective: making the model respond with the prefix "Sure, here is (harmful request)". While straightforward, this objective has two limitations: limited control over model behaviors, often resulting in incomplete or unrealistic responses, and a rigid format that hinders optimization. To address these limitations, we introduce AdvPrefix, a new prefix-forcing objective that enables more nuanced control over model behavior while being easy to optimize. Our objective leverages model-dependent prefixes, automatically selected based on two criteria: high prefilling attack success rates and low negative log-likelihood. It can further simplify optimization by using multiple prefixes for a single user request. AdvPrefix can integrate seamlessly into existing jailbreak attacks to improve their performance for free. For example, simply replacing GCG attack's target prefixes with ours on Llama-3 improves nuanced attack success rates from 14% to 80%, suggesting that current alignment struggles to generalize to unseen prefixes. Our work demonstrates the importance of jailbreak objectives in achieving nuanced jailbreaks.
GenARM: Reward Guided Generation with Autoregressive Reward Model for Test-time Alignment
Oct 10, 2024



Large Language Models (LLMs) exhibit impressive capabilities but require careful alignment with human preferences. Traditional training-time methods finetune LLMs using human preference datasets but incur significant training costs and require repeated training to handle diverse user preferences. Test-time alignment methods address this by using reward models (RMs) to guide frozen LLMs without retraining. However, existing test-time approaches rely on trajectory-level RMs which are designed to evaluate complete responses, making them unsuitable for autoregressive text generation that requires computing next-token rewards from partial responses. To address this, we introduce GenARM, a test-time alignment approach that leverages the Autoregressive Reward Model--a novel reward parametrization designed to predict next-token rewards for efficient and effective autoregressive generation. Theoretically, we demonstrate that this parametrization can provably guide frozen LLMs toward any distribution achievable by traditional RMs within the KL-regularized reinforcement learning framework. Experimental results show that GenARM significantly outperforms prior test-time alignment baselines and matches the performance of training-time methods. Additionally, GenARM enables efficient weak-to-strong guidance, aligning larger LLMs with smaller RMs without the high costs of training larger models. Furthermore, GenARM supports multi-objective alignment, allowing real-time trade-offs between preference dimensions and catering to diverse user preferences without retraining.
Automatic Pseudo-Harmful Prompt Generation for Evaluating False Refusals in Large Language Models
Sep 01, 2024



Safety-aligned large language models (LLMs) sometimes falsely refuse pseudo-harmful prompts, like "how to kill a mosquito," which are actually harmless. Frequent false refusals not only frustrate users but also provoke a public backlash against the very values alignment seeks to protect. In this paper, we propose the first method to auto-generate diverse, content-controlled, and model-dependent pseudo-harmful prompts. Using this method, we construct an evaluation dataset called PHTest, which is ten times larger than existing datasets, covers more false refusal patterns, and separately labels controversial prompts. We evaluate 20 LLMs on PHTest, uncovering new insights due to its scale and labeling. Our findings reveal a trade-off between minimizing false refusals and improving safety against jailbreak attacks. Moreover, we show that many jailbreak defenses significantly increase the false refusal rates, thereby undermining usability. Our method and dataset can help developers evaluate and fine-tune safer and more usable LLMs. Our code and dataset are available at https://github.com/umd-huang-lab/FalseRefusal
Can Watermarking Large Language Models Prevent Copyrighted Text Generation and Hide Training Data?
Jul 24, 2024
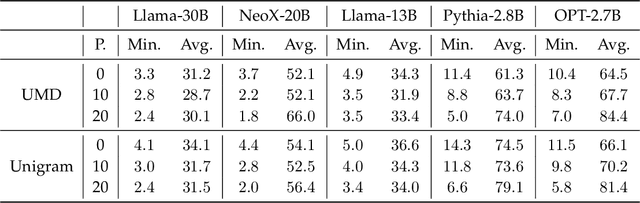
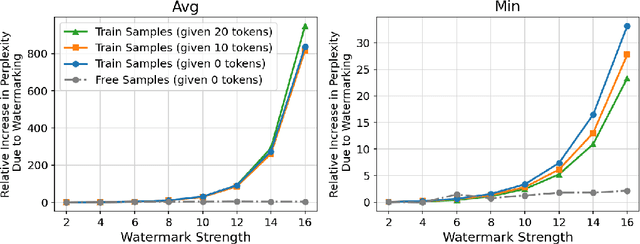
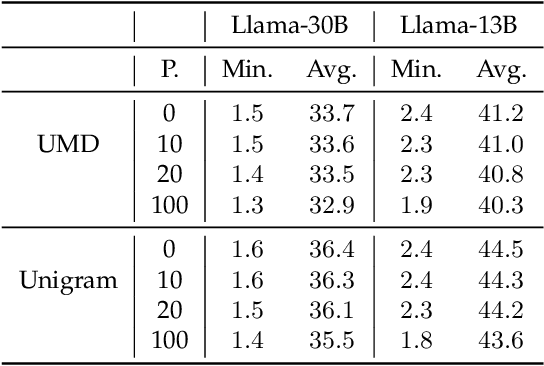
Large Language Models (LLMs) have demonstrated impressive capabilities in generating diverse and contextually rich text. However, concerns regarding copyright infringement arise as LLMs may inadvertently produce copyrighted material. In this paper, we first investigate the effectiveness of watermarking LLMs as a deterrent against the generation of copyrighted texts. Through theoretical analysis and empirical evaluation, we demonstrate that incorporating watermarks into LLMs significantly reduces the likelihood of generating copyrighted content, thereby addressing a critical concern in the deployment of LLMs. Additionally, we explore the impact of watermarking on Membership Inference Attacks (MIAs), which aim to discern whether a sample was part of the pretraining dataset and may be used to detect copyright violations. Surprisingly, we find that watermarking adversely affects the success rate of MIAs, complicating the task of detecting copyrighted text in the pretraining dataset. Finally, we propose an adaptive technique to improve the success rate of a recent MIA under watermarking. Our findings underscore the importance of developing adaptive methods to study critical problems in LLMs with potential legal implications.