 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2VLR: Heterogeneous Hypergraph Vision-Language Reasoning for Few-Shot Anomaly Detection
Apr 16, 2026As a classic vision task, anomaly detection has been widely applied in industrial inspection and medical imaging. In this task, data scarcity is often a frequently-faced issue. To solve it, the few-shot anomaly detection (FSAD) scheme is attracting increasing attention. In recent years, beyond traditional visual paradigm, Vision-Language Model (VLM) has been extensively explored to boost this field. However, in currently-existing VLM-based FSAD schemes, almost all perform anomaly inference only by pairwise feature matching, ignoring structural dependencies and global consistency. To further redound to FSAD via VLM, we propose a Heterogeneous Hypergraph Vision-Language Reasoning (H2VLR) framework. It reformulates the FSAD as a high-order inference problem of visual-semantic relations, by jointly modeling visual regions and semantic concepts in a unified hypergraph. Experimental comparisons verify the effectiveness and advantages of H2VLR. It could often achieve state-of-the-art (SOTA) performance on representative industrial and medical benchmarks. Our code will be released upon acceptance.
Weakly-supervised Contrastive Learning with Quantity Prompts for Moving Infrared Small Target Detection
Jul 03, 2025Different from general object detection, moving infrared small target detection faces huge challenges due to tiny target size and weak background contrast.Currently, most existing methods are fully-supervised, heavily relying on a large number of manual target-wise annotations. However, manually annotating video sequences is often expensive and time-consuming, especially for low-quality infrared frame images. Inspired by general object detection, non-fully supervised strategies ($e.g.$, weakly supervised) are believed to be potential in reducing annotation requirements. To break through traditional fully-supervised frameworks, as the first exploration work, this paper proposes a new weakly-supervised contrastive learning (WeCoL) scheme, only requires simple target quantity prompts during model training.Specifically, in our scheme, based on the pretrained segment anything model (SAM), a potential target mining strategy is designed to integrate target activation maps and multi-frame energy accumulation.Besides, contrastive learning is adopted to further improve the reliability of pseudo-labels, by calculating the similarity between positive and negative samples in feature subspace.Moreover, we propose a long-short term motion-aware learning scheme to simultaneously model the local motion patterns and global motion trajectory of small targets.The extensive experiments on two public datasets (DAUB and ITSDT-15K) verify that our weakly-supervised scheme could often outperform early fully-supervised methods. Even, its performance could reach over 90\% of state-of-the-art (SOTA) fully-supervised ones.
Triple-domain Feature Learning with Frequency-aware Memory Enhancement for Moving Infrared Small Target Detection
Jun 11, 2024Moving infrared small target detection presents significant challenges due to tiny target sizes and low contrast against backgrounds. Currently-existing methods primarily focus on extracting target features only from the spatial-temporal domain. For further enhancing feature representation, more information domains such as frequency are believed to be potentially valuable. To extend target feature learning, we propose a new Triple-domain Strategy (Tridos) with the frequency-aware memory enhancement on the spatial-temporal domain. In our scheme, it effectively detaches and enhances frequency features by a local-global frequency-aware module with Fourier transform. Inspired by the human visual system, our memory enhancement aims to capture the target spatial relations between video frames. Furthermore, it encodes temporal dynamics motion features via differential learning and residual enhancing. Additionally, we further design a residual compensation unit to reconcile possible cross-domain feature mismatches. To our best knowledge, our Tridos is the first work to explore target feature learning comprehensively in spatial-temporal-frequency domains. The extensive experiments on three datasets (DAUB, ITSDT-15K, and IRDST) validate that our triple-domain learning scheme could be obviously superior to state-of-the-art ones. Source codes are available at https://github.com/UESTC-nnLab/Tridos.
A Label Correction Algorithm Using Prior Information for Automatic and Accurate Geospatial Object Recognition
Dec 10, 2021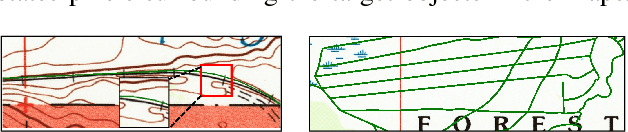
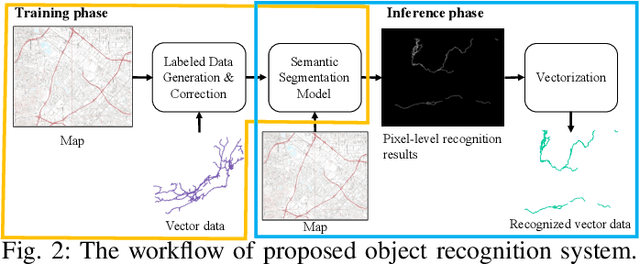

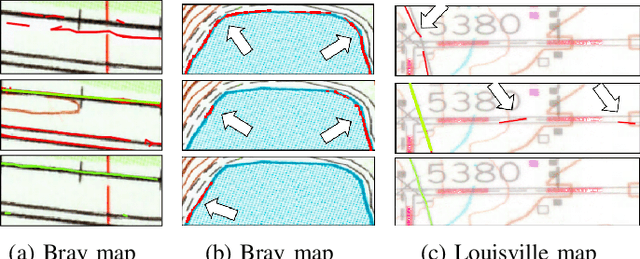
Thousands of scanned historical topographic maps contain valuable information covering long periods of time, such as how the hydrography of a region has changed over time. Efficiently unlocking the information in these maps requires training a geospatial objects recognition system, which needs a large amount of annotated data. Overlapping geo-referenced external vector data with topographic maps according to their coordinates can annotate the desired objects' locations in the maps automatically. However, directly overlapping the two datasets causes misaligned and false annotations because the publication years and coordinate projection systems of topographic maps are different from the external vector data. We propose a label correction algorithm, which leverages the color information of maps and the prior shape information of the external vector data to reduce misaligned and false annotations. The experiments show that the precision of annotations from the proposed algorithm is 10% higher than the annotations from a state-of-the-art algorithm. Consequently, recognition results using the proposed algorithm's annotations achieve 9% higher correctness than using the annotations from the state-of-the-art algorithm.
Guided Generative Models using Weak Supervision for Detecting Object Spatial Arrangement in Overhead Images
Dec 10, 2021
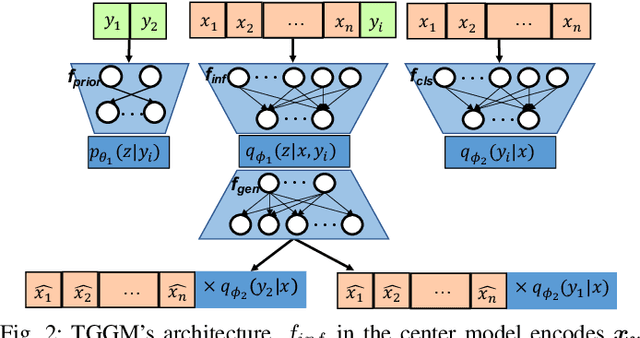
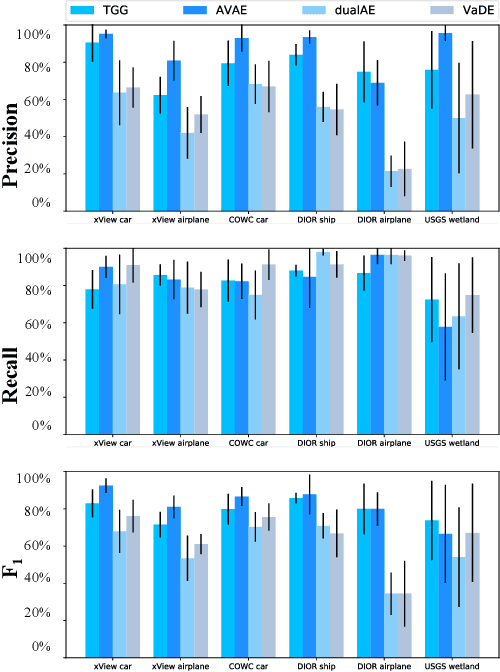

The increasing availability and accessibility of numerous overhead images allows us to estimate and assess the spatial arrangement of groups of geospatial target objects, which can benefit many applications, such as traffic monitoring and agricultural monitoring. Spatial arrangement estimation is the process of identifying the areas which contain the desired objects in overhead images. Traditional supervised object detection approaches can estimate accurate spatial arrangement but require large amounts of bounding box annotations. Recent semi-supervised clustering approaches can reduce manual labeling but still require annotations for all object categories in the image. This paper presents the target-guided generative model (TGGM), under the Variational Auto-encoder (VAE) framework, which uses Gaussian Mixture Models (GMM) to estimate the distributions of both hidden and decoder variables in VAE. Modeling both hidden and decoder variables by GMM reduces the required manual annotations significantly for spatial arrangement estimation. Unlike existing approaches that the training process can only update the GMM as a whole in the optimization iterations (e.g., a "minibatch"), TGGM allows the update of individual GMM components separately in the same optimization iteration. Optimizing GMM components separately allows TGGM to exploit the semantic relationships in spatial data and requires only a few labels to initiate and guide the generative process. Our experiments shows that TGGM achieves results comparable to the state-of-the-art semi-supervised methods and outperforms unsupervised methods by 10% based on the $F_{1}$ scores, while requiring significantly fewer labeled data.