 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the automated large-scale reconstruction of past road networks from historical maps
Feb 11, 2022


Transportation infrastructure, such as road or railroad networks, represent a fundamental component of our civilization. For sustainable planning and informed decision making, a thorough understanding of the long-term evolution of transportation infrastructure such as road networks is crucial. However, spatially explicit, multi-temporal road network data covering large spatial extents are scarce and rarely available prior to the 2000s. Herein, we propose a framework that employs increasingly available scanned and georeferenced historical map series to reconstruct past road networks, by integrating abundant, contemporary road network data and color information extracted from historical maps. Specifically, our method uses contemporary road segments as analytical units and extracts historical roads by inferring their existence in historical map series based on image processing and clustering techniques. We tested our method on over 300,000 road segments representing more than 50,000 km of the road network in the United States, extending across three study areas that cover 53 historical topographic map sheets dated between 1890 and 1950. We evaluated our approach by comparison to other historical datasets and against manually created reference data, achieving F-1 scores of up to 0.95, and showed that the extracted road network statistics are highly plausible over time, i.e., following general growth patterns. We demonstrated that contemporary geospatial data integrated with information extracted from historical map series open up new avenues for the quantitative analysis of long-term urbanization processes and landscape changes far beyond the era of operational remote sensing and digital cartography.
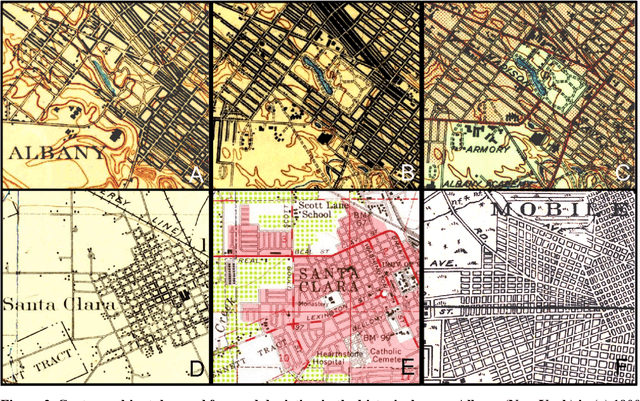
Synthetic Map Generation to Provide Unlimited Training Data for Historical Map Text Detection
Dec 12, 2021
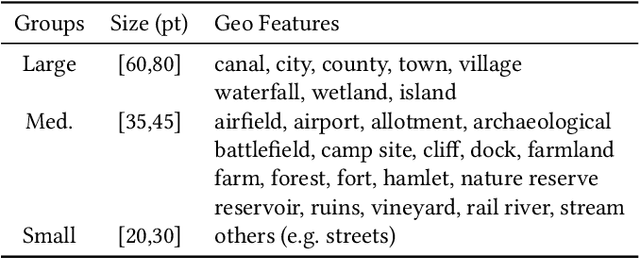

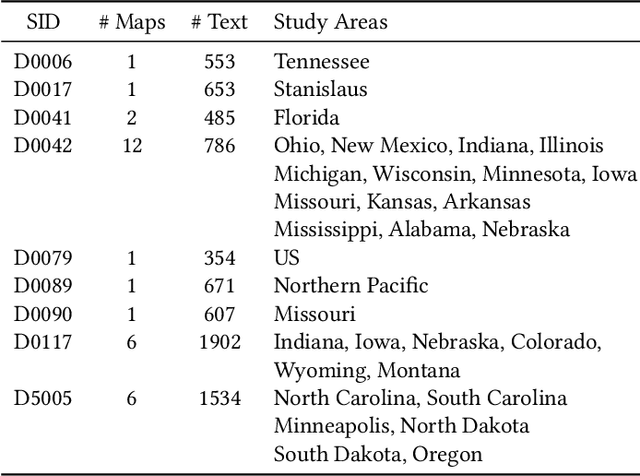
Many historical map sheets are publicly available for studies that require long-term historical geographic data. The cartographic design of these maps includes a combination of map symbols and text labels. Automatically reading text labels from map images could greatly speed up the map interpretation and helps generate rich metadata describing the map content. Many text detection algorithms have been proposed to locate text regions in map images automatically, but most of the algorithms are trained on out-ofdomain datasets (e.g., scenic images). Training data determines the quality of machine learning models, and manually annotating text regions in map images is labor-extensive and time-consuming. On the other hand, existing geographic data sources, such as Open- StreetMap (OSM), contain machine-readable map layers, which allow us to separate out the text layer and obtain text label annotations easily. However, the cartographic styles between OSM map tiles and historical maps are significantly different. This paper proposes a method to automatically generate an unlimited amount of annotated historical map images for training text detection models. We use a style transfer model to convert contemporary map images into historical style and place text labels upon them. We show that the state-of-the-art text detection models (e.g., PSENet) can benefit from the synthetic historical maps and achieve significant improvement for historical map text detection.
A Label Correction Algorithm Using Prior Information for Automatic and Accurate Geospatial Object Recognition
Dec 10, 2021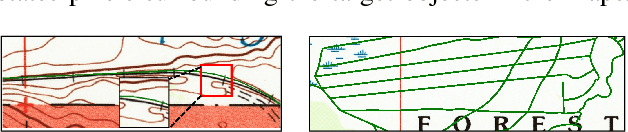
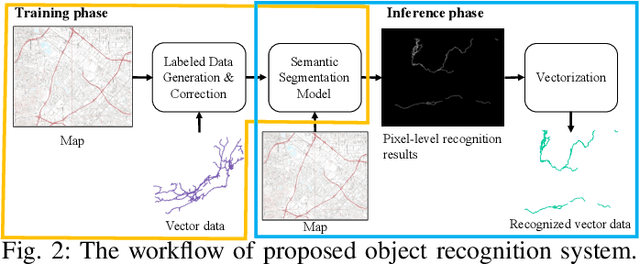

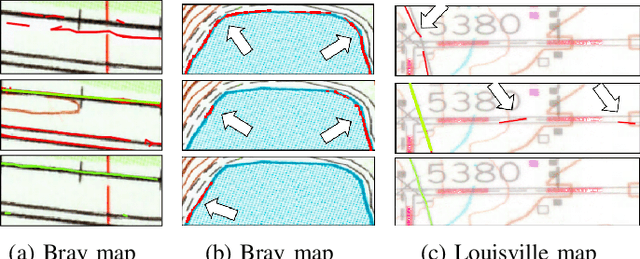
Thousands of scanned historical topographic maps contain valuable information covering long periods of time, such as how the hydrography of a region has changed over time. Efficiently unlocking the information in these maps requires training a geospatial objects recognition system, which needs a large amount of annotated data. Overlapping geo-referenced external vector data with topographic maps according to their coordinates can annotate the desired objects' locations in the maps automatically. However, directly overlapping the two datasets causes misaligned and false annotations because the publication years and coordinate projection systems of topographic maps are different from the external vector data. We propose a label correction algorithm, which leverages the color information of maps and the prior shape information of the external vector data to reduce misaligned and false annotations. The experiments show that the precision of annotations from the proposed algorithm is 10% higher than the annotations from a state-of-the-art algorithm. Consequently, recognition results using the proposed algorithm's annotations achieve 9% higher correctness than using the annotations from the state-of-the-art algorithm.
Guided Generative Models using Weak Supervision for Detecting Object Spatial Arrangement in Overhead Images
Dec 10, 2021
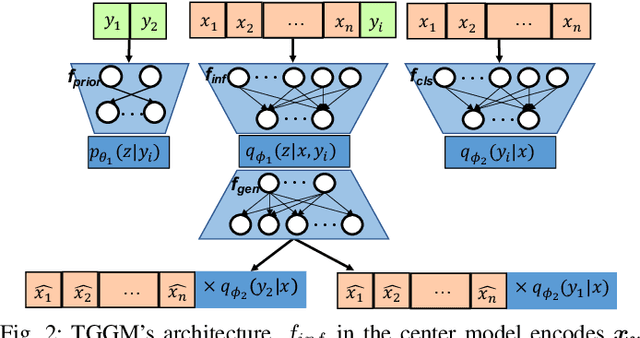
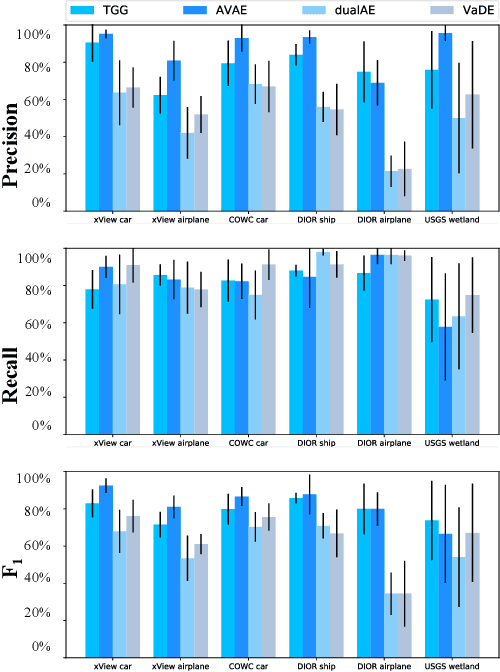

The increasing availability and accessibility of numerous overhead images allows us to estimate and assess the spatial arrangement of groups of geospatial target objects, which can benefit many applications, such as traffic monitoring and agricultural monitoring. Spatial arrangement estimation is the process of identifying the areas which contain the desired objects in overhead images. Traditional supervised object detection approaches can estimate accurate spatial arrangement but require large amounts of bounding box annotations. Recent semi-supervised clustering approaches can reduce manual labeling but still require annotations for all object categories in the image. This paper presents the target-guided generative model (TGGM), under the Variational Auto-encoder (VAE) framework, which uses Gaussian Mixture Models (GMM) to estimate the distributions of both hidden and decoder variables in VAE. Modeling both hidden and decoder variables by GMM reduces the required manual annotations significantly for spatial arrangement estimation. Unlike existing approaches that the training process can only update the GMM as a whole in the optimization iterations (e.g., a "minibatch"), TGGM allows the update of individual GMM components separately in the same optimization iteration. Optimizing GMM components separately allows TGGM to exploit the semantic relationships in spatial data and requires only a few labels to initiate and guide the generative process. Our experiments shows that TGGM achieves results comparable to the state-of-the-art semi-supervised methods and outperforms unsupervised methods by 10% based on the $F_{1}$ scores, while requiring significantly fewer labeled data.
An Automatic Approach for Generating Rich, Linked Geo-Metadata from Historical Map Images
Dec 03, 2021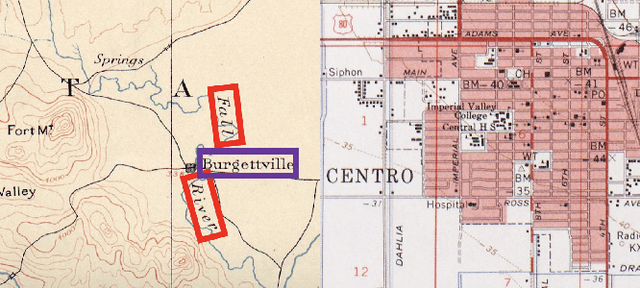
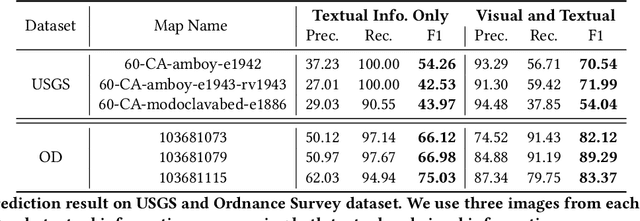
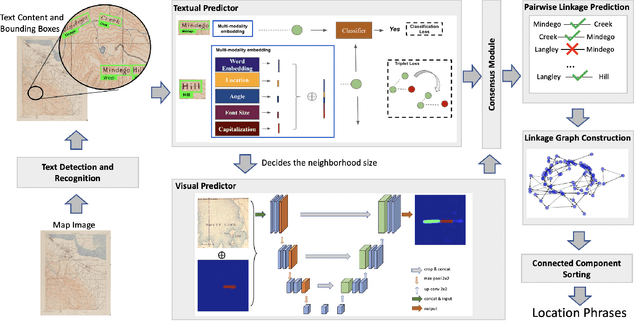
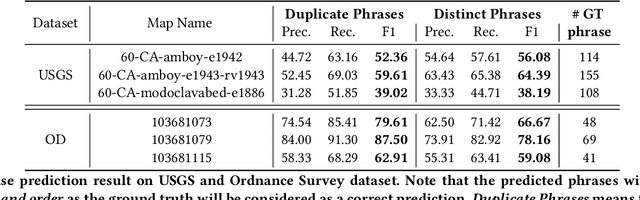
Historical maps contain detailed geographic information difficult to find elsewhere covering long-periods of time (e.g., 125 years for the historical topographic maps in the US). However, these maps typically exist as scanned images without searchable metadata. Existing approaches making historical maps searchable rely on tedious manual work (including crowd-sourcing) to generate the metadata (e.g., geolocations and keywords). Optical character recognition (OCR) software could alleviate the required manual work, but the recognition results are individual words instead of location phrases (e.g., "Black" and "Mountain" vs. "Black Mountain"). This paper presents an end-to-end approach to address the real-world problem of finding and indexing historical map images. This approach automatically processes historical map images to extract their text content and generates a set of metadata that is linked to large external geospatial knowledge bases. The linked metadata in the RDF (Resource Description Framework) format support complex queries for finding and indexing historical maps, such as retrieving all historical maps covering mountain peaks higher than 1,000 meters in California. We have implemented the approach in a system called mapKurator. We have evaluated mapKurator using historical maps from several sources with various map styles, scales, and coverage. Our results show significant improvement over the state-of-the-art methods. The code has been made publicly available as modules of the Kartta Labs project at https://github.com/kartta-labs/Project.
Learning the Semantics of Structured Data Sources
Jan 16, 2016
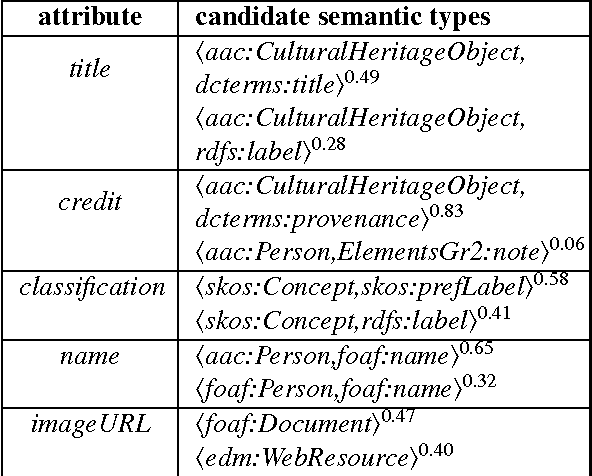


Information sources such as relational databases, spreadsheets, XML, JSON, and Web APIs contain a tremendous amount of structured data that can be leveraged to build and augment knowledge graphs. However, they rarely provide a semantic model to describe their contents. Semantic models of data sources represent the implicit meaning of the data by specifying the concepts and the relationships within the data. Such models are the key ingredients to automatically publish the data into knowledge graphs. Manually modeling the semantics of data sources requires significant effort and expertise, and although desirable, building these models automatically is a challenging problem. Most of the related work focuses on semantic annotation of the data fields (source attributes). However, constructing a semantic model that explicitly describes the relationships between the attributes in addition to their semantic types is critical. We present a novel approach that exploits the knowledge from a domain ontology and the semantic models of previously modeled sources to automatically learn a rich semantic model for a new source. This model represents the semantics of the new source in terms of the concepts and relationships defined by the domain ontology. Given some sample data from the new source, we leverage the knowledge in the domain ontology and the known semantic models to construct a weighted graph that represents the space of plausible semantic models for the new source. Then, we compute the top k candidate semantic models and suggest to the user a ranked list of the semantic models for the new source. The approach takes into account user corrections to learn more accurate semantic models on future data sources. Our evaluation shows that our method generates expressive semantic models for data sources and services with minimal user input. ...
Constructing Reference Sets from Unstructured, Ungrammatical Text
Jan 16, 2014

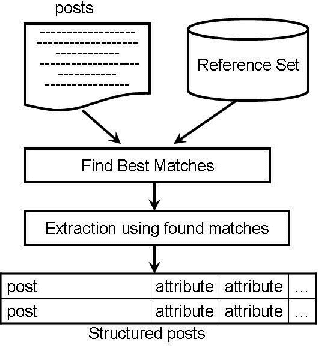

Vast amounts of text on the Web are unstructured and ungrammatical, such as classified ads, auction listings, forum postings, etc. We call such text "posts." Despite their inconsistent structure and lack of grammar, posts are full of useful information. This paper presents work on semi-automatically building tables of relational information, called "reference sets," by analyzing such posts directly. Reference sets can be applied to a number of tasks such as ontology maintenance and information extraction. Our reference-set construction method starts with just a small amount of background knowledge, and constructs tuples representing the entities in the posts to form a reference set. We also describe an extension to this approach for the special case where even this small amount of background knowledge is impossible to discover and use. To evaluate the utility of the machine-constructed reference sets, we compare them to manually constructed reference sets in the context of reference-set-based information extraction. Our results show the reference sets constructed by our method outperform manually constructed reference sets. We also compare the reference-set-based extraction approach using the machine-constructed reference set to supervised extraction approaches using generic features. These results demonstrate that using machine-constructed reference sets outperforms the supervised methods, even though the supervised methods require training data.