 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMON: An LLM-native Markup Language to Leverage Structure and Semantics at the LLM Interface
Mar 23, 2026Textual Large Language Models (LLMs) provide a simple and familiar interface: a string of text is used for both input and output. However, the information conveyed to an LLM often has a richer structure and semantics, which is not conveyed in a string. For example, most prompts contain both instructions ("Summarize this paper into a paragraph") and data (the paper to summarize), but these are usually not distinguished when passed to the model. This can lead to model confusion and security risks, such as prompt injection attacks. This work addresses this shortcoming by introducing an LLM-native mark-up language, LLMON (LLM Object Notation, pronounced "Lemon"), that enables the structure and semantic metadata of the text to be communicated in a natural way to an LLM. This information can then be used during model training, model prompting, and inference implementation, leading to improvements in model accuracy, safety, and security. This is analogous to how programming language types can be used for many purposes, such as static checking, code generation, dynamic checking, and IDE highlighting. We discuss the general design requirements of an LLM-native markup language, introduce the LLMON markup language and show how it meets these design requirements, describe how the information contained in a LLMON artifact can benefit model training and inference implementation, and provide some preliminary empirical evidence of its value for both of these use cases. We also discuss broader issues and research opportunities that are enabled with an LLM-native approach.
Adaptive Decoding via Test-Time Policy Learning for Self-Improving Generation
Mar 19, 2026Decoding strategies largely determine the quality of Large Language Model (LLM) outputs, yet widely used heuristics such as greedy or fixed temperature/top-p decoding are static and often task-agnostic, leading to suboptimal or inconsistent generation quality across domains that demand stylistic or structural flexibility. We introduce a reinforcement learning-based decoder sampler that treats decoding as sequential decision-making and learns a lightweight policy to adjust sampling parameters at test-time while keeping LLM weights frozen. We evaluated summarization datasets including BookSum, arXiv, and WikiHow using Granite-3.3-2B and Qwen-2.5-0.5B. Our policy sampler consistently outperforms greedy and static baselines, achieving relative gains of up to +88% (BookSum, Granite) and +79% (WikiHow, Qwen). Reward ablations show that overlap-only objectives underperform compared to composite rewards, while structured shaping terms (length, coverage, repetition, completeness) enable stable and sustained improvements. These findings highlight reinforcement learning as a practical mechanism for test-time adaptation in decoding, enabling domain-aware and user-controllable generation without retraining large models.
Evaluating Ill-Defined Tasks in Large Language Models
Mar 17, 2026Many evaluations of Large Language Models (LLMs) target tasks that are inherently ill-defined, with unclear input and output spaces and ambiguous success criteria. We analyze why existing evaluation benchmarks and metrics fail to provide reliable or diagnostic signals of model capability for such tasks. We examine two case studies: Complex Instruction Following (CIF), where we identify recurring issues including limited coverage of real-world instruction complexity, sensitivity to instruction phrasing, inconsistent and non-comparable metrics, and instability introduced by LLM-based judges; and Natural Language to Mermaid Sequence Diagrams (NL2Mermaid), where we show how multi-faceted evaluation criteria can yield actionable insights beyond aggregate scores. Together, these case studies show that current evaluations frequently conflate distinct failure modes, yielding scores that are unstable, non-diagnostic, and difficult to act upon. Our findings expose fundamental limitations in existing evaluation practices for ill-defined tasks and motivate more robust, interpretable evaluation designs.
MermaidSeqBench: An Evaluation Benchmark for LLM-to-Mermaid Sequence Diagram Generation
Nov 18, 2025Large language models (LLMs) have demonstrated excellent capabilities in generating structured diagrams from natural language descriptions. In particular, they have shown great promise in generating sequence diagrams for software engineering, typically represented in a text-based syntax such as Mermaid. However, systematic evaluations in this space remain underdeveloped as there is a lack of existing benchmarks to assess the LLM's correctness in this task. To address this shortcoming, we introduce MermaidSeqBench, a human-verified and LLM-synthetically-extended benchmark for assessing an LLM's capabilities in generating Mermaid sequence diagrams from textual prompts. The benchmark consists of a core set of 132 samples, starting from a small set of manually crafted and verified flows. These were expanded via a hybrid methodology combining human annotation, in-context LLM prompting, and rule-based variation generation. Our benchmark uses an LLM-as-a-judge model to assess Mermaid sequence diagram generation across fine-grained metrics, including syntax correctness, activation handling, error handling, and practical usability. We perform initial evaluations on numerous state-of-the-art LLMs and utilize multiple LLM judge models to demonstrate the effectiveness and flexibility of our benchmark. Our results reveal significant capability gaps across models and evaluation modes. Our proposed benchmark provides a foundation for advancing research in structured diagram generation and for developing more rigorous, fine-grained evaluation methodologies.
An Automatic Approach for Generating Rich, Linked Geo-Metadata from Historical Map Images
Dec 03, 2021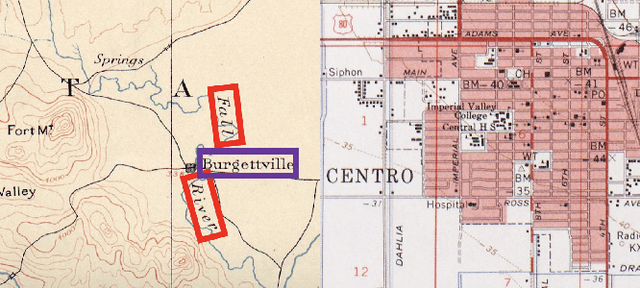
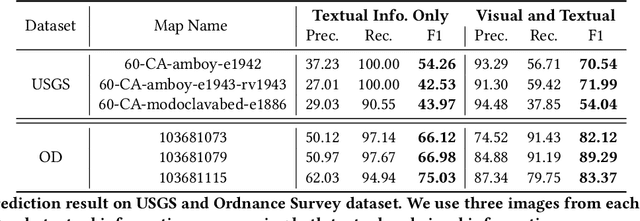
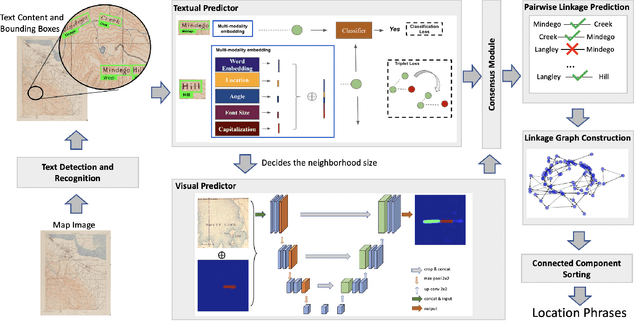
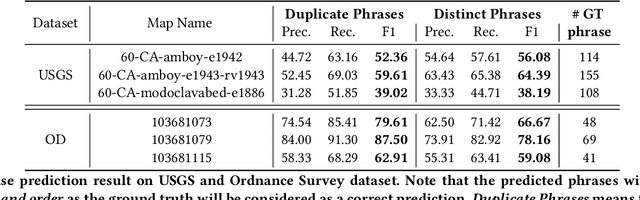
Historical maps contain detailed geographic information difficult to find elsewhere covering long-periods of time (e.g., 125 years for the historical topographic maps in the US). However, these maps typically exist as scanned images without searchable metadata. Existing approaches making historical maps searchable rely on tedious manual work (including crowd-sourcing) to generate the metadata (e.g., geolocations and keywords). Optical character recognition (OCR) software could alleviate the required manual work, but the recognition results are individual words instead of location phrases (e.g., "Black" and "Mountain" vs. "Black Mountain"). This paper presents an end-to-end approach to address the real-world problem of finding and indexing historical map images. This approach automatically processes historical map images to extract their text content and generates a set of metadata that is linked to large external geospatial knowledge bases. The linked metadata in the RDF (Resource Description Framework) format support complex queries for finding and indexing historical maps, such as retrieving all historical maps covering mountain peaks higher than 1,000 meters in California. We have implemented the approach in a system called mapKurator. We have evaluated mapKurator using historical maps from several sources with various map styles, scales, and coverage. Our results show significant improvement over the state-of-the-art methods. The code has been made publicly available as modules of the Kartta Labs project at https://github.com/kartta-labs/Project.
Viola: A Topic Agnostic Generate-and-Rank Dialogue System
Aug 25, 2021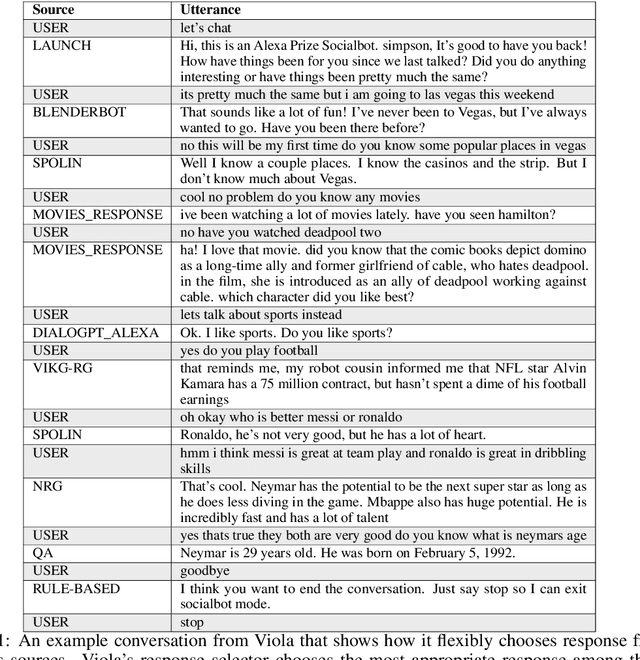
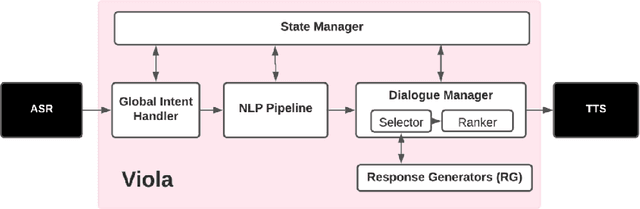
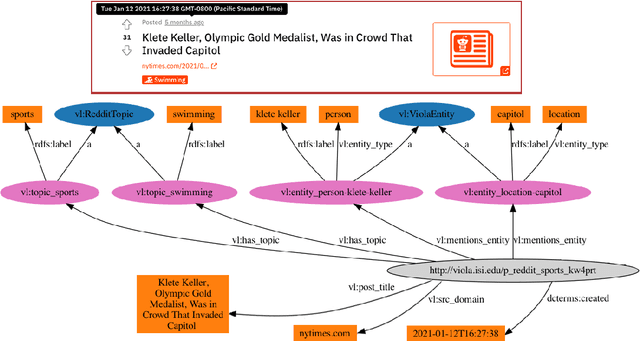
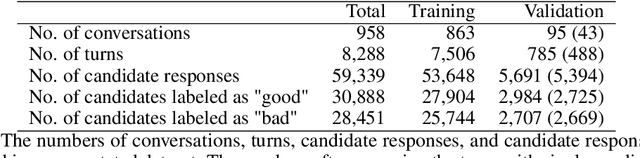
We present Viola, an open-domain dialogue system for spoken conversation that uses a topic-agnostic dialogue manager based on a simple generate-and-rank approach. Leveraging recent advances of generative dialogue systems powered by large language models, Viola fetches a batch of response candidates from various neural dialogue models trained with different datasets and knowledge-grounding inputs. Additional responses originating from template-based generators are also considered, depending on the user's input and detected entities. The hand-crafted generators build on a dynamic knowledge graph injected with rich content that is crawled from the web and automatically processed on a daily basis. Viola's response ranker is a fine-tuned polyencoder that chooses the best response given the dialogue history. While dedicated annotations for the polyencoder alone can indirectly steer it away from choosing problematic responses, we add rule-based safety nets to detect neural degeneration and a dedicated classifier to filter out offensive content. We analyze conversations that Viola took part in for the Alexa Prize Socialbot Grand Challenge 4 and discuss the strengths and weaknesses of our approach. Lastly, we suggest future work with a focus on curating conversation data specifcially for socialbots that will contribute towards a more robust data-driven socialbot.