 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Adaptive Coverage for Synthetic Training Data
Apr 20, 2025Synthetic training data generation with Large Language Models (LLMs) like Google's Gemma and OpenAI's GPT offer a promising solution to the challenge of obtaining large, labeled datasets for training classifiers. When rapid model deployment is critical, such as in classifying emerging social media trends or combating new forms of online abuse tied to current events, the ability to generate training data is invaluable. While prior research has examined the comparability of synthetic data to human-labeled data, this study introduces a novel sampling algorithm, based on the maximum coverage problem, to select a representative subset from a synthetically generated dataset. Our results demonstrate that training a classifier on this contextually sampled subset achieves superior performance compared to training on the entire dataset. This "less is more" approach not only improves accuracy but also reduces the volume of data required, leading to potentially more efficient model fine-tuning.
The ParClusterers Benchmark Suite (PCBS): A Fine-Grained Analysis of Scalable Graph Clustering
Nov 15, 2024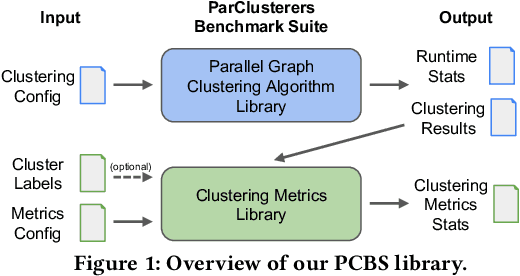
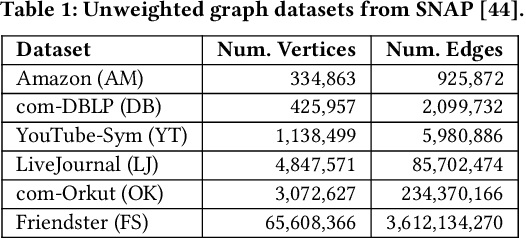
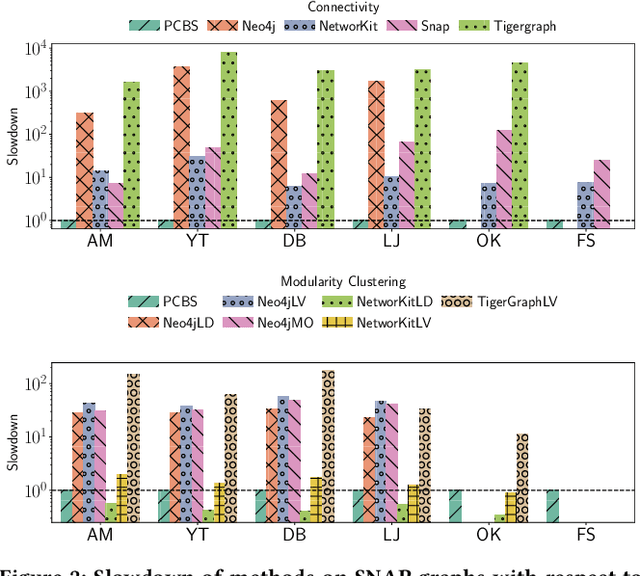
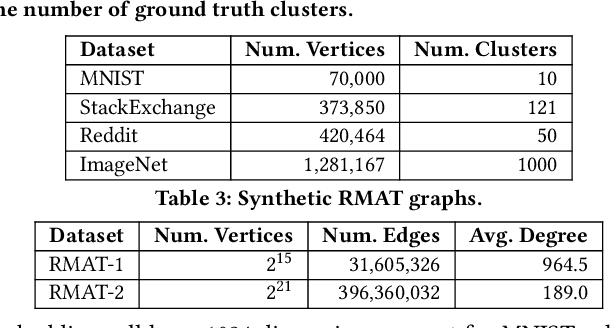
We introduce the ParClusterers Benchmark Suite (PCBS) -- a collection of highly scalable parallel graph clustering algorithms and benchmarking tools that streamline comparing different graph clustering algorithms and implementations. The benchmark includes clustering algorithms that target a wide range of modern clustering use cases, including community detection, classification, and dense subgraph mining. The benchmark toolkit makes it easy to run and evaluate multiple instances of different clustering algorithms, which can be useful for fine-tuning the performance of clustering on a given task, and for comparing different clustering algorithms based on different metrics of interest, including clustering quality and running time. Using PCBS, we evaluate a broad collection of real-world graph clustering datasets. Somewhat surprisingly, we find that the best quality results are obtained by algorithms that not included in many popular graph clustering toolkits. The PCBS provides a standardized way to evaluate and judge the quality-performance tradeoffs of the active research area of scalable graph clustering algorithms. We believe it will help enable fair, accurate, and nuanced evaluation of graph clustering algorithms in the future.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Two-Step Active Learning for Instance Segmentation with Uncertainty and Diversity Sampling
Sep 28, 2023


Training high-quality instance segmentation models requires an abundance of labeled images with instance masks and classifications, which is often expensive to procure. Active learning addresses this challenge by striving for optimum performance with minimal labeling cost by selecting the most informative and representative images for labeling. Despite its potential, active learning has been less explored in instance segmentation compared to other tasks like image classification, which require less labeling. In this study, we propose a post-hoc active learning algorithm that integrates uncertainty-based sampling with diversity-based sampling. Our proposed algorithm is not only simple and easy to implement, but it also delivers superior performance on various datasets. Its practical application is demonstrated on a real-world overhead imagery dataset, where it increases the labeling efficiency fivefold.
Agile Modeling: Image Classification with Domain Experts in the Loop
Feb 25, 2023

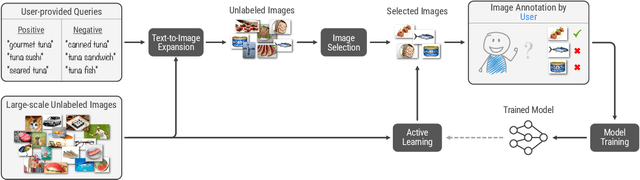
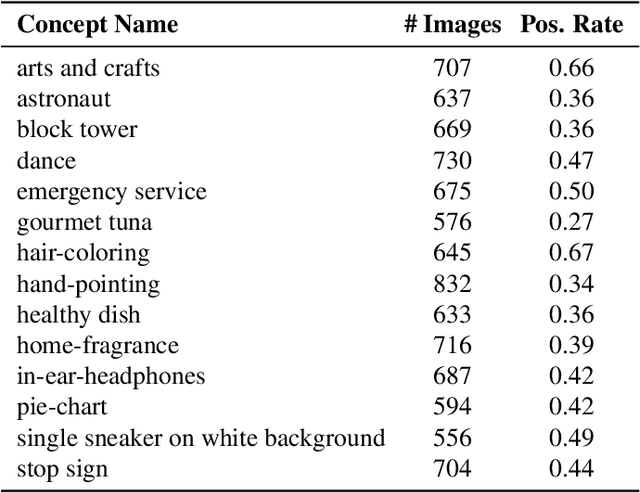
Machine learning is not readily accessible to domain experts from many fields, blocked by issues ranging from data mining to model training. We argue that domain experts should be at the center of the modeling process, and we introduce the "Agile Modeling" problem: the process of turning any visual concept from an idea into a well-trained ML classifier through a human-in-the-loop interaction driven by the domain expert in a way that minimizes domain expert time. We propose a solution to the problem that enables domain experts to create classifiers in real-time and build upon recent advances in image-text co-embeddings such as CLIP or ALIGN to implement it. We show the feasibility of this solution through live experiments with 14 domain experts, each modeling their own concept. Finally, we compare a domain expert driven process with the traditional crowdsourcing paradigm and find that difficult concepts see pronounced improvements with domain experts.
An Automatic Approach for Generating Rich, Linked Geo-Metadata from Historical Map Images
Dec 03, 2021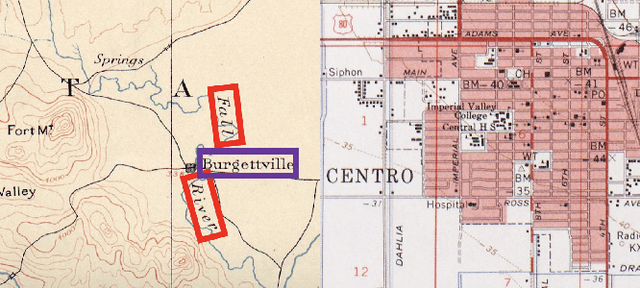
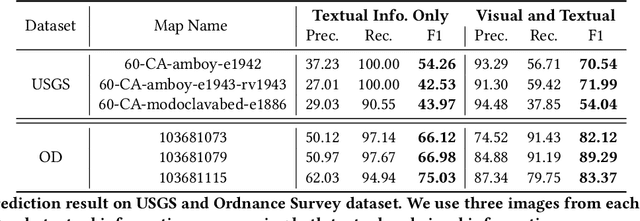
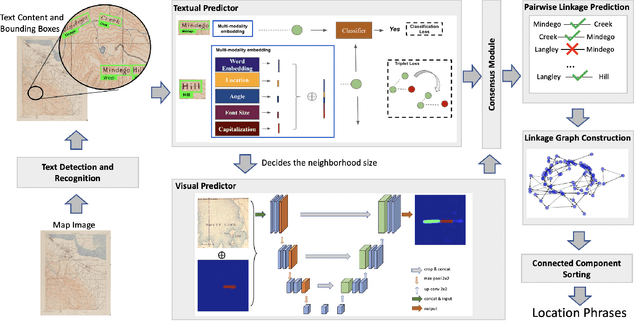
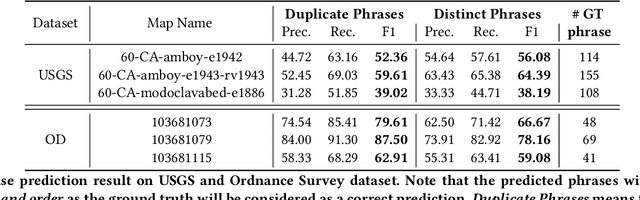
Historical maps contain detailed geographic information difficult to find elsewhere covering long-periods of time (e.g., 125 years for the historical topographic maps in the US). However, these maps typically exist as scanned images without searchable metadata. Existing approaches making historical maps searchable rely on tedious manual work (including crowd-sourcing) to generate the metadata (e.g., geolocations and keywords). Optical character recognition (OCR) software could alleviate the required manual work, but the recognition results are individual words instead of location phrases (e.g., "Black" and "Mountain" vs. "Black Mountain"). This paper presents an end-to-end approach to address the real-world problem of finding and indexing historical map images. This approach automatically processes historical map images to extract their text content and generates a set of metadata that is linked to large external geospatial knowledge bases. The linked metadata in the RDF (Resource Description Framework) format support complex queries for finding and indexing historical maps, such as retrieving all historical maps covering mountain peaks higher than 1,000 meters in California. We have implemented the approach in a system called mapKurator. We have evaluated mapKurator using historical maps from several sources with various map styles, scales, and coverage. Our results show significant improvement over the state-of-the-art methods. The code has been made publicly available as modules of the Kartta Labs project at https://github.com/kartta-labs/Project.
Kartta Labs: Collaborative Time Travel
Oct 07, 2020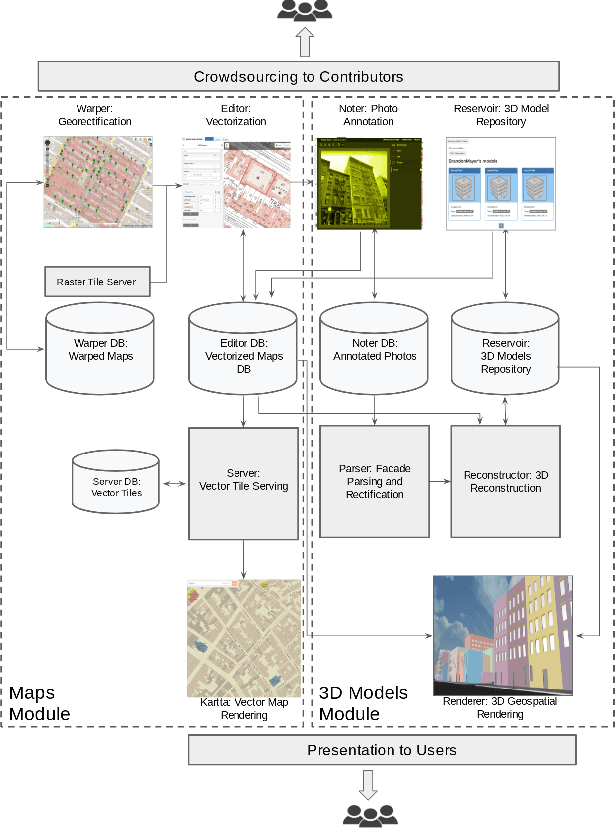
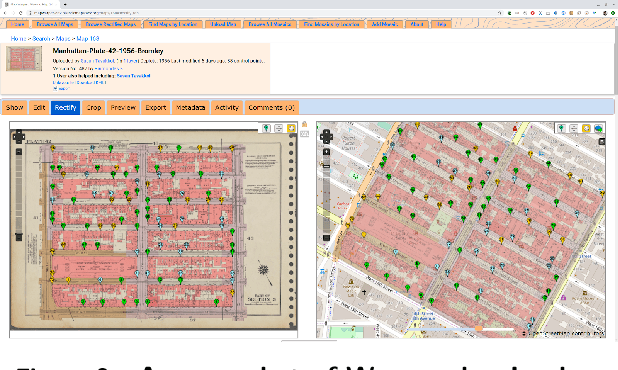
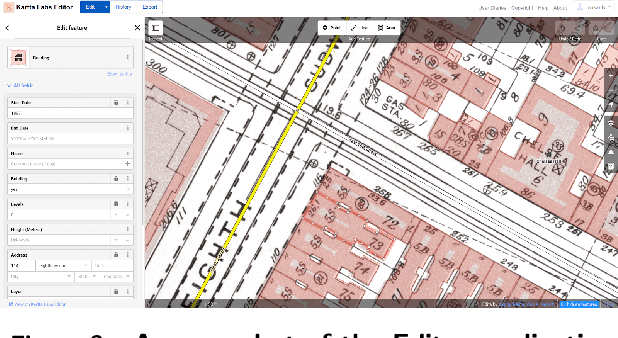
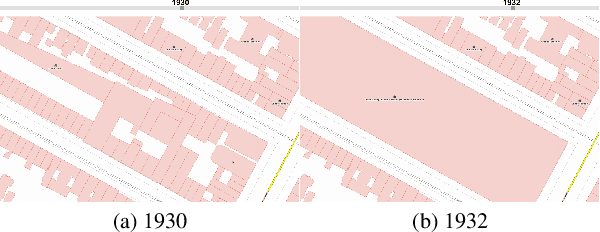
We introduce the modular and scalable design of Kartta Labs, an open source, open data, and scalable system for virtually reconstructing cities from historical maps and photos. Kartta Labs relies on crowdsourcing and artificial intelligence consisting of two major modules: Maps and 3D models. Each module, in turn, consists of sub-modules that enable the system to reconstruct a city from historical maps and photos. The result is a spatiotemporal reference that can be used to integrate various collected data (curated, sensed, or crowdsourced) for research, education, and entertainment purposes. The system empowers the users to experience collaborative time travel such that they work together to reconstruct the past and experience it on an open source and open data platform.