 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGovScape: A Public Multimodal Search System for 70 Million Pages of Government PDFs
Nov 14, 2025Efforts over the past three decades have produced web archives containing billions of webpage snapshots and petabytes of data. The End of Term Web Archive alone contains, among other file types, millions of PDFs produced by the federal government. While preservation with web archives has been successful, significant challenges for access and discoverability remain. For example, current affordances for browsing the End of Term PDFs are limited to downloading and browsing individual PDFs, as well as performing basic keyword search across them. In this paper, we introduce GovScape, a public search system that supports multimodal searches across 10,015,993 federal government PDFs from the 2020 End of Term crawl (70,958,487 total PDF pages) - to our knowledge, all renderable PDFs in the 2020 crawl that are 50 pages or under. GovScape supports four primary forms of search over these 10 million PDFs: in addition to providing (1) filter conditions over metadata facets including domain and crawl date and (2) exact text search against the PDF text, we provide (3) semantic text search and (4) visual search against the PDFs across individual pages, enabling users to structure queries such as "redacted documents" or "pie charts." We detail the constituent components of GovScape, including the search affordances, embedding pipeline, system architecture, and open source codebase. Significantly, the total estimated compute cost for GovScape's pre-processing pipeline for 10 million PDFs was approximately $1,500, equivalent to 47,000 PDF pages per dollar spent on compute, demonstrating the potential for immediate scalability. Accordingly, we outline steps that we have already begun pursuing toward multimodal search at the 100+ million PDF scale. GovScape can be found at https://www.govscape.net.
Kartta Labs: Collaborative Time Travel
Oct 07, 2020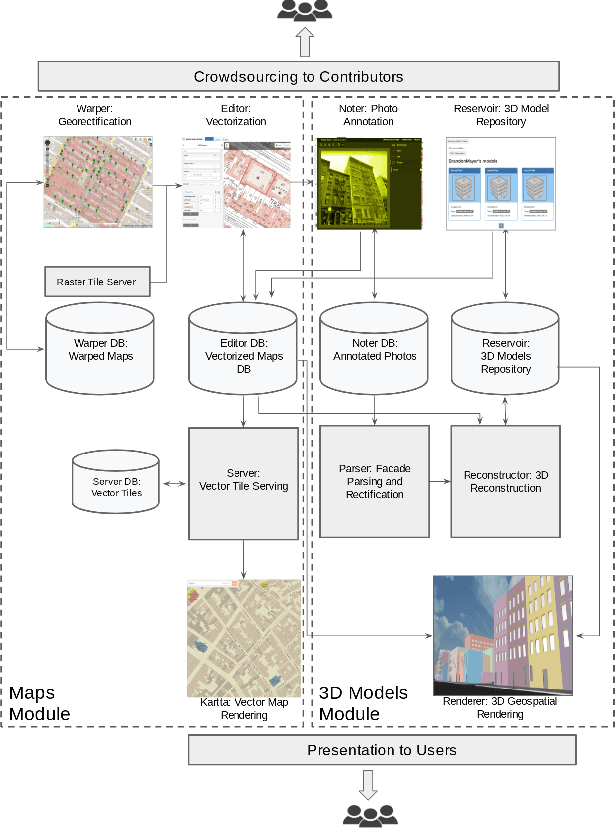
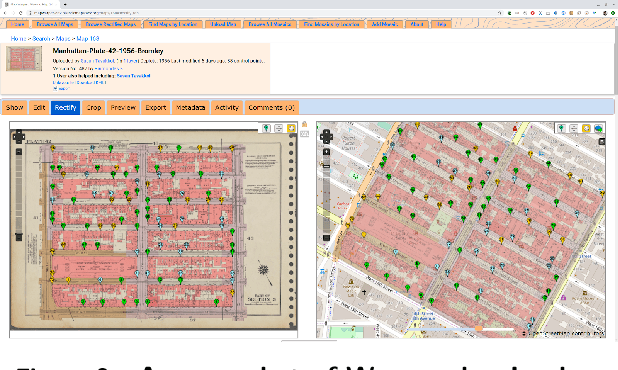
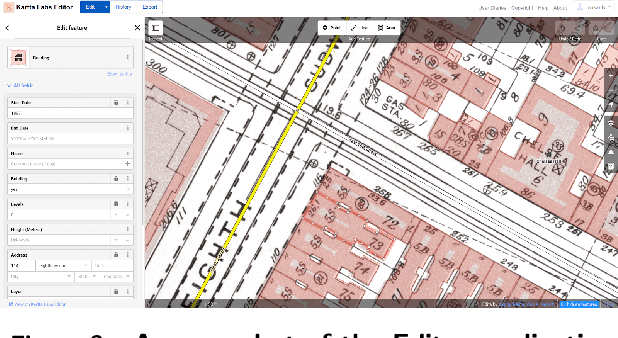
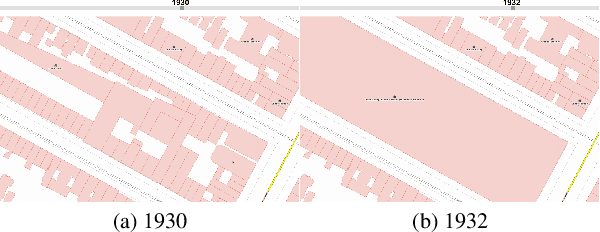
We introduce the modular and scalable design of Kartta Labs, an open source, open data, and scalable system for virtually reconstructing cities from historical maps and photos. Kartta Labs relies on crowdsourcing and artificial intelligence consisting of two major modules: Maps and 3D models. Each module, in turn, consists of sub-modules that enable the system to reconstruct a city from historical maps and photos. The result is a spatiotemporal reference that can be used to integrate various collected data (curated, sensed, or crowdsourced) for research, education, and entertainment purposes. The system empowers the users to experience collaborative time travel such that they work together to reconstruct the past and experience it on an open source and open data platform.
Identifying Documents In-Scope of a Collection from Web Archives
Sep 02, 2020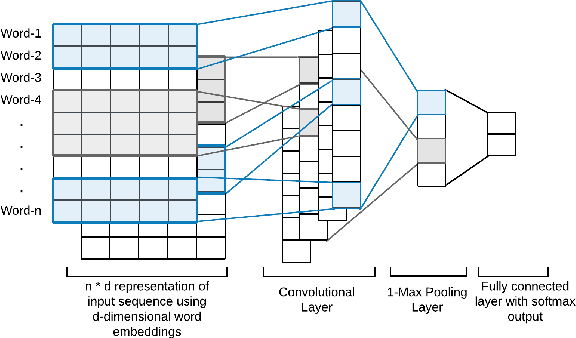

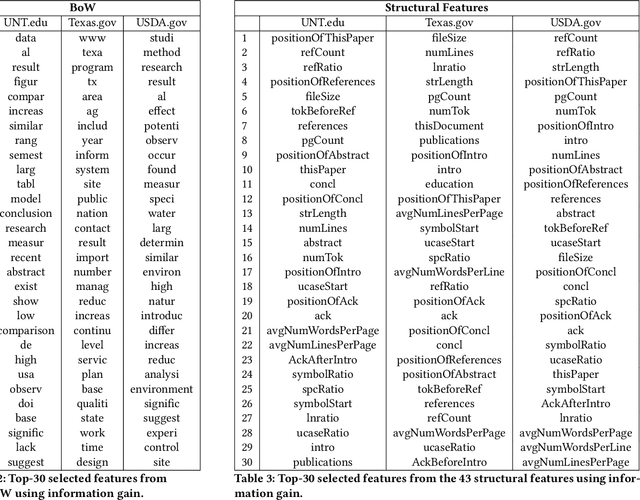

Web archive data usually contains high-quality documents that are very useful for creating specialized collections of documents, e.g., scientific digital libraries and repositories of technical reports. In doing so, there is a substantial need for automatic approaches that can distinguish the documents of interest for a collection out of the huge number of documents collected by web archiving institutions. In this paper, we explore different learning models and feature representations to determine the best performing ones for identifying the documents of interest from the web archived data. Specifically, we study both machine learning and deep learning models and "bag of words" (BoW) features extracted from the entire document or from specific portions of the document, as well as structural features that capture the structure of documents. We focus our evaluation on three datasets that we created from three different Web archives. Our experimental results show that the BoW classifiers that focus only on specific portions of the documents (rather than the full text) outperform all compared methods on all three datasets.
* 10 pages