 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHUGE: Huge Unsupervised Graph Embeddings with TPUs
Jul 26, 2023



Graphs are a representation of structured data that captures the relationships between sets of objects. With the ubiquity of available network data, there is increasing industrial and academic need to quickly analyze graphs with billions of nodes and trillions of edges. A common first step for network understanding is Graph Embedding, the process of creating a continuous representation of nodes in a graph. A continuous representation is often more amenable, especially at scale, for solving downstream machine learning tasks such as classification, link prediction, and clustering. A high-performance graph embedding architecture leveraging Tensor Processing Units (TPUs) with configurable amounts of high-bandwidth memory is presented that simplifies the graph embedding problem and can scale to graphs with billions of nodes and trillions of edges. We verify the embedding space quality on real and synthetic large-scale datasets.
TF-GNN: Graph Neural Networks in TensorFlow
Jul 07, 2022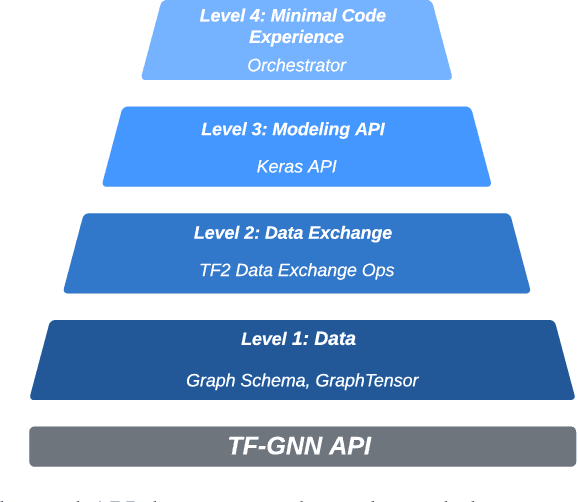
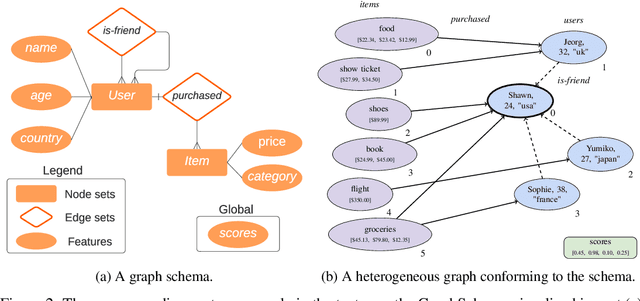
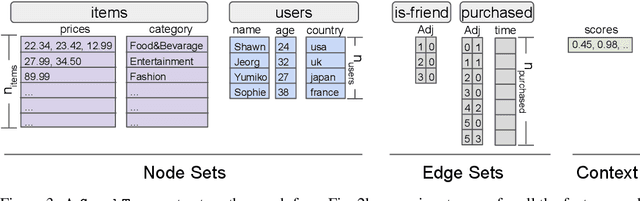
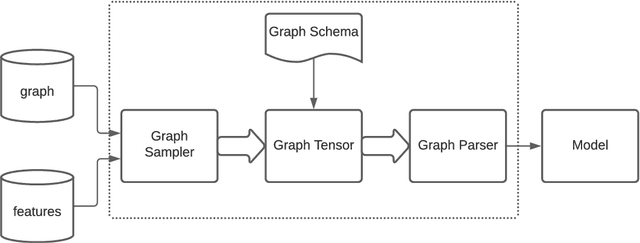
TensorFlow GNN (TF-GNN) is a scalable library for Graph Neural Networks in TensorFlow. It is designed from the bottom up to support the kinds of rich heterogeneous graph data that occurs in today's information ecosystems. Many production models at Google use TF-GNN and it has been recently released as an open source project. In this paper, we describe the TF-GNN data model, its Keras modeling API, and relevant capabilities such as graph sampling, distributed training, and accelerator support.
GraphWorld: Fake Graphs Bring Real Insights for GNNs
Feb 28, 2022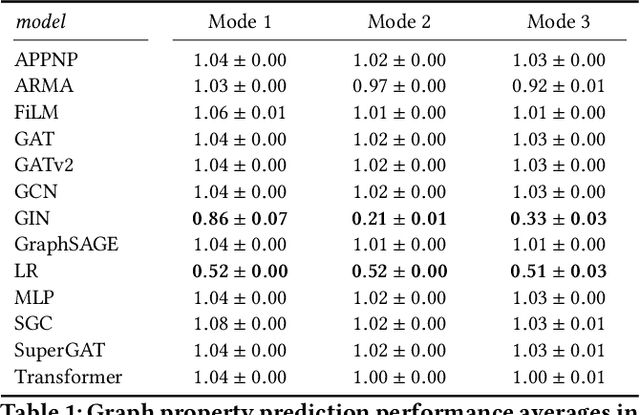


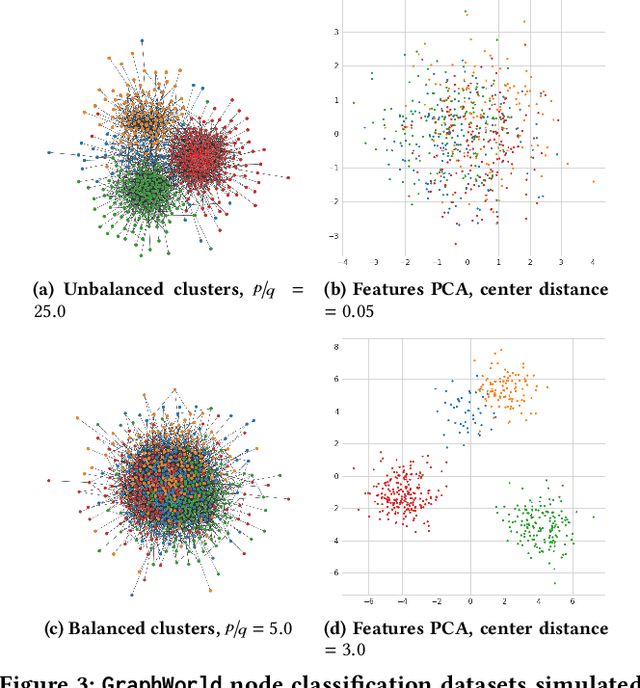
Despite advances in the field of Graph Neural Networks (GNNs), only a small number (~5) of datasets are currently used to evaluate new models. This continued reliance on a handful of datasets provides minimal insight into the performance differences between models, and is especially challenging for industrial practitioners who are likely to have datasets which look very different from those used as academic benchmarks. In the course of our work on GNN infrastructure and open-source software at Google, we have sought to develop improved benchmarks that are robust, tunable, scalable,and generalizable. In this work we introduce GraphWorld, a novel methodology and system for benchmarking GNN models on an arbitrarily-large population of synthetic graphs for any conceivable GNN task. GraphWorld allows a user to efficiently generate a world with millions of statistically diverse datasets. It is accessible, scalable, and easy to use. GraphWorld can be run on a single machine without specialized hardware, or it can be easily scaled up to run on arbitrary clusters or cloud frameworks. Using GraphWorld, a user has fine-grained control over graph generator parameters, and can benchmark arbitrary GNN models with built-in hyperparameter tuning. We present insights from GraphWorld experiments regarding the performance characteristics of tens of thousands of GNN models over millions of benchmark datasets. We further show that GraphWorld efficiently explores regions of benchmark dataset space uncovered by standard benchmarks, revealing comparisons between models that have not been historically obtainable. Using GraphWorld, we also are able to study in-detail the relationship between graph properties and task performance metrics, which is nearly impossible with the classic collection of real-world benchmarks.
Kartta Labs: Collaborative Time Travel
Oct 07, 2020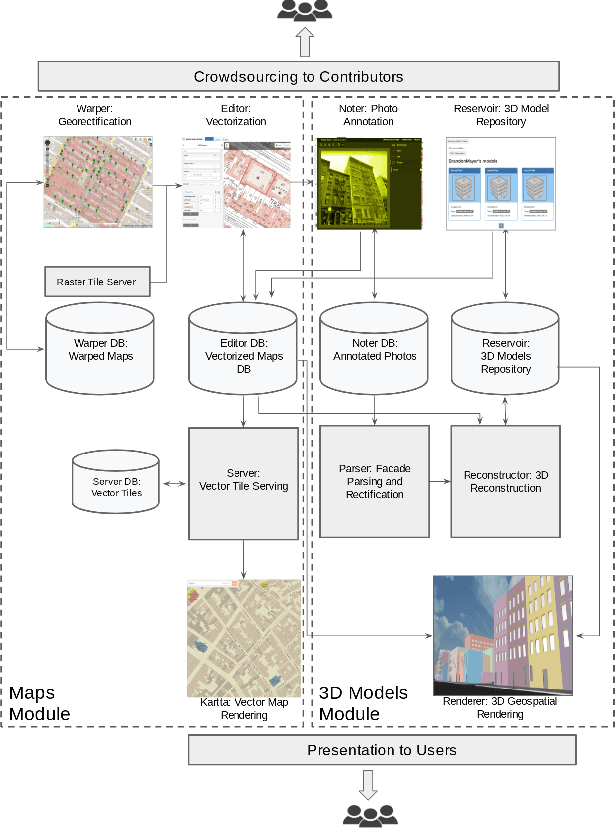
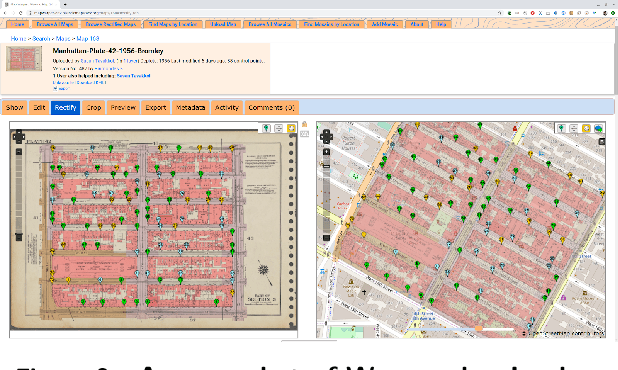
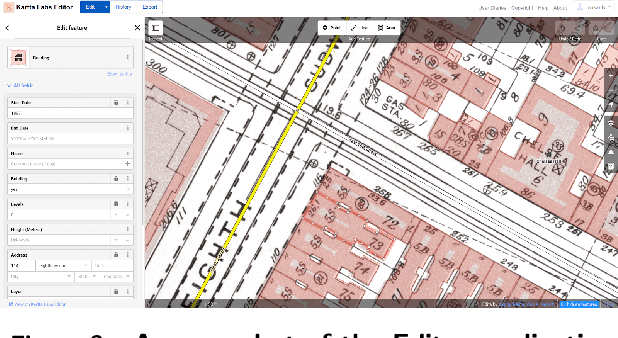
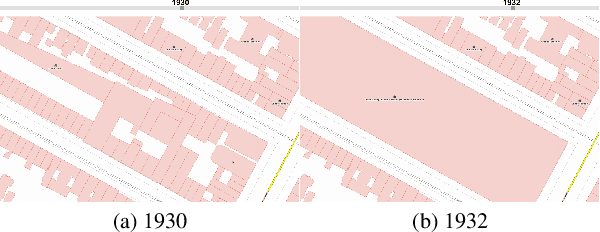
We introduce the modular and scalable design of Kartta Labs, an open source, open data, and scalable system for virtually reconstructing cities from historical maps and photos. Kartta Labs relies on crowdsourcing and artificial intelligence consisting of two major modules: Maps and 3D models. Each module, in turn, consists of sub-modules that enable the system to reconstruct a city from historical maps and photos. The result is a spatiotemporal reference that can be used to integrate various collected data (curated, sensed, or crowdsourced) for research, education, and entertainment purposes. The system empowers the users to experience collaborative time travel such that they work together to reconstruct the past and experience it on an open source and open data platform.