 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobility-Embedded POIs: Learning What A Place Is and How It Is Used from Human Movement
Jan 29, 2026Recent progress in geospatial foundation models highlights the importance of learning general-purpose representations for real-world locations, particularly points-of-interest (POIs) where human activity concentrates. Existing approaches, however, focus primarily on place identity derived from static textual metadata, or learn representations tied to trajectory context, which capture movement regularities rather than how places are actually used (i.e., POI's function). We argue that POI function is a missing but essential signal for general POI representations. We introduce Mobility-Embedded POIs (ME-POIs), a framework that augments POI embeddings derived, from language models with large-scale human mobility data to learn POI-centric, context-independent representations grounded in real-world usage. ME-POIs encodes individual visits as temporally contextualized embeddings and aligns them with learnable POI representations via contrastive learning to capture usage patterns across users and time. To address long-tail sparsity, we propose a novel mechanism that propagates temporal visit patterns from nearby, frequently visited POIs across multiple spatial scales. We evaluate ME-POIs on five newly proposed map enrichment tasks, testing its ability to capture both the identity and function of POIs. Across all tasks, augmenting text-based embeddings with ME-POIs consistently outperforms both text-only and mobility-only baselines. Notably, ME-POIs trained on mobility data alone can surpass text-only models on certain tasks, highlighting that POI function is a critical component of accurate and generalizable POI representations.
Geo2Vec: Shape- and Distance-Aware Neural Representation of Geospatial Entities
Aug 26, 2025Spatial representation learning is essential for GeoAI applications such as urban analytics, enabling the encoding of shapes, locations, and spatial relationships (topological and distance-based) of geo-entities like points, polylines, and polygons. Existing methods either target a single geo-entity type or, like Poly2Vec, decompose entities into simpler components to enable Fourier transformation, introducing high computational cost. Moreover, since the transformed space lacks geometric alignment, these methods rely on uniform, non-adaptive sampling, which blurs fine-grained features like edges and boundaries. To address these limitations, we introduce Geo2Vec, a novel method inspired by signed distance fields (SDF) that operates directly in the original space. Geo2Vec adaptively samples points and encodes their signed distances (positive outside, negative inside), capturing geometry without decomposition. A neural network trained to approximate the SDF produces compact, geometry-aware, and unified representations for all geo-entity types. Additionally, we propose a rotation-invariant positional encoding to model high-frequency spatial variations and construct a structured and robust embedding space for downstream GeoAI models. Empirical results show that Geo2Vec consistently outperforms existing methods in representing shape and location, capturing topological and distance relationships, and achieving greater efficiency in real-world GeoAI applications. Code and Data can be found at: https://github.com/chuchen2017/GeoNeuralRepresentation.
Small Graph Is All You Need: DeepStateGNN for Scalable Traffic Forecasting
Feb 20, 2025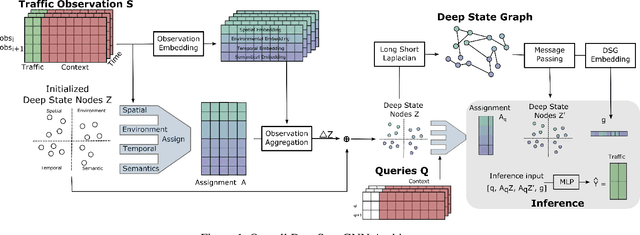

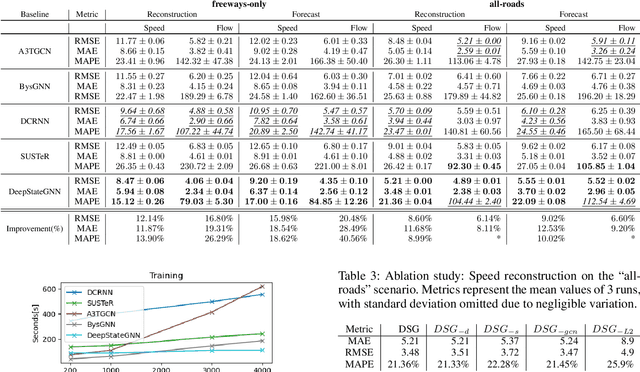
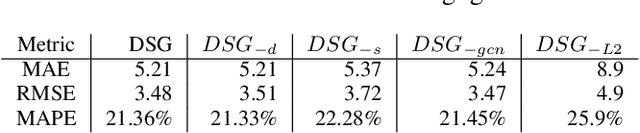
We propose a novel Graph Neural Network (GNN) model, named DeepStateGNN, for analyzing traffic data, demonstrating its efficacy in two critical tasks: forecasting and reconstruction. Unlike typical GNN methods that treat each traffic sensor as an individual graph node, DeepStateGNN clusters sensors into higher-level graph nodes, dubbed Deep State Nodes, based on various similarity criteria, resulting in a fixed number of nodes in a Deep State graph. The term "Deep State" nodes is a play on words, referencing hidden networks of power that, like these nodes, secretly govern traffic independently of visible sensors. These Deep State Nodes are defined by several similarity factors, including spatial proximity (e.g., sensors located nearby in the road network), functional similarity (e.g., sensors on similar types of freeways), and behavioral similarity under specific conditions (e.g., traffic behavior during rain). This clustering approach allows for dynamic and adaptive node grouping, as sensors can belong to multiple clusters and clusters may evolve over time. Our experimental results show that DeepStateGNN offers superior scalability and faster training, while also delivering more accurate results than competitors. It effectively handles large-scale sensor networks, outperforming other methods in both traffic forecasting and reconstruction accuracy.
WaveGNN: Modeling Irregular Multivariate Time Series for Accurate Predictions
Dec 14, 2024



Accurately modeling and analyzing time series data is crucial for downstream applications across various fields, including healthcare, finance, astronomy, and epidemiology. However, real-world time series often exhibit irregularities such as misaligned timestamps, missing entries, and variable sampling rates, complicating their analysis. Existing approaches often rely on imputation, which can introduce biases. A few approaches that directly model irregularity tend to focus exclusively on either capturing intra-series patterns or inter-series relationships, missing the benefits of integrating both. To this end, we present WaveGNN, a novel framework designed to directly (i.e., no imputation) embed irregularly sampled multivariate time series data for accurate predictions. WaveGNN utilizes a Transformer-based encoder to capture intra-series patterns by directly encoding the temporal dynamics of each time series. To capture inter-series relationships, WaveGNN uses a dynamic graph neural network model, where each node represents a sensor, and the edges capture the long- and short-term relationships between them. Our experimental results on real-world healthcare datasets demonstrate that WaveGNN consistently outperforms existing state-of-the-art methods, with an average relative improvement of 14.7% in F1-score when compared to the second-best baseline in cases with extreme sparsity. Our ablation studies reveal that both intra-series and inter-series modeling significantly contribute to this notable improvement.
Forecasting Unseen Points of Interest Visits Using Context and Proximity Priors
Nov 22, 2024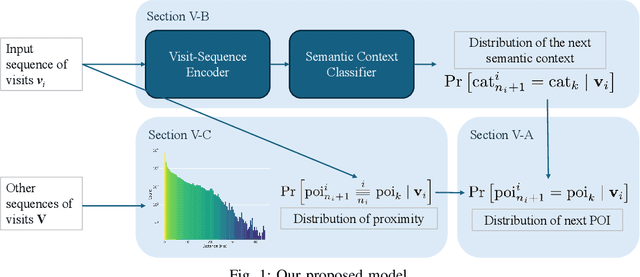
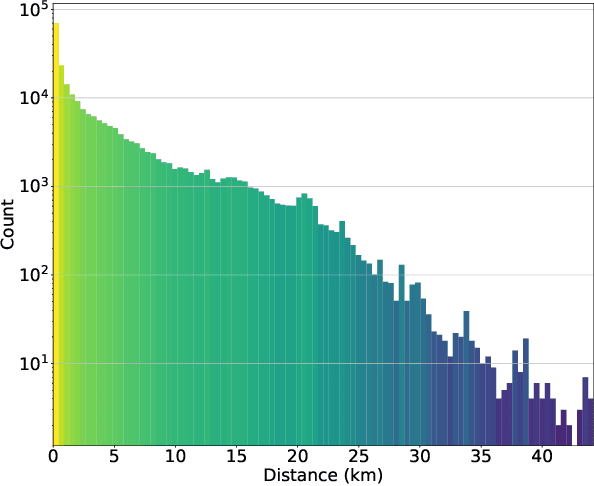
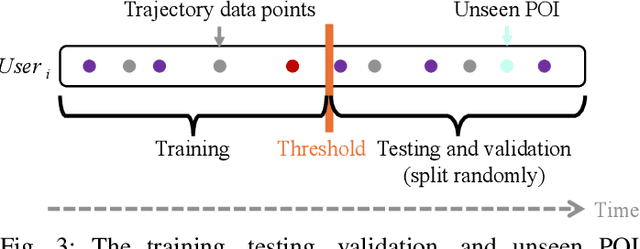
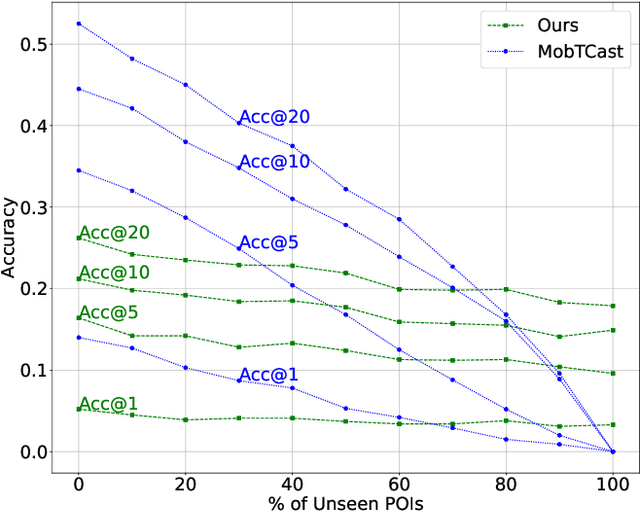
Understanding human mobility behavior is crucial for numerous applications, including crowd management, location-based recommendations, and the estimation of pandemic spread. Machine learning models can predict the Points of Interest (POIs) that individuals are likely to visit in the future by analyzing their historical visit patterns. Previous studies address this problem by learning a POI classifier, where each class corresponds to a POI. However, this limits their applicability to predict a new POI that was not in the training data, such as the opening of new restaurants. To address this challenge, we propose a model designed to predict a new POI outside the training data as long as its context is aligned with the user's interests. Unlike existing approaches that directly predict specific POIs, our model first forecasts the semantic context of potential future POIs, then combines this with a proximity-based prior probability distribution to determine the exact POI. Experimental results on real-world visit data demonstrate that our model outperforms baseline methods that do not account for semantic contexts, achieving a 17% improvement in accuracy. Notably, as new POIs are introduced over time, our model remains robust, exhibiting a lower decline rate in prediction accuracy compared to existing methods.
Towards Establishing Guaranteed Error for Learned Database Operations
Nov 09, 2024
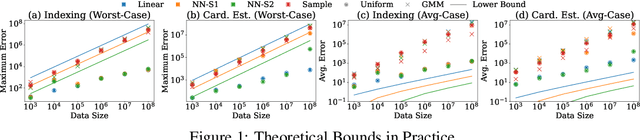
Machine learning models have demonstrated substantial performance enhancements over non-learned alternatives in various fundamental data management operations, including indexing (locating items in an array), cardinality estimation (estimating the number of matching records in a database), and range-sum estimation (estimating aggregate attribute values for query-matched records). However, real-world systems frequently favor less efficient non-learned methods due to their ability to offer (worst-case) error guarantees - an aspect where learned approaches often fall short. The primary objective of these guarantees is to ensure system reliability, ensuring that the chosen approach consistently delivers the desired level of accuracy across all databases. In this paper, we embark on the first theoretical study of such guarantees for learned methods, presenting the necessary conditions for such guarantees to hold when using machine learning to perform indexing, cardinality estimation and range-sum estimation. Specifically, we present the first known lower bounds on the model size required to achieve the desired accuracy for these three key database operations. Our results bound the required model size for given average and worst-case errors in performing database operations, serving as the first theoretical guidelines governing how model size must change based on data size to be able to guarantee an accuracy level. More broadly, our established guarantees pave the way for the broader adoption and integration of learned models into real-world systems.
TrajGPT: Controlled Synthetic Trajectory Generation Using a Multitask Transformer-Based Spatiotemporal Model
Nov 07, 2024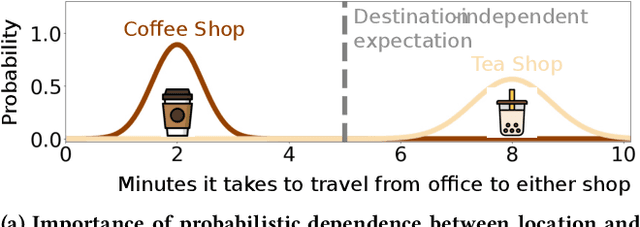

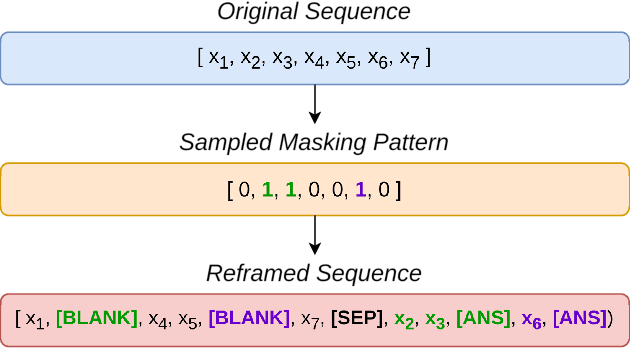

Human mobility modeling from GPS-trajectories and synthetic trajectory generation are crucial for various applications, such as urban planning, disaster management and epidemiology. Both of these tasks often require filling gaps in a partially specified sequence of visits - a new problem that we call "controlled" synthetic trajectory generation. Existing methods for next-location prediction or synthetic trajectory generation cannot solve this problem as they lack the mechanisms needed to constrain the generated sequences of visits. Moreover, existing approaches (1) frequently treat space and time as independent factors, an assumption that fails to hold true in real-world scenarios, and (2) suffer from challenges in accuracy of temporal prediction as they fail to deal with mixed distributions and the inter-relationships of different modes with latent variables (e.g., day-of-the-week). These limitations become even more pronounced when the task involves filling gaps within sequences instead of solely predicting the next visit. We introduce TrajGPT, a transformer-based, multi-task, joint spatiotemporal generative model to address these issues. Taking inspiration from large language models, TrajGPT poses the problem of controlled trajectory generation as that of text infilling in natural language. TrajGPT integrates the spatial and temporal models in a transformer architecture through a Bayesian probability model that ensures that the gaps in a visit sequence are filled in a spatiotemporally consistent manner. Our experiments on public and private datasets demonstrate that TrajGPT not only excels in controlled synthetic visit generation but also outperforms competing models in next-location prediction tasks - Relatively, TrajGPT achieves a 26-fold improvement in temporal accuracy while retaining more than 98% of spatial accuracy on average.
Poly2Vec: Polymorphic Encoding of Geospatial Objects for Spatial Reasoning with Deep Neural Networks
Aug 27, 2024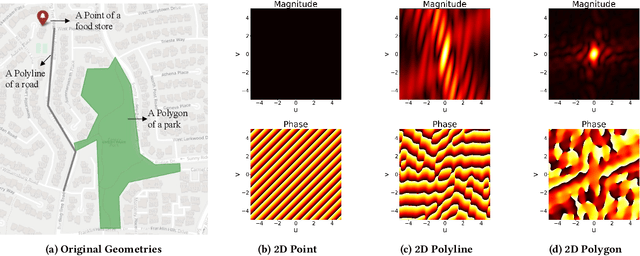
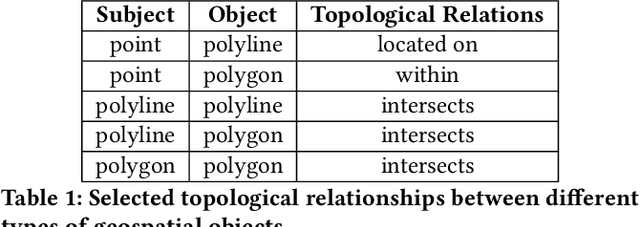
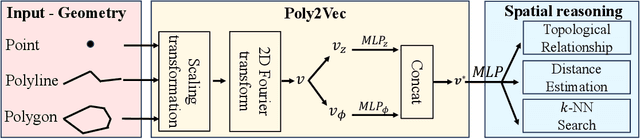
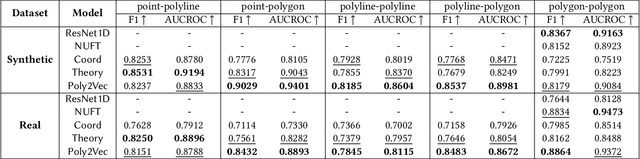
Encoding geospatial data is crucial for enabling machine learning (ML) models to perform tasks that require spatial reasoning, such as identifying the topological relationships between two different geospatial objects. However, existing encoding methods are limited as they are typically customized to handle only specific types of spatial data, which impedes their applicability across different downstream tasks where multiple data types coexist. To address this, we introduce Poly2Vec, an encoding framework that unifies the modeling of different geospatial objects, including 2D points, polylines, and polygons, irrespective of the downstream task. We leverage the power of the 2D Fourier transform to encode useful spatial properties, such as shape and location, from geospatial objects into fixed-length vectors. These vectors are then inputted into neural network models for spatial reasoning tasks.This unified approach eliminates the need to develop and train separate models for each distinct spatial type. We evaluate Poly2Vec on both synthetic and real datasets of mixed geometry types and verify its consistent performance across several downstream spatial reasoning tasks.
Geo-Llama: Leveraging LLMs for Human Mobility Trajectory Generation with Spatiotemporal Constraints
Aug 25, 2024



Simulating human mobility data is essential for various application domains, including transportation, urban planning, and epidemic control, since real data are often inaccessible to researchers due to expensive costs and privacy issues. Several existing deep generative solutions propose learning from real trajectories to generate synthetic ones. Despite the progress, most of them suffer from training stability issues and scale poorly with growing data size. More importantly, they generally lack control mechanisms to steer the generated trajectories based on spatiotemporal constraints such as fixing specific visits. To address such limitations, we formally define the controlled trajectory generation problem with spatiotemporal constraints and propose Geo-Llama. This novel LLM-inspired framework enforces explicit visit constraints in a contextually coherent way. It fine-tunes pre-trained LLMs on trajectories with a visit-wise permutation strategy where each visit corresponds to a time and location. This enables the model to capture the spatiotemporal patterns regardless of visit orders and allows flexible and in-context constraint integration through prompts during generation. Extensive experiments on real-world and synthetic datasets validate the effectiveness of Geo-Llama, demonstrating its versatility and robustness in handling a broad range of constraints to generate more realistic trajectories compared to existing methods.
Dynamic GNNs for Precise Seizure Detection and Classification from EEG Data
May 08, 2024Diagnosing epilepsy requires accurate seizure detection and classification, but traditional manual EEG signal analysis is resource-intensive. Meanwhile, automated algorithms often overlook EEG's geometric and semantic properties critical for interpreting brain activity. This paper introduces NeuroGNN, a dynamic Graph Neural Network (GNN) framework that captures the dynamic interplay between the EEG electrode locations and the semantics of their corresponding brain regions. The specific brain region where an electrode is placed critically shapes the nature of captured EEG signals. Each brain region governs distinct cognitive functions, emotions, and sensory processing, influencing both the semantic and spatial relationships within the EEG data. Understanding and modeling these intricate brain relationships are essential for accurate and meaningful insights into brain activity. This is precisely where the proposed NeuroGNN framework excels by dynamically constructing a graph that encapsulates these evolving spatial, temporal, semantic, and taxonomic correlations to improve precision in seizure detection and classification. Our extensive experiments with real-world data demonstrate that NeuroGNN significantly outperforms existing state-of-the-art models.
* This preprint has not undergone any post-submission improvements or corrections. The Version of Record of this contribution is published in the proceedings of the 28th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2024), Taipei, Taiwan, May 7-10, 2024, and is available online at https://doi.org/10.1007/978-981-97-2238-9_16