 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Survey of Privacy and Fairness in Machine Learning
Jul 28, 2023Privacy and fairness are two crucial pillars of responsible Artificial Intelligence (AI) and trustworthy Machine Learning (ML). Each objective has been independently studied in the literature with the aim of reducing utility loss in achieving them. Despite the significant interest attracted from both academia and industry, there remains an immediate demand for more in-depth research to unravel how these two objectives can be simultaneously integrated into ML models. As opposed to well-accepted trade-offs, i.e., privacy-utility and fairness-utility, the interrelation between privacy and fairness is not well-understood. While some works suggest a trade-off between the two objective functions, there are others that demonstrate the alignment of these functions in certain scenarios. To fill this research gap, we provide a thorough review of privacy and fairness in ML, including supervised, unsupervised, semi-supervised, and reinforcement learning. After examining and consolidating the literature on both objectives, we present a holistic survey on the impact of privacy on fairness, the impact of fairness on privacy, existing architectures, their interaction in application domains, and algorithms that aim to achieve both objectives while minimizing the utility sacrificed. Finally, we identify research challenges in achieving privacy and fairness concurrently in ML, particularly focusing on large language models.
Fair Spatial Indexing: A paradigm for Group Spatial Fairness
Feb 05, 2023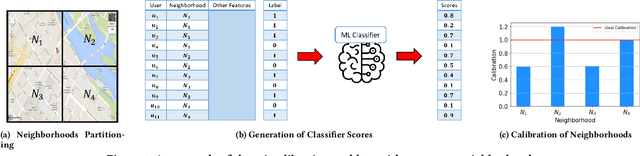

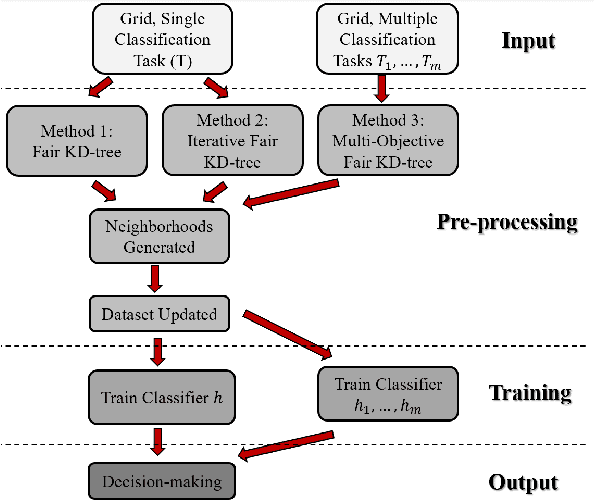
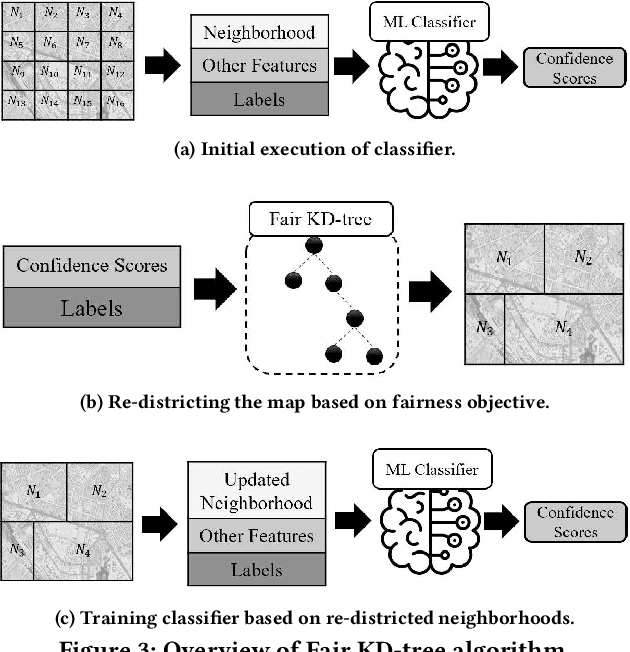
Machine learning (ML) is playing an increasing role in decision-making tasks that directly affect individuals, e.g., loan approvals, or job applicant screening. Significant concerns arise that, without special provisions, individuals from under-privileged backgrounds may not get equitable access to services and opportunities. Existing research studies fairness with respect to protected attributes such as gender, race or income, but the impact of location data on fairness has been largely overlooked. With the widespread adoption of mobile apps, geospatial attributes are increasingly used in ML, and their potential to introduce unfair bias is significant, given their high correlation with protected attributes. We propose techniques to mitigate location bias in machine learning. Specifically, we consider the issue of miscalibration when dealing with geospatial attributes. We focus on spatial group fairness and we propose a spatial indexing algorithm that accounts for fairness. Our KD-tree inspired approach significantly improves fairness while maintaining high learning accuracy, as shown by extensive experimental results on real data.
Models and Mechanisms for Fairness in Location Data Processing
Apr 04, 2022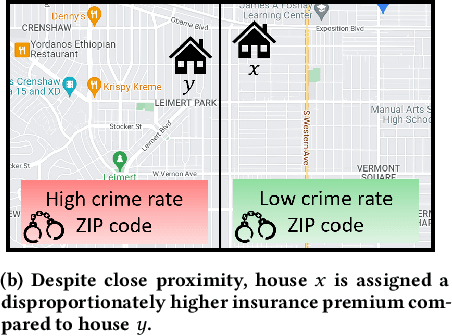

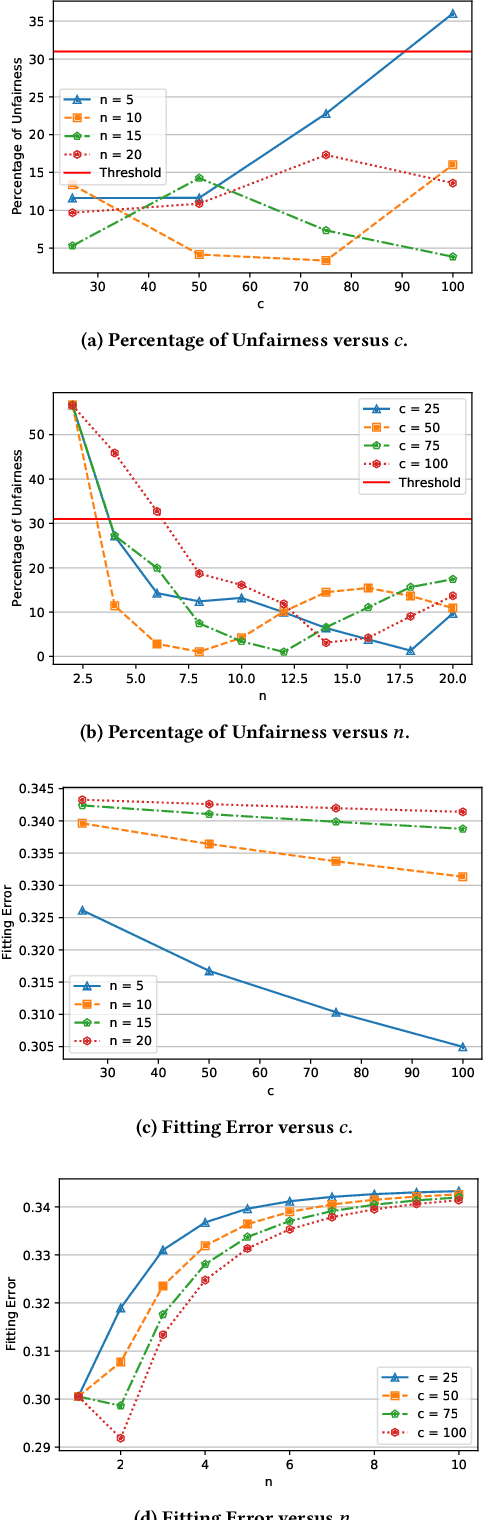
Location data use has become pervasive in the last decade due to the advent of mobile apps, as well as novel areas such as smart health, smart cities, etc. At the same time, significant concerns have surfaced with respect to fairness in data processing. Individuals from certain population segments may be unfairly treated when being considered for loan or job applications, access to public resources, or other types of services. In the case of location data, fairness is an important concern, given that an individual's whereabouts are often correlated with sensitive attributes, e.g., race, income, education. While fairness has received significant attention recently, e.g., in the case of machine learning, there is little focus on the challenges of achieving fairness when dealing with location data. Due to their characteristics and specific type of processing algorithms, location data pose important fairness challenges that must be addressed in a comprehensive and effective manner. In this paper, we adapt existing fairness models to suit the specific properties of location data and spatial processing. We focus on individual fairness, which is more difficult to achieve, and more relevant for most location data processing scenarios. First, we devise a novel building block to achieve fairness in the form of fair polynomials. Then, we propose two mechanisms based on fair polynomials that achieve individual fairness, corresponding to two common interaction types based on location data. Extensive experimental results on real data show that the proposed mechanisms achieve individual location fairness without sacrificing utility.