 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWireless Communication Enhanced Value Decomposition for Multi-Agent Reinforcement Learning
Apr 09, 2026Cooperation in multi-agent reinforcement learning (MARL) benefits from inter-agent communication, yet most approaches assume idealized channels and existing value decomposition methods ignore who successfully shared information with whom. We propose CLOVER, a cooperative MARL framework whose centralized value mixer is conditioned on the communication graph realized under a realistic wireless channel. This graph introduces a relational inductive bias into value decomposition, constraining how individual utilities are mixed based on the realized communication structure. The mixer is a GNN with node-specific weights generated by a Permutation-Equivariant Hypernetwork: multi-hop propagation along communication edges reshapes credit assignment so that different topologies induce different mixing. We prove this mixer is permutation invariant, monotonic (preserving the IGM condition), and strictly more expressive than QMIX-style mixers. To handle realistic channels, we formulate an augmented MDP isolating stochastic channel effects from the agent computation graph, and employ a stochastic receptive field encoder for variable-size message sets, enabling end-to-end differentiable training. On Predator-Prey and Lumberjacks benchmarks under p-CSMA wireless channels, CLOVER consistently improves convergence speed and final performance over VDN, QMIX, TarMAC+VDN, and TarMAC+QMIX. Behavioral analysis confirms agents learn adaptive signaling and listening strategies, and ablations isolate the communication-graph inductive bias as the key source of improvement.
From Gaussian Fading to Gilbert-Elliott: Bridging Physical and Link-Layer Channel Models in Closed Form
Apr 03, 2026Dynamic fading channels are modeled at two fundamentally different levels of abstraction. At the physical layer, the standard representation is a correlated Gaussian process, such as the dB-domain signal power in log-normal shadow fading. At the link layer, the dominant abstraction is the Gilbert-Elliott (GE) two-state Markov chain, which compresses the channel into a binary ``decodable or not'' sequence with temporal memory. Both models are ubiquitous, yet practitioners who need GE parameters from an underlying Gaussian fading model must typically simulate the mapping or invoke continuous-time level-crossing approximations that do not yield discrete-slot transition probabilities in closed form. This paper provides an exact, closed-form bridge. By thresholding the Gaussian process at discrete slot boundaries, we derive the GE transition probabilities via Owen's $T$-function for any threshold, reducing to an elementary arcsine identity when the threshold equals the mean. The formulas depend on the covariance kernel only through the one-step correlation coefficient $ρ= K(D)/K(0)$, making them applicable to any stationary Gaussian fading model. The bridge reveals how kernel smoothness governs the resulting link-layer dynamics: the GE persistence time grows linearly in the correlation length $T_c$ for a smooth (squared-exponential) kernel but only as $\sqrt{T_c}$ for a rough (exponential/Ornstein--Uhlenbeck) kernel. We further quantify when the first-order GE chain is a faithful approximation of the full binary process and when it is not, reconciling two diagnostics, the one-step Markov gap and the run-length total-variation distance, that can trend in opposite directions. Monte Carlo simulations validate all theoretical predictions.
Compiler-Guided Inference-Time Adaptation: Improving GPT-5 Programming Performance in Idris
Feb 12, 2026GPT-5, a state of the art large language model from OpenAI, demonstrates strong performance in widely used programming languages such as Python, C++, and Java; however, its ability to operate in low resource or less commonly used languages remains underexplored. This work investigates whether GPT-5 can effectively acquire proficiency in an unfamiliar functional programming language, Idris, through iterative, feedback driven prompting. We first establish a baseline showing that with zero shot prompting the model solves only 22 out of 56 Idris exercises using the platform Exercism, substantially underperforming relative to higher resource languages (45 out of 50 in Python and 35 out of 47 in Erlang). We then evaluate several refinement strategies, including iterative prompting based on platform feedback, augmenting prompts with documentation and error classification guides, and iterative prompting using local compilation errors and failed test cases. Among these approaches, incorporating local compilation errors yields the most substantial improvements. Using this structured, error guided refinement loop, GPT-5 performance increased to an impressive 54 solved problems out of 56. These results suggest that while large language models may initially struggle in low resource settings, structured compiler level feedback can play a critical role in unlocking their capabilities.
SATORIS-N: Spectral Analysis based Traffic Observation Recovery via Informed Subspaces and Nuclear-norm minimization
Feb 03, 2026Traffic-density matrices from different days exhibit both low rank and stable correlations in their singular-vector subspaces. Leveraging this, we introduce SATORIS-N, a framework for imputing partially observed traffic-density by informed subspace priors from neighboring days. Our contribution is a subspace-aware semidefinite programming (SDP)} formulation of nuclear norm that explicitly informs the reconstruction with prior singular-subspace information. This convex formulation jointly enforces low rank and subspace alignment, providing a single global optimum and substantially improving accuracy under medium and high occlusion. We also study a lightweight implicit subspace-alignment} strategy in which matrices from consecutive days are concatenated to encourage alignment of spatial or temporal singular directions. Although this heuristic offers modest gains when missing rates are low, the explicit SDP approach is markedly more robust when large fractions of entries are missing. Across two real-world datasets (Beijing and Shanghai), SATORIS-N consistently outperforms standard matrix-completion methods such as SoftImpute, IterativeSVD, statistical, and even deep learning baselines at high occlusion levels. The framework generalizes to other spatiotemporal settings in which singular subspaces evolve slowly over time. In the context of intelligent vehicles and vehicle-to-everything (V2X) systems, accurate traffic-density reconstruction enables critical applications including cooperative perception, predictive routing, and vehicle-to-infrastructure (V2I) communication optimization. When infrastructure sensors or vehicle-reported observations are incomplete - due to communication dropouts, sensor occlusions, or sparse connected vehicle penetration-reliable imputation becomes essential for safe and efficient autonomous navigation.
Learning Wireless Interference Patterns: Decoupled GNN for Throughput Prediction in Heterogeneous Multi-Hop p-CSMA Networks
Oct 15, 2025The p-persistent CSMA protocol is central to random-access MAC analysis, but predicting saturation throughput in heterogeneous multi-hop wireless networks remains a hard problem. Simplified models that assume a single, shared interference domain can underestimate throughput by 48--62\% in sparse topologies. Exact Markov-chain analyses are accurate but scale exponentially in computation time, making them impractical for large networks. These computational barriers motivate structural machine learning approaches like GNNs for scalable throughput prediction in general network topologies. Yet off-the-shelf GNNs struggle here: a standard GCN yields 63.94\% normalized mean absolute error (NMAE) on heterogeneous networks because symmetric normalization conflates a node's direct interference with higher-order, cascading effects that pertain to how interference propagates over the network graph. Building on these insights, we propose the Decoupled Graph Convolutional Network (D-GCN), a novel architecture that explicitly separates processing of a node's own transmission probability from neighbor interference effects. D-GCN replaces mean aggregation with learnable attention, yielding interpretable, per-neighbor contribution weights while capturing complex multihop interference patterns. D-GCN attains 3.3\% NMAE, outperforms strong baselines, remains tractable even when exact analytical methods become computationally infeasible, and enables gradient-based network optimization that achieves within 1\% of theoretical optima.
Crowd-SFT: Crowdsourcing for LLM Alignment
Jun 04, 2025Large Language Models (LLMs) increasingly rely on Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) to align model responses with human preferences. While RLHF employs a reinforcement learning approach with a separate reward model, SFT uses human-curated datasets for supervised learning. Both approaches traditionally depend on small, vetted groups of annotators, making them costly, prone to bias, and limited in scalability. We propose an open, crowd-sourced fine-tuning framework that addresses these limitations by enabling broader feedback collection for SFT without extensive annotator training. Our framework promotes incentive fairness via a point-based reward system correlated with Shapley values and guides model convergence through iterative model updates. Our multi-model selection framework demonstrates up to a 55% reduction in target distance over single-model selection, enabling subsequent experiments that validate our point-based reward mechanism's close alignment with Shapley values (a well-established method for attributing individual contributions) thereby supporting fair and scalable participation.
AffectEval: A Modular and Customizable Framework for Affective Computing
Apr 29, 2025The field of affective computing focuses on recognizing, interpreting, and responding to human emotions, and has broad applications across education, child development, and human health and wellness. However, developing affective computing pipelines remains labor-intensive due to the lack of software frameworks that support multimodal, multi-domain emotion recognition applications. This often results in redundant effort when building pipelines for different applications. While recent frameworks attempt to address these challenges, they remain limited in reducing manual effort and ensuring cross-domain generalizability. We introduce AffectEval, a modular and customizable framework to facilitate the development of affective computing pipelines while reducing the manual effort and duplicate work involved in developing such pipelines. We validate AffectEval by replicating prior affective computing experiments, and we demonstrate that our framework reduces programming effort by up to 90%, as measured by the reduction in raw lines of code.
Evaluating ChatGPT-3.5 Efficiency in Solving Coding Problems of Different Complexity Levels: An Empirical Analysis
Nov 12, 2024

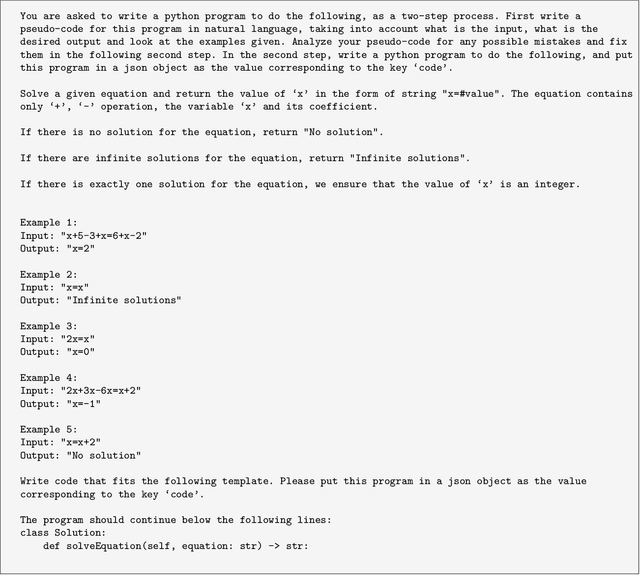
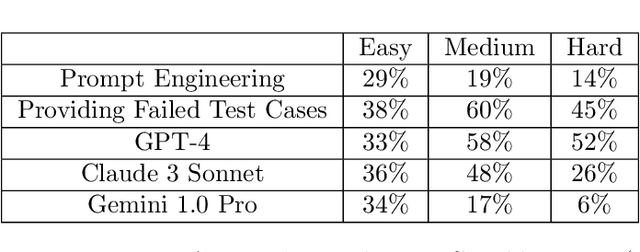
ChatGPT and other large language models (LLMs) promise to revolutionize software development by automatically generating code from program specifications. We assess the performance of ChatGPT's GPT-3.5-turbo model on LeetCode, a popular platform with algorithmic coding challenges for technical interview practice, across three difficulty levels: easy, medium, and hard. We test three main hypotheses. First, ChatGPT solves fewer problems as difficulty rises (Hypothesis 1). Second, prompt engineering improves ChatGPT's performance, with greater gains on easier problems and diminishing returns on harder ones (Hypothesis 2). Third, ChatGPT performs better in popular languages like Python, Java, and C++ than in less common ones like Elixir, Erlang, and Racket (Hypothesis 3). To investigate these hypotheses, we conduct automated experiments using Python scripts to generate prompts that instruct ChatGPT to create Python solutions. These solutions are stored and manually submitted on LeetCode to check their correctness. For Hypothesis 1, results show the GPT-3.5-turbo model successfully solves 92% of easy, 79% of medium, and 51% of hard problems. For Hypothesis 2, prompt engineering yields improvements: 14-29% for Chain of Thought Prompting, 38-60% by providing failed test cases in a second feedback prompt, and 33-58% by switching to GPT-4. From a random subset of problems ChatGPT solved in Python, it also solved 78% in Java, 50% in C++, and none in Elixir, Erlang, or Racket. These findings generally validate all three hypotheses.
Artificial Intelligence of Things: A Survey
Oct 25, 2024



The integration of the Internet of Things (IoT) and modern Artificial Intelligence (AI) has given rise to a new paradigm known as the Artificial Intelligence of Things (AIoT). In this survey, we provide a systematic and comprehensive review of AIoT research. We examine AIoT literature related to sensing, computing, and networking & communication, which form the three key components of AIoT. In addition to advancements in these areas, we review domain-specific AIoT systems that are designed for various important application domains. We have also created an accompanying GitHub repository, where we compile the papers included in this survey: https://github.com/AIoT-MLSys-Lab/AIoT-Survey. This repository will be actively maintained and updated with new research as it becomes available. As both IoT and AI become increasingly critical to our society, we believe AIoT is emerging as an essential research field at the intersection of IoT and modern AI. We hope this survey will serve as a valuable resource for those engaged in AIoT research and act as a catalyst for future explorations to bridge gaps and drive advancements in this exciting field.
* Accepted in ACM Transactions on Sensor Networks (TOSN)
RiskSEA : A Scalable Graph Embedding for Detecting On-chain Fraudulent Activities on the Ethereum Blockchain
Oct 03, 2024



Like any other useful technology, cryptocurrencies are sometimes used for criminal activities. While transactions are recorded on the blockchain, there exists a need for a more rapid and scalable method to detect addresses associated with fraudulent activities. We present RiskSEA, a scalable risk scoring system capable of effectively handling the dynamic nature of large-scale blockchain transaction graphs. The risk scoring system, which we implement for Ethereum, consists of 1. a scalable approach to generating node2vec embedding for entire set of addresses to capture the graph topology 2. transaction-based features to capture the transactional behavioral pattern of an address 3. a classifier model to generate risk score for addresses that combines the node2vec embedding and behavioral features. Efficiently generating node2vec embedding for large scale and dynamically evolving blockchain transaction graphs is challenging, we present two novel approaches for generating node2vec embeddings and effectively scaling it to the entire set of blockchain addresses: 1. node2vec embedding propagation and 2. dynamic node2vec embedding. We present a comprehensive analysis of the proposed approaches. Our experiments show that combining both behavioral and node2vec features boosts the classification performance significantly, and that the dynamic node2vec embeddings perform better than the node2vec propagated embeddings.