 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiler-Guided Inference-Time Adaptation: Improving GPT-5 Programming Performance in Idris
Feb 12, 2026GPT-5, a state of the art large language model from OpenAI, demonstrates strong performance in widely used programming languages such as Python, C++, and Java; however, its ability to operate in low resource or less commonly used languages remains underexplored. This work investigates whether GPT-5 can effectively acquire proficiency in an unfamiliar functional programming language, Idris, through iterative, feedback driven prompting. We first establish a baseline showing that with zero shot prompting the model solves only 22 out of 56 Idris exercises using the platform Exercism, substantially underperforming relative to higher resource languages (45 out of 50 in Python and 35 out of 47 in Erlang). We then evaluate several refinement strategies, including iterative prompting based on platform feedback, augmenting prompts with documentation and error classification guides, and iterative prompting using local compilation errors and failed test cases. Among these approaches, incorporating local compilation errors yields the most substantial improvements. Using this structured, error guided refinement loop, GPT-5 performance increased to an impressive 54 solved problems out of 56. These results suggest that while large language models may initially struggle in low resource settings, structured compiler level feedback can play a critical role in unlocking their capabilities.
Evaluating ChatGPT-3.5 Efficiency in Solving Coding Problems of Different Complexity Levels: An Empirical Analysis
Nov 12, 2024

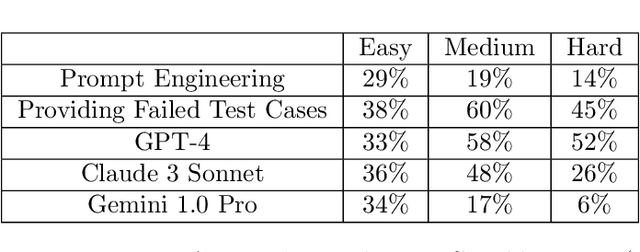
ChatGPT and other large language models (LLMs) promise to revolutionize software development by automatically generating code from program specifications. We assess the performance of ChatGPT's GPT-3.5-turbo model on LeetCode, a popular platform with algorithmic coding challenges for technical interview practice, across three difficulty levels: easy, medium, and hard. We test three main hypotheses. First, ChatGPT solves fewer problems as difficulty rises (Hypothesis 1). Second, prompt engineering improves ChatGPT's performance, with greater gains on easier problems and diminishing returns on harder ones (Hypothesis 2). Third, ChatGPT performs better in popular languages like Python, Java, and C++ than in less common ones like Elixir, Erlang, and Racket (Hypothesis 3). To investigate these hypotheses, we conduct automated experiments using Python scripts to generate prompts that instruct ChatGPT to create Python solutions. These solutions are stored and manually submitted on LeetCode to check their correctness. For Hypothesis 1, results show the GPT-3.5-turbo model successfully solves 92% of easy, 79% of medium, and 51% of hard problems. For Hypothesis 2, prompt engineering yields improvements: 14-29% for Chain of Thought Prompting, 38-60% by providing failed test cases in a second feedback prompt, and 33-58% by switching to GPT-4. From a random subset of problems ChatGPT solved in Python, it also solved 78% in Java, 50% in C++, and none in Elixir, Erlang, or Racket. These findings generally validate all three hypotheses.