 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
Jan 18, 2026Deep Research Agents (DRAs) generate citation-rich reports via multi-step search and synthesis, yet existing benchmarks mainly target text-only settings or short-form multimodal QA, missing end-to-end multimodal evidence use. We introduce MMDeepResearch-Bench (MMDR-Bench), a benchmark of 140 expert-crafted tasks across 21 domains, where each task provides an image-text bundle to evaluate multimodal understanding and citation-grounded report generation. Compared to prior setups, MMDR-Bench emphasizes report-style synthesis with explicit evidence use, where models must connect visual artifacts to sourced claims and maintain consistency across narrative, citations, and visual references. We further propose a unified, interpretable evaluation pipeline: Formula-LLM Adaptive Evaluation (FLAE) for report quality, Trustworthy Retrieval-Aligned Citation Evaluation (TRACE) for citation-grounded evidence alignment, and Multimodal Support-Aligned Integrity Check (MOSAIC) for text-visual integrity, each producing fine-grained signals that support error diagnosis beyond a single overall score. Experiments across 25 state-of-the-art models reveal systematic trade-offs between generation quality, citation discipline, and multimodal grounding, highlighting that strong prose alone does not guarantee faithful evidence use and that multimodal integrity remains a key bottleneck for deep research agents.
Reading Recognition in the Wild
May 30, 2025To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism. Code, model, and data will be public.
SVD-LLM V2: Optimizing Singular Value Truncation for Large Language Model Compression
Mar 16, 2025



Despite significant advancements, the practical deployment of Large Language Models (LLMs) is often hampered by their immense sizes, highlighting the need for effective compression techniques. Singular Value Decomposition (SVD) is a promising LLM compression technique. However, existing SVD-based compression methods fall short in reducing truncation losses, leading to less competitive performance in compressed models. In this work, we introduce SVD-LLM V2, a SVD-based LLM compression method that optimizes singular value truncation in SVD compression with two techniques. First, SVD-LLM V2 proposes to use theoretical truncation loss of weight matrices to assign a unique compression ratio to each weight matrix at different layers to accommodate weight redundancy heterogeneity. Second, SVD-LLM V2 proposes loss-optimized weight truncation to ensure that the truncated singular values result in a lower and more stable truncation loss in practice. We evaluate SVD-LLM V2 on ten datasets and five LLMs at various scales. Our results show SVD-LLM V2 outperforms state-of-the-art SVD-based LLM compression methods. Our code is available at https://github.com/AIoT-MLSys-Lab/SVD-LLM
Artificial Intelligence of Things: A Survey
Oct 25, 2024



The integration of the Internet of Things (IoT) and modern Artificial Intelligence (AI) has given rise to a new paradigm known as the Artificial Intelligence of Things (AIoT). In this survey, we provide a systematic and comprehensive review of AIoT research. We examine AIoT literature related to sensing, computing, and networking & communication, which form the three key components of AIoT. In addition to advancements in these areas, we review domain-specific AIoT systems that are designed for various important application domains. We have also created an accompanying GitHub repository, where we compile the papers included in this survey: https://github.com/AIoT-MLSys-Lab/AIoT-Survey. This repository will be actively maintained and updated with new research as it becomes available. As both IoT and AI become increasingly critical to our society, we believe AIoT is emerging as an essential research field at the intersection of IoT and modern AI. We hope this survey will serve as a valuable resource for those engaged in AIoT research and act as a catalyst for future explorations to bridge gaps and drive advancements in this exciting field.
* Accepted in ACM Transactions on Sensor Networks (TOSN)
IoT in the Era of Generative AI: Vision and Challenges
Jan 06, 2024


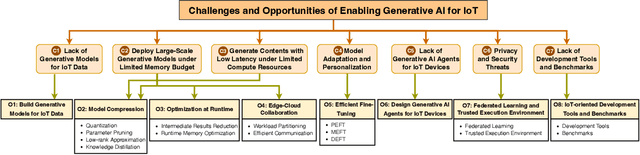
Equipped with sensing, networking, and computing capabilities, Internet of Things (IoT) such as smartphones, wearables, smart speakers, and household robots have been seamlessly weaved into our daily lives. Recent advancements in Generative AI exemplified by GPT, LLaMA, DALL-E, and Stable Difussion hold immense promise to push IoT to the next level. In this article, we share our vision and views on the benefits that Generative AI brings to IoT, and discuss some of the most important applications of Generative AI in IoT-related domains. Fully harnessing Generative AI in IoT is a complex challenge. We identify some of the most critical challenges including high resource demands of the Generative AI models, prompt engineering, on-device inference, offloading, on-device fine-tuning, federated learning, security, as well as development tools and benchmarks, and discuss current gaps as well as promising opportunities on enabling Generative AI for IoT. We hope this article can inspire new research on IoT in the era of Generative AI.
Efficient Large Language Models: A Survey
Dec 23, 2023



Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding, language generation, and complex reasoning and have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we compile the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/EfficientLLMs, and will actively maintain this repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of Things
Sep 29, 2023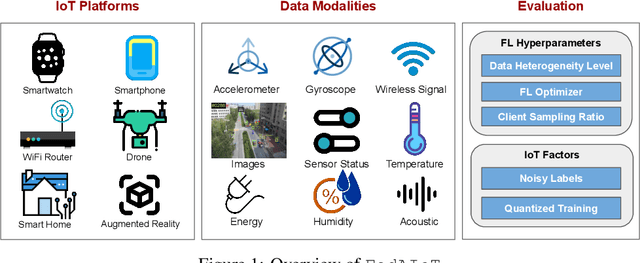

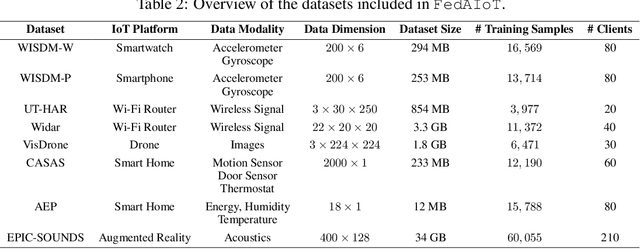
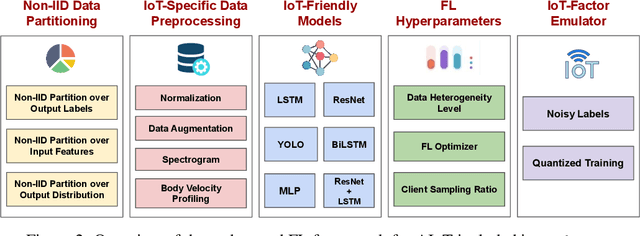
There is a significant relevance of federated learning (FL) in the realm of Artificial Intelligence of Things (AIoT). However, most existing FL works are not conducted on datasets collected from authentic IoT devices that capture unique modalities and inherent challenges of IoT data. In this work, we introduce FedAIoT, an FL benchmark for AIoT to fill this critical gap. FedAIoT includes eight datatsets collected from a wide range of IoT devices. These datasets cover unique IoT modalities and target representative applications of AIoT. FedAIoT also includes a unified end-to-end FL framework for AIoT that simplifies benchmarking the performance of the datasets. Our benchmark results shed light on the opportunities and challenges of FL for AIoT. We hope FedAIoT could serve as an invaluable resource to foster advancements in the important field of FL for AIoT. The repository of FedAIoT is maintained at https://github.com/AIoT-MLSys-Lab/FedAIoT.
GPT-FL: Generative Pre-trained Model-Assisted Federated Learning
Jun 03, 2023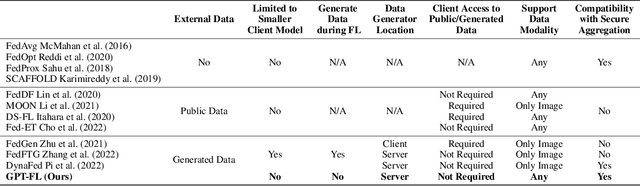
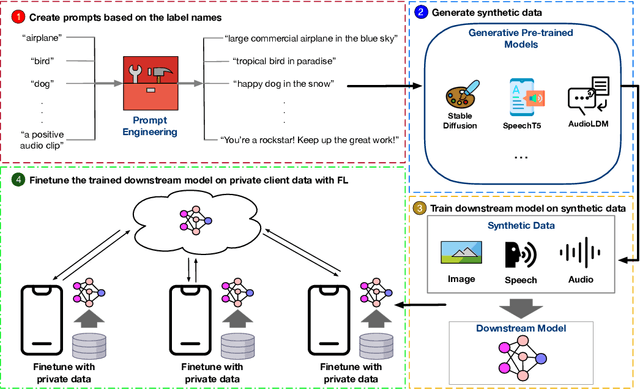
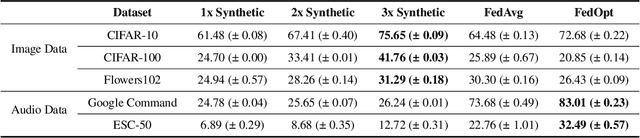
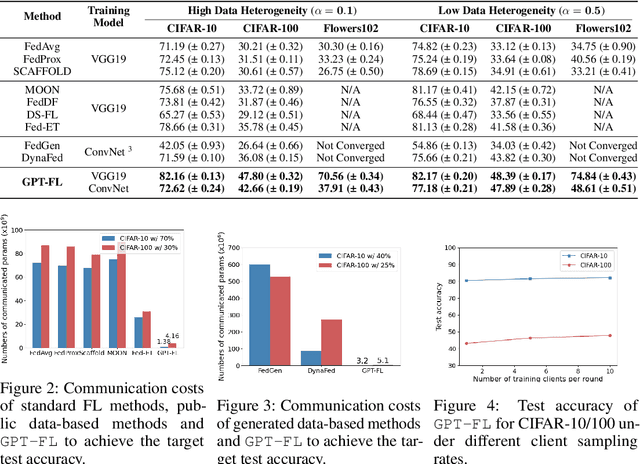
In this work, we propose GPT-FL, a generative pre-trained model-assisted federated learning (FL) framework. At its core, GPT-FL leverages generative pre-trained models to generate diversified synthetic data. These generated data are used to train a downstream model on the server, which is then fine-tuned with private client data under the standard FL framework. We show that GPT-FL consistently outperforms state-of-the-art FL methods in terms of model test accuracy, communication efficiency, and client sampling efficiency. Through comprehensive ablation analysis, we discover that the downstream model generated by synthetic data plays a crucial role in controlling the direction of gradient diversity during FL training, which enhances convergence speed and contributes to the notable accuracy boost observed with GPT-FL. Also, regardless of whether the target data falls within or outside the domain of the pre-trained generative model, GPT-FL consistently achieves significant performance gains, surpassing the results obtained by models trained solely with FL or synthetic data.
OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking
May 15, 2023We present OOD-Speech, the first out-of-distribution (OOD) benchmarking dataset for Bengali automatic speech recognition (ASR). Being one of the most spoken languages globally, Bengali portrays large diversity in dialects and prosodic features, which demands ASR frameworks to be robust towards distribution shifts. For example, islamic religious sermons in Bengali are delivered with a tonality that is significantly different from regular speech. Our training dataset is collected via massively online crowdsourcing campaigns which resulted in 1177.94 hours collected and curated from $22,645$ native Bengali speakers from South Asia. Our test dataset comprises 23.03 hours of speech collected and manually annotated from 17 different sources, e.g., Bengali TV drama, Audiobook, Talk show, Online class, and Islamic sermons to name a few. OOD-Speech is jointly the largest publicly available speech dataset, as well as the first out-of-distribution ASR benchmarking dataset for Bengali.
FedRolex: Model-Heterogeneous Federated Learning with Rolling Sub-Model Extraction
Dec 03, 2022
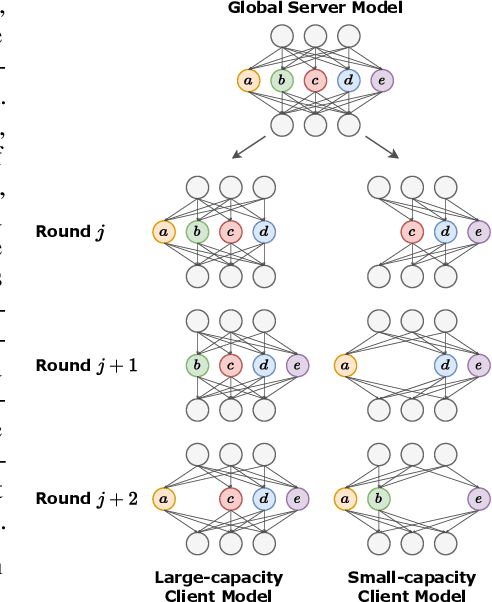


Most cross-device federated learning (FL) studies focus on the model-homogeneous setting where the global server model and local client models are identical. However, such constraint not only excludes low-end clients who would otherwise make unique contributions to model training but also restrains clients from training large models due to on-device resource bottlenecks. In this work, we propose FedRolex, a partial training (PT)-based approach that enables model-heterogeneous FL and can train a global server model larger than the largest client model. At its core, FedRolex employs a rolling sub-model extraction scheme that allows different parts of the global server model to be evenly trained, which mitigates the client drift induced by the inconsistency between individual client models and server model architectures. We show that FedRolex outperforms state-of-the-art PT-based model-heterogeneous FL methods (e.g. Federated Dropout) and reduces the gap between model-heterogeneous and model-homogeneous FL, especially under the large-model large-dataset regime. In addition, we provide theoretical statistical analysis on its advantage over Federated Dropout and evaluate FedRolex on an emulated real-world device distribution to show that FedRolex can enhance the inclusiveness of FL and boost the performance of low-end devices that would otherwise not benefit from FL. Our code is available at https://github.com/MSU-MLSys-Lab/FedRolex.