 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Santali Linguistic Inclusion: Building the First Santali-to-English Translation Model using mT5 Transformer and Data Augmentation
Nov 29, 2024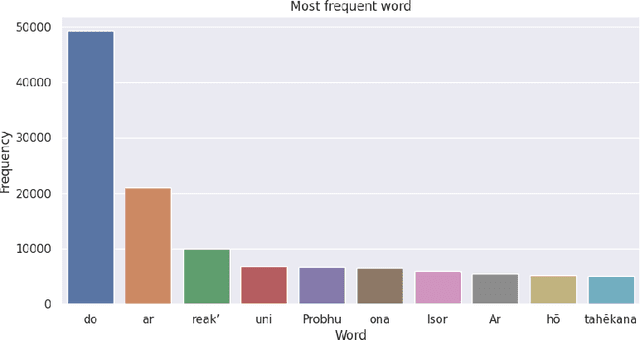

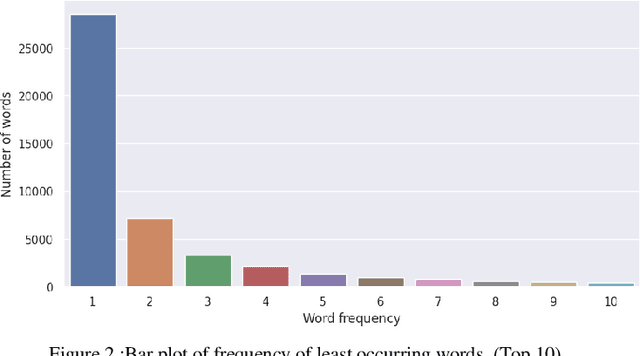

Around seven million individuals in India, Bangladesh, Bhutan, and Nepal speak Santali, positioning it as nearly the third most commonly used Austroasiatic language. Despite its prominence among the Austroasiatic language family's Munda subfamily, Santali lacks global recognition. Currently, no translation models exist for the Santali language. Our paper aims to include Santali to the NPL spectrum. We aim to examine the feasibility of building Santali translation models based on available Santali corpora. The paper successfully addressed the low-resource problem and, with promising results, examined the possibility of creating a functional Santali machine translation model in a low-resource setup. Our study shows that Santali-English parallel corpus performs better when in transformers like mt5 as opposed to untrained transformers, proving that transfer learning can be a viable technique that works with Santali language. Besides the mT5 transformer, Santali-English performs better than Santali-Bangla parallel corpus as the mT5 has been trained in way more English data than Bangla data. Lastly, our study shows that with data augmentation, our model performs better.
Mapping Violence: Developing an Extensive Framework to Build a Bangla Sectarian Expression Dataset from Social Media Interactions
Apr 17, 2024Communal violence in online forums has become extremely prevalent in South Asia, where many communities of different cultures coexist and share resources. These societies exhibit a phenomenon characterized by strong bonds within their own groups and animosity towards others, leading to conflicts that frequently escalate into violent confrontations. To address this issue, we have developed the first comprehensive framework for the automatic detection of communal violence markers in online Bangla content accompanying the largest collection (13K raw sentences) of social media interactions that fall under the definition of four major violence class and their 16 coarse expressions. Our workflow introduces a 7-step expert annotation process incorporating insights from social scientists, linguists, and psychologists. By presenting data statistics and benchmarking performance using this dataset, we have determined that, aside from the category of Non-communal violence, Religio-communal violence is particularly pervasive in Bangla text. Moreover, we have substantiated the effectiveness of fine-tuning language models in identifying violent comments by conducting preliminary benchmarking on the state-of-the-art Bangla deep learning model.
IPA Transcription of Bengali Texts
Mar 29, 2024The International Phonetic Alphabet (IPA) serves to systematize phonemes in language, enabling precise textual representation of pronunciation. In Bengali phonology and phonetics, ongoing scholarly deliberations persist concerning the IPA standard and core Bengali phonemes. This work examines prior research, identifies current and potential issues, and suggests a framework for a Bengali IPA standard, facilitating linguistic analysis and NLP resource creation and downstream technology development. In this work, we present a comprehensive study of Bengali IPA transcription and introduce a novel IPA transcription framework incorporating a novel dataset with DL-based benchmarks.
bbOCR: An Open-source Multi-domain OCR Pipeline for Bengali Documents
Aug 22, 2023Despite the existence of numerous Optical Character Recognition (OCR) tools, the lack of comprehensive open-source systems hampers the progress of document digitization in various low-resource languages, including Bengali. Low-resource languages, especially those with an alphasyllabary writing system, suffer from the lack of large-scale datasets for various document OCR components such as word-level OCR, document layout extraction, and distortion correction; which are available as individual modules in high-resource languages. In this paper, we introduce Bengali$.$AI-BRACU-OCR (bbOCR): an open-source scalable document OCR system that can reconstruct Bengali documents into a structured searchable digitized format that leverages a novel Bengali text recognition model and two novel synthetic datasets. We present extensive component-level and system-level evaluation: both use a novel diversified evaluation dataset and comprehensive evaluation metrics. Our extensive evaluation suggests that our proposed solution is preferable over the current state-of-the-art Bengali OCR systems. The source codes and datasets are available here: https://bengaliai.github.io/bbocr.
OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking
May 15, 2023We present OOD-Speech, the first out-of-distribution (OOD) benchmarking dataset for Bengali automatic speech recognition (ASR). Being one of the most spoken languages globally, Bengali portrays large diversity in dialects and prosodic features, which demands ASR frameworks to be robust towards distribution shifts. For example, islamic religious sermons in Bengali are delivered with a tonality that is significantly different from regular speech. Our training dataset is collected via massively online crowdsourcing campaigns which resulted in 1177.94 hours collected and curated from $22,645$ native Bengali speakers from South Asia. Our test dataset comprises 23.03 hours of speech collected and manually annotated from 17 different sources, e.g., Bengali TV drama, Audiobook, Talk show, Online class, and Islamic sermons to name a few. OOD-Speech is jointly the largest publicly available speech dataset, as well as the first out-of-distribution ASR benchmarking dataset for Bengali.
Bengali Common Voice Speech Dataset for Automatic Speech Recognition
Jun 29, 2022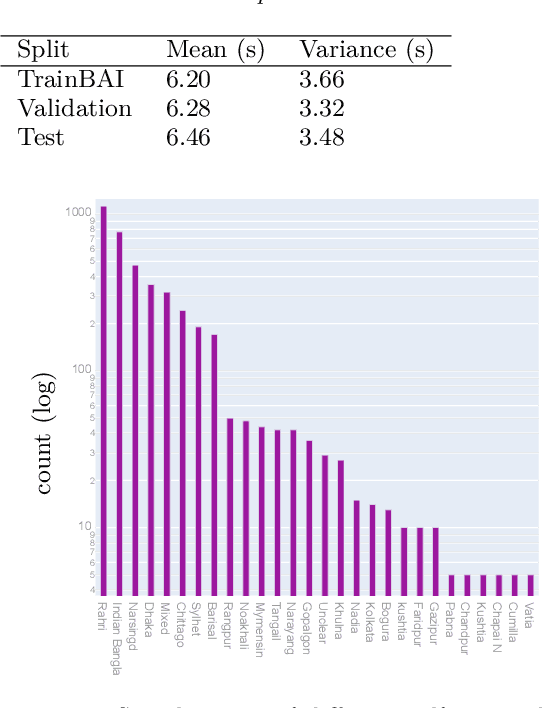
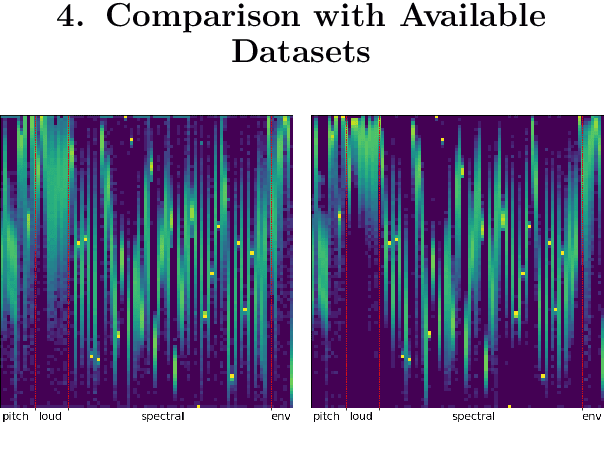

Bengali is one of the most spoken languages in the world with over 300 million speakers globally. Despite its popularity, research into the development of Bengali speech recognition systems is hindered due to the lack of diverse open-source datasets. As a way forward, we have crowdsourced the Bengali Common Voice Speech Dataset, which is a sentence-level automatic speech recognition corpus. Collected on the Mozilla Common Voice platform, the dataset is part of an ongoing campaign that has led to the collection of over 400 hours of data in 2 months and is growing rapidly. Our analysis shows that this dataset has more speaker, phoneme, and environmental diversity compared to the OpenSLR Bengali ASR dataset, the largest existing open-source Bengali speech dataset. We present insights obtained from the dataset and discuss key linguistic challenges that need to be addressed in future versions. Additionally, we report the current performance of a few Automatic Speech Recognition (ASR) algorithms and set a benchmark for future research.