 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgebbOCR: An Open-source Multi-domain OCR Pipeline for Bengali Documents
Aug 22, 2023Despite the existence of numerous Optical Character Recognition (OCR) tools, the lack of comprehensive open-source systems hampers the progress of document digitization in various low-resource languages, including Bengali. Low-resource languages, especially those with an alphasyllabary writing system, suffer from the lack of large-scale datasets for various document OCR components such as word-level OCR, document layout extraction, and distortion correction; which are available as individual modules in high-resource languages. In this paper, we introduce Bengali$.$AI-BRACU-OCR (bbOCR): an open-source scalable document OCR system that can reconstruct Bengali documents into a structured searchable digitized format that leverages a novel Bengali text recognition model and two novel synthetic datasets. We present extensive component-level and system-level evaluation: both use a novel diversified evaluation dataset and comprehensive evaluation metrics. Our extensive evaluation suggests that our proposed solution is preferable over the current state-of-the-art Bengali OCR systems. The source codes and datasets are available here: https://bengaliai.github.io/bbocr.
Bengali Common Voice Speech Dataset for Automatic Speech Recognition
Jun 29, 2022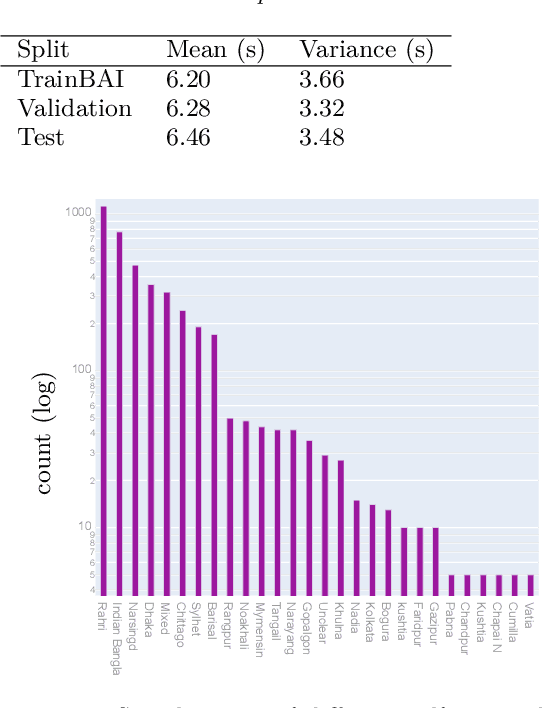
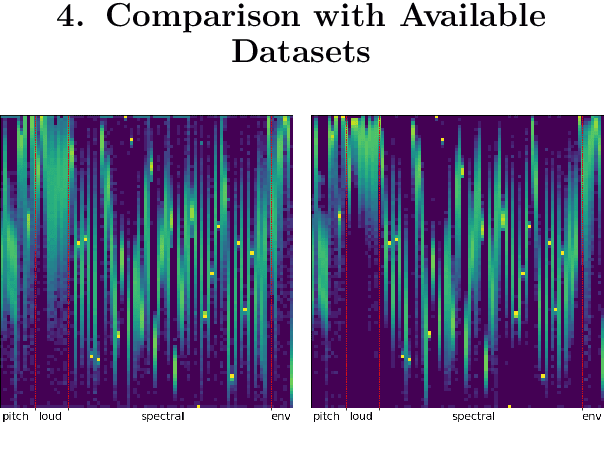

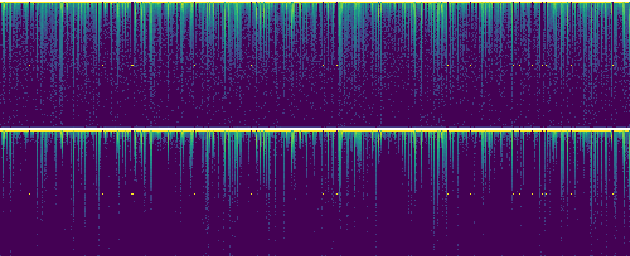
Bengali is one of the most spoken languages in the world with over 300 million speakers globally. Despite its popularity, research into the development of Bengali speech recognition systems is hindered due to the lack of diverse open-source datasets. As a way forward, we have crowdsourced the Bengali Common Voice Speech Dataset, which is a sentence-level automatic speech recognition corpus. Collected on the Mozilla Common Voice platform, the dataset is part of an ongoing campaign that has led to the collection of over 400 hours of data in 2 months and is growing rapidly. Our analysis shows that this dataset has more speaker, phoneme, and environmental diversity compared to the OpenSLR Bengali ASR dataset, the largest existing open-source Bengali speech dataset. We present insights obtained from the dataset and discuss key linguistic challenges that need to be addressed in future versions. Additionally, we report the current performance of a few Automatic Speech Recognition (ASR) algorithms and set a benchmark for future research.