 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable Vision-Language Model Framework with Adaptive PID-Tversky Loss for Lumbar Spinal Stenosis Diagnosis
Apr 02, 2026Lumbar Spinal Stenosis (LSS) diagnosis remains a critical clinical challenge, with diagnosis heavily dependent on labor-intensive manual interpretation of multi-view Magnetic Resonance Imaging (MRI), leading to substantial inter-observer variability and diagnostic delays. Existing vision-language models simultaneously fail to address the extreme class imbalance prevalent in clinical segmentation datasets while preserving spatial accuracy, primarily due to global pooling mechanisms that discard crucial anatomical hierarchies. We present an end-to-end Explainable Vision-Language Model framework designed to overcome these limitations, achieved through two principal objectives. We propose a Spatial Patch Cross-Attention module that enables precise, text-directed localization of spinal anomalies with spatial precision. A novel Adaptive PID-Tversky Loss function by integrating control theory principles dynamically further modifies training penalties to specifically address difficult, under-segmented minority instances. By incorporating foundational VLMs alongside an Automated Radiology Report Generation module, our framework demonstrates considerable performance: a diagnostic classification accuracy of 90.69%, a macro-averaged Dice score of 0.9512 for segmentation, and a CIDEr score of 92.80%. Furthermore, the framework shows explainability by converting complex segmentation predictions into radiologist-style clinical reports, thereby establishing a new benchmark for transparent, interpretable AI in clinical medical imaging that keeps essential human supervision while enhancing diagnostic capabilities.
Less Is More? Selective Visual Attention to High-Importance Regions for Multimodal Radiology Summarization
Mar 31, 2026Automated radiology report summarization aims to distill verbose findings into concise clinical impressions, but existing multimodal models often struggle with visual noise and fail to meaningfully improve over strong text-only baselines in the FINDINGS $\to$ IMPRESSION transformation. We challenge two prevailing assumptions: (1) that more visual input is always better, and (2) that multimodal models add limited value when findings already contain rich image-derived detail. Through controlled ablations on MIMIC-CXR benchmark, we show that selectively focusing on pathology-relevant visual patches rather than full images yields substantially better performance. We introduce ViTAS, Visual-Text Attention Summarizer, a multi-stage pipeline that combines ensemble-guided MedSAM2 lung segmentation, bidirectional cross-attention for multi-view fusion, Shapley-guided adaptive patch clustering, and hierarchical visual tokenization feeding a ViT. ViTAS achieves SOTA results with 29.25% BLEU-4 and 69.83% ROUGE-L, improved factual alignment in qualitative analysis, and the highest expert-rated human evaluation scores. Our findings demonstrate that less but more relevant visual input is not only sufficient but superior for multimodal radiology summarization.
SSTAF: Spatial-Spectral-Temporal Attention Fusion Transformer for Motor Imagery Classification
Apr 17, 2025Brain-computer interfaces (BCI) in electroencephalography (EEG)-based motor imagery classification offer promising solutions in neurorehabilitation and assistive technologies by enabling communication between the brain and external devices. However, the non-stationary nature of EEG signals and significant inter-subject variability cause substantial challenges for developing robust cross-subject classification models. This paper introduces a novel Spatial-Spectral-Temporal Attention Fusion (SSTAF) Transformer specifically designed for upper-limb motor imagery classification. Our architecture consists of a spectral transformer and a spatial transformer, followed by a transformer block and a classifier network. Each module is integrated with attention mechanisms that dynamically attend to the most discriminative patterns across multiple domains, such as spectral frequencies, spatial electrode locations, and temporal dynamics. The short-time Fourier transform is incorporated to extract features in the time-frequency domain to make it easier for the model to obtain a better feature distinction. We evaluated our SSTAF Transformer model on two publicly available datasets, the EEGMMIDB dataset, and BCI Competition IV-2a. SSTAF Transformer achieves an accuracy of 76.83% and 68.30% in the data sets, respectively, outperforms traditional CNN-based architectures and a few existing transformer-based approaches.
FunnelNet: An End-to-End Deep Learning Framework to Monitor Digital Heart Murmur in Real-Time
May 10, 2024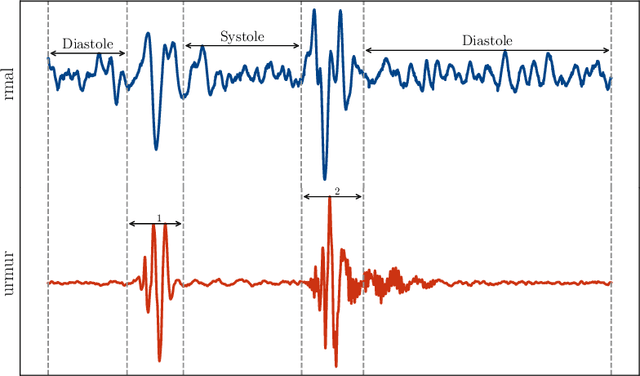
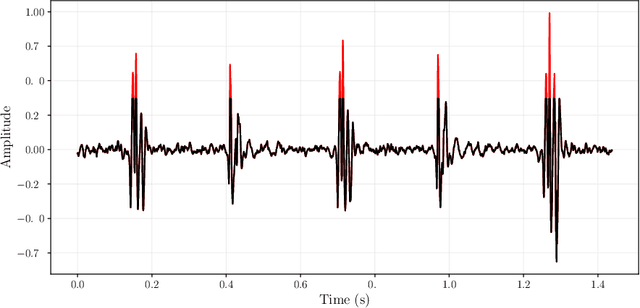
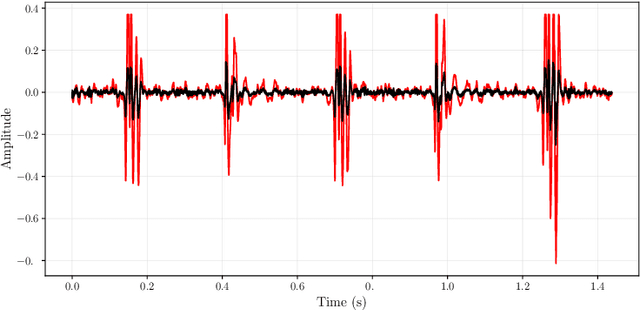
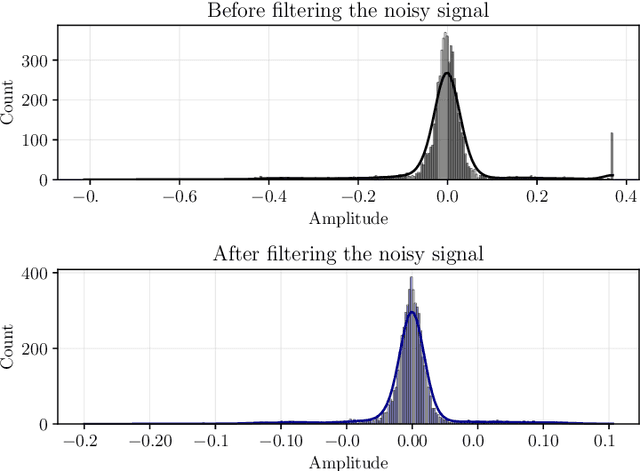
Objective: Heart murmurs are abnormal sounds caused by turbulent blood flow within the heart. Several diagnostic methods are available to detect heart murmurs and their severity, such as cardiac auscultation, echocardiography, phonocardiogram (PCG), etc. However, these methods have limitations, including extensive training and experience among healthcare providers, cost and accessibility of echocardiography, as well as noise interference and PCG data processing. This study aims to develop a novel end-to-end real-time heart murmur detection approach using traditional and depthwise separable convolutional networks. Methods: Continuous wavelet transform (CWT) was applied to extract meaningful features from the PCG data. The proposed network has three parts: the Squeeze net, the Bottleneck, and the Expansion net. The Squeeze net generates a compressed data representation, whereas the Bottleneck layer reduces computational complexity using a depthwise-separable convolutional network. The Expansion net is responsible for up-sampling the compressed data to a higher dimension, capturing tiny details of the representative data. Results: For evaluation, we used four publicly available datasets and achieved state-of-the-art performance in all datasets. Furthermore, we tested our proposed network on two resource-constrained devices: a Raspberry PI and an Android device, stripping it down into a tiny machine learning model (TinyML), achieving a maximum of 99.70%. Conclusion: The proposed model offers a deep learning framework for real-time accurate heart murmur detection within limited resources. Significance: It will significantly result in more accessible and practical medical services and reduced diagnosis time to assist medical professionals. The code is publicly available at TBA.
bbOCR: An Open-source Multi-domain OCR Pipeline for Bengali Documents
Aug 22, 2023Despite the existence of numerous Optical Character Recognition (OCR) tools, the lack of comprehensive open-source systems hampers the progress of document digitization in various low-resource languages, including Bengali. Low-resource languages, especially those with an alphasyllabary writing system, suffer from the lack of large-scale datasets for various document OCR components such as word-level OCR, document layout extraction, and distortion correction; which are available as individual modules in high-resource languages. In this paper, we introduce Bengali$.$AI-BRACU-OCR (bbOCR): an open-source scalable document OCR system that can reconstruct Bengali documents into a structured searchable digitized format that leverages a novel Bengali text recognition model and two novel synthetic datasets. We present extensive component-level and system-level evaluation: both use a novel diversified evaluation dataset and comprehensive evaluation metrics. Our extensive evaluation suggests that our proposed solution is preferable over the current state-of-the-art Bengali OCR systems. The source codes and datasets are available here: https://bengaliai.github.io/bbocr.