 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgebbOCR: An Open-source Multi-domain OCR Pipeline for Bengali Documents
Aug 22, 2023Despite the existence of numerous Optical Character Recognition (OCR) tools, the lack of comprehensive open-source systems hampers the progress of document digitization in various low-resource languages, including Bengali. Low-resource languages, especially those with an alphasyllabary writing system, suffer from the lack of large-scale datasets for various document OCR components such as word-level OCR, document layout extraction, and distortion correction; which are available as individual modules in high-resource languages. In this paper, we introduce Bengali$.$AI-BRACU-OCR (bbOCR): an open-source scalable document OCR system that can reconstruct Bengali documents into a structured searchable digitized format that leverages a novel Bengali text recognition model and two novel synthetic datasets. We present extensive component-level and system-level evaluation: both use a novel diversified evaluation dataset and comprehensive evaluation metrics. Our extensive evaluation suggests that our proposed solution is preferable over the current state-of-the-art Bengali OCR systems. The source codes and datasets are available here: https://bengaliai.github.io/bbocr.
Sketch2FullStack: Generating Skeleton Code of Full Stack Website and Application from Sketch using Deep Learning and Computer Vision
Nov 26, 2022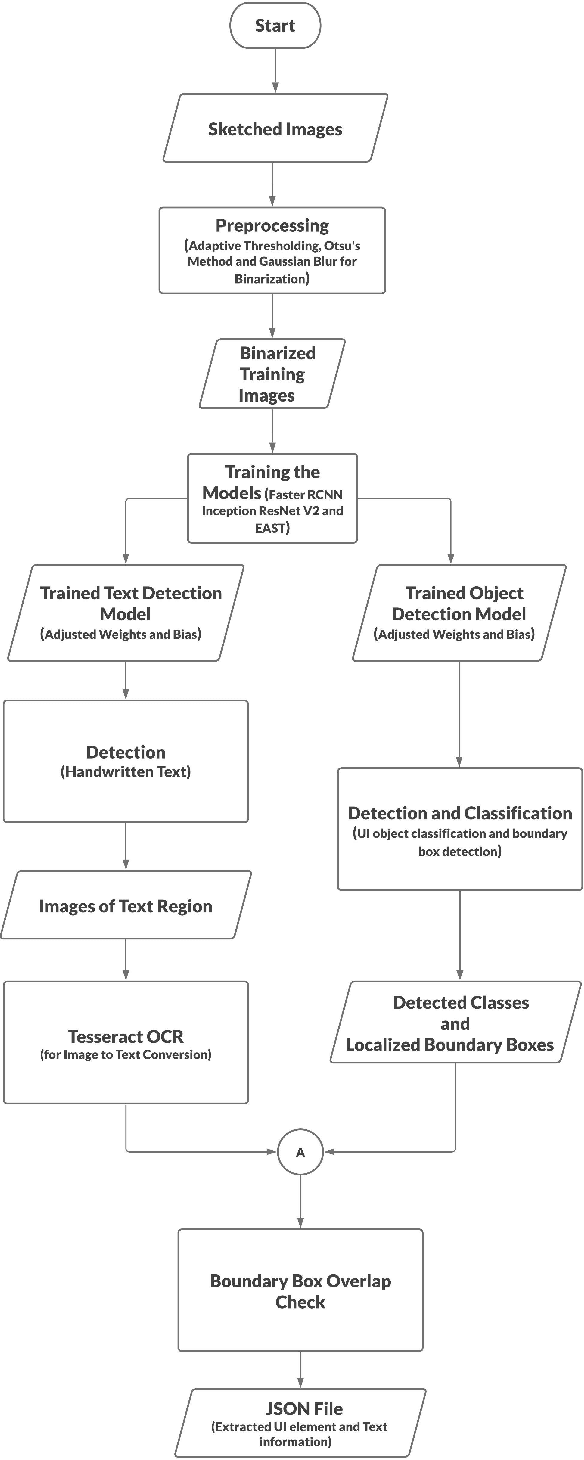

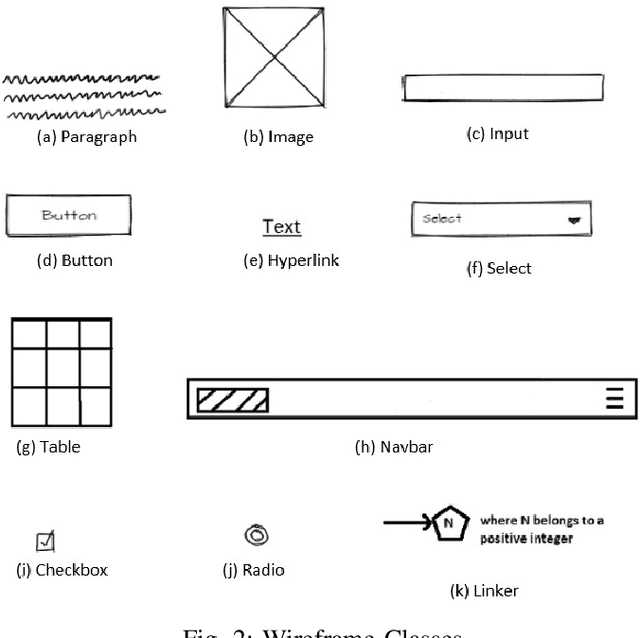
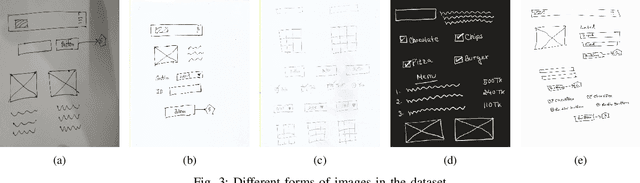
For a full-stack web or app development, it requires a software firm or more specifically a team of experienced developers to contribute a large portion of their time and resources to design the website and then convert it to code. As a result, the efficiency of the development team is significantly reduced when it comes to converting UI wireframes and database schemas into an actual working system. It would save valuable resources and fasten the overall workflow if the clients or developers can automate this process of converting the pre-made full-stack website design to get a partially working if not fully working code. In this paper, we present a novel approach of generating the skeleton code from sketched images using Deep Learning and Computer Vision approaches. The dataset for training are first-hand sketched images of low fidelity wireframes, database schemas and class diagrams. The approach consists of three parts. First, the front-end or UI elements detection and extraction from custom-made UI wireframes. Second, individual database table creation from schema designs and lastly, creating a class file from class diagrams.