 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind Maya: Building a Multilingual Vision Language Model
May 15, 2025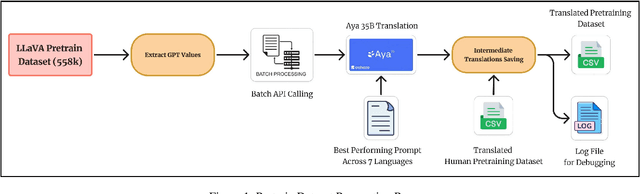
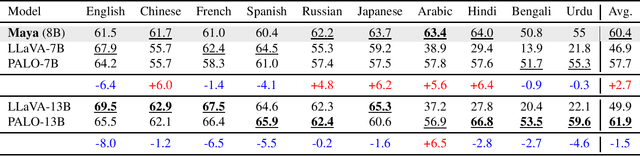
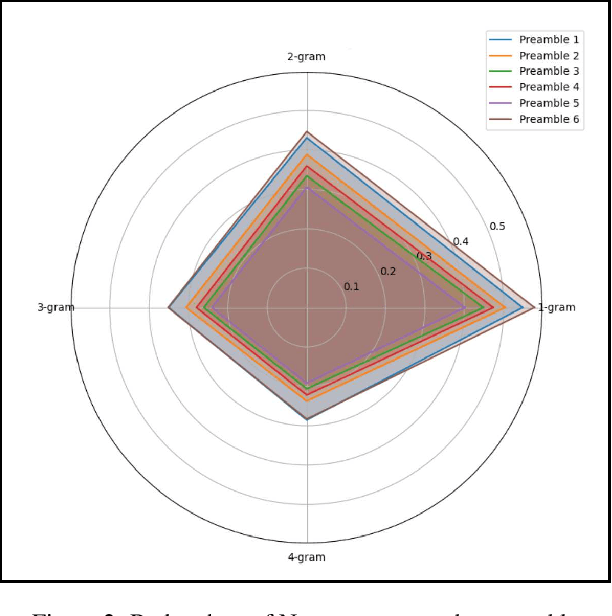

In recent times, we have seen a rapid development of large Vision-Language Models (VLMs). They have shown impressive results on academic benchmarks, primarily in widely spoken languages but lack performance on low-resource languages and varied cultural contexts. To address these limitations, we introduce Maya, an open-source Multilingual VLM. Our contributions are: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; and 2) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
Understanding and Mitigating Toxicity in Image-Text Pretraining Datasets: A Case Study on LLaVA
May 09, 2025Pretraining datasets are foundational to the development of multimodal models, yet they often have inherent biases and toxic content from the web-scale corpora they are sourced from. In this paper, we investigate the prevalence of toxicity in LLaVA image-text pretraining dataset, examining how harmful content manifests in different modalities. We present a comprehensive analysis of common toxicity categories and propose targeted mitigation strategies, resulting in the creation of a refined toxicity-mitigated dataset. This dataset removes 7,531 of toxic image-text pairs in the LLaVA pre-training dataset. We offer guidelines for implementing robust toxicity detection pipelines. Our findings underscore the need to actively identify and filter toxic content - such as hate speech, explicit imagery, and targeted harassment - to build more responsible and equitable multimodal systems. The toxicity-mitigated dataset is open source and is available for further research.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
Maya: An Instruction Finetuned Multilingual Multimodal Model
Dec 10, 2024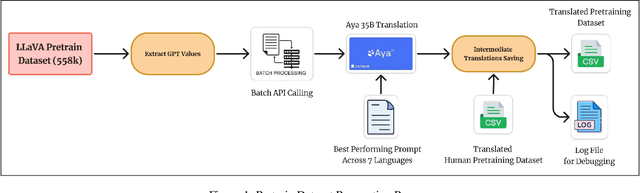
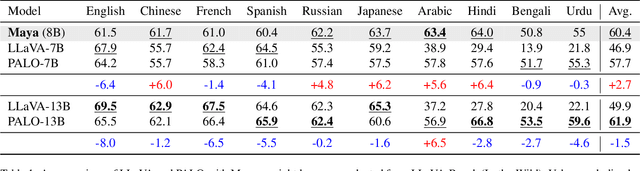
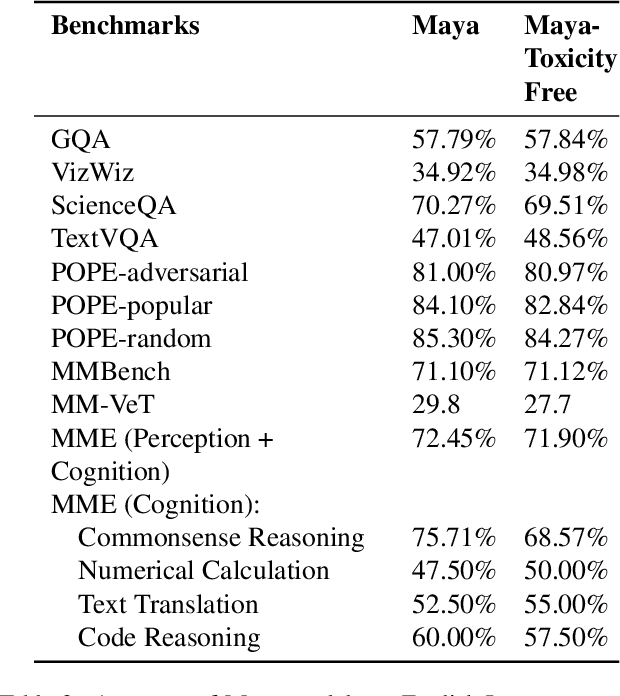
The rapid development of large Vision-Language Models (VLMs) has led to impressive results on academic benchmarks, primarily in widely spoken languages. However, significant gaps remain in the ability of current VLMs to handle low-resource languages and varied cultural contexts, largely due to a lack of high-quality, diverse, and safety-vetted data. Consequently, these models often struggle to understand low-resource languages and cultural nuances in a manner free from toxicity. To address these limitations, we introduce Maya, an open-source Multimodal Multilingual model. Our contributions are threefold: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; 2) a thorough analysis of toxicity within the LLaVA dataset, followed by the creation of a novel toxicity-free version across eight languages; and 3) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Bangla Grammatical Error Detection Leveraging Transformer-based Token Classification
Nov 13, 2024



Bangla is the seventh most spoken language by a total number of speakers in the world, and yet the development of an automated grammar checker in this language is an understudied problem. Bangla grammatical error detection is a task of detecting sub-strings of a Bangla text that contain grammatical, punctuation, or spelling errors, which is crucial for developing an automated Bangla typing assistant. Our approach involves breaking down the task as a token classification problem and utilizing state-of-the-art transformer-based models. Finally, we combine the output of these models and apply rule-based post-processing to generate a more reliable and comprehensive result. Our system is evaluated on a dataset consisting of over 25,000 texts from various sources. Our best model achieves a Levenshtein distance score of 1.04. Finally, we provide a detailed analysis of different components of our system.
MM-Eval: A Multilingual Meta-Evaluation Benchmark for LLM-as-a-Judge and Reward Models
Oct 23, 2024



Large language models (LLMs) are commonly used as evaluators in tasks (e.g., reward modeling, LLM-as-a-judge), where they act as proxies for human preferences or judgments. This leads to the need for meta-evaluation: evaluating the credibility of LLMs as evaluators. However, existing benchmarks primarily focus on English, offering limited insight into LLMs' effectiveness as evaluators in non-English contexts. To address this, we introduce MM-Eval, a multilingual meta-evaluation benchmark that covers 18 languages across six categories. MM-Eval evaluates various dimensions, including language-specific challenges like linguistics and language hallucinations. Evaluation results show that both proprietary and open-source language models have considerable room for improvement. Further analysis reveals a tendency for these models to assign middle-ground scores to low-resource languages. We publicly release our benchmark and code.
M-RewardBench: Evaluating Reward Models in Multilingual Settings
Oct 20, 2024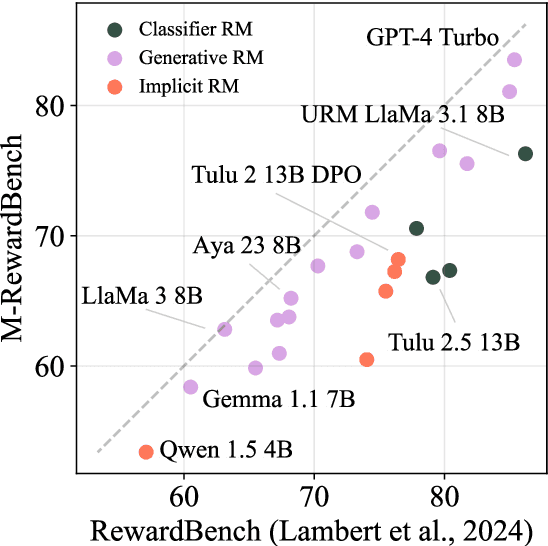



Reward models (RMs) have driven the state-of-the-art performance of LLMs today by enabling the integration of human feedback into the language modeling process. However, RMs are primarily trained and evaluated in English, and their capabilities in multilingual settings remain largely understudied. In this work, we conduct a systematic evaluation of several reward models in multilingual settings. We first construct the first-of-its-kind multilingual RM evaluation benchmark, M-RewardBench, consisting of 2.87k preference instances for 23 typologically diverse languages, that tests the chat, safety, reasoning, and translation capabilities of RMs. We then rigorously evaluate a wide range of reward models on M-RewardBench, offering fresh insights into their performance across diverse languages. We identify a significant gap in RMs' performances between English and non-English languages and show that RM preferences can change substantially from one language to another. We also present several findings on how different multilingual aspects impact RM performance. Specifically, we show that the performance of RMs is improved with improved translation quality. Similarly, we demonstrate that the models exhibit better performance for high-resource languages. We release M-RewardBench dataset and the codebase in this study to facilitate a better understanding of RM evaluation in multilingual settings.
Open-RAG: Enhanced Retrieval-Augmented Reasoning with Open-Source Large Language Models
Oct 02, 2024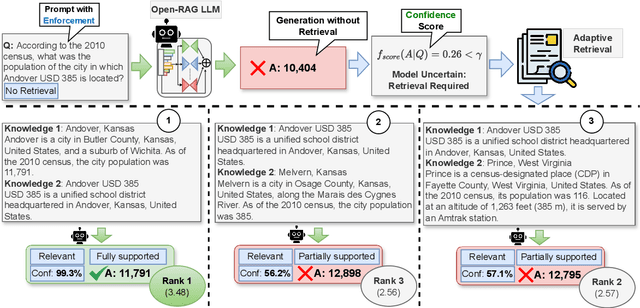
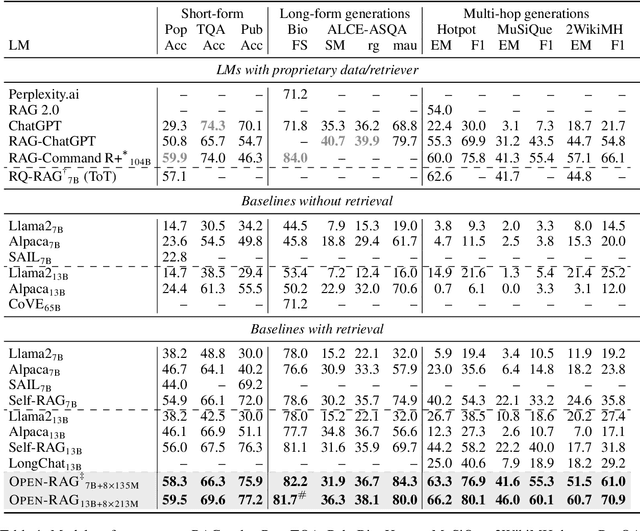
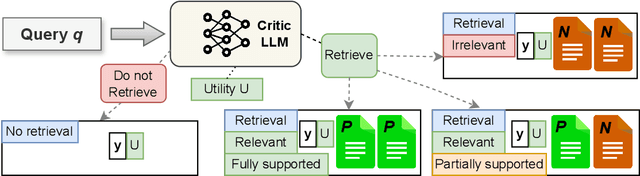
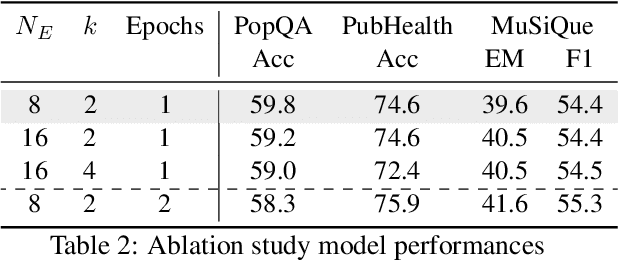
Retrieval-Augmented Generation (RAG) has been shown to enhance the factual accuracy of Large Language Models (LLMs), but existing methods often suffer from limited reasoning capabilities in effectively using the retrieved evidence, particularly when using open-source LLMs. To mitigate this gap, we introduce a novel framework, Open-RAG, designed to enhance reasoning capabilities in RAG with open-source LLMs. Our framework transforms an arbitrary dense LLM into a parameter-efficient sparse mixture of experts (MoE) model capable of handling complex reasoning tasks, including both single- and multi-hop queries. Open-RAG uniquely trains the model to navigate challenging distractors that appear relevant but are misleading. As a result, Open-RAG leverages latent learning, dynamically selecting relevant experts and integrating external knowledge effectively for more accurate and contextually relevant responses. In addition, we propose a hybrid adaptive retrieval method to determine retrieval necessity and balance the trade-off between performance gain and inference speed. Experimental results show that the Llama2-7B-based Open-RAG outperforms state-of-the-art LLMs and RAG models such as ChatGPT, Self-RAG, and Command R+ in various knowledge-intensive tasks. We open-source our code and models at https://openragmoe.github.io/
bbOCR: An Open-source Multi-domain OCR Pipeline for Bengali Documents
Aug 22, 2023Despite the existence of numerous Optical Character Recognition (OCR) tools, the lack of comprehensive open-source systems hampers the progress of document digitization in various low-resource languages, including Bengali. Low-resource languages, especially those with an alphasyllabary writing system, suffer from the lack of large-scale datasets for various document OCR components such as word-level OCR, document layout extraction, and distortion correction; which are available as individual modules in high-resource languages. In this paper, we introduce Bengali$.$AI-BRACU-OCR (bbOCR): an open-source scalable document OCR system that can reconstruct Bengali documents into a structured searchable digitized format that leverages a novel Bengali text recognition model and two novel synthetic datasets. We present extensive component-level and system-level evaluation: both use a novel diversified evaluation dataset and comprehensive evaluation metrics. Our extensive evaluation suggests that our proposed solution is preferable over the current state-of-the-art Bengali OCR systems. The source codes and datasets are available here: https://bengaliai.github.io/bbocr.