 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Physics Steering in Video World Models via Concept Activation Vectors
May 23, 2026Video world models learn representations of physical dynamics, but controlling their physical expectations at inference time remains an open problem. Recent interpretability work identified a Physics Emergence Zone (PEZ), a group of middle transformer layers in VideoMAE where physical plausibility is represented separately from other visual features. However, it remained unclear whether this structure could be used to directly control the model's physics reasoning. We present physics steering, a training-free method that uses the weight vector of a linear probe at a PEZ layer as a Concept Activation Vector (CAV) and injects it into hidden states during inference. This shifts the model's physical expectations without changing any model weights. On the IntPhys benchmark, this intervention reliably shifts the model's plausibility judgment in either direction, depending on the steering sign. The effect appears only when the intervention is applied within the Physics Emergence Zone, suggesting that the relevant physics representation is localized there. We further find that physics is encoded separately from motion direction, and that different intuitive physics principles occupy distinct directions within this representation space. Together, these results show that physical reasoning in VideoMAE is not only readable, but also directly steerable.
Spatial Reasoning is Not a Free Lunch: A Controlled Study on LLaVA
Mar 13, 2026Vision-language models (VLMs) have advanced rapidly, yet they still struggle with basic spatial reasoning. Despite strong performance on general benchmarks, modern VLMs remain brittle at understanding 2D spatial relationships such as relative position, layout, and counting. We argue that this failure is not merely a data problem, but is closely tied to dominant design choices in current VLM pipelines: reliance on CLIP-style image encoders and the flattening of images into 1D token sequences with 1D positional encoding. We present a controlled diagnostic study within the LLaVA framework to isolate how these choices affect spatial grounding. We evaluate frontier models and LLaVA variants on a suite of spatial benchmarks, comparing CLIP-based encoders against alternatives trained with denser or generative objectives, as well as variants augmented with 2D positional encoding. Our results show consistent spatial performance gaps across models, and indicate that encoder objectives and positional structure shape spatial behavior, but do not fully resolve it.
The Spatial Blindspot of Vision-Language Models
Jan 15, 2026Vision-language models (VLMs) have advanced rapidly, but their ability to capture spatial relationships remains a blindspot. Current VLMs are typically built with contrastive language-image pretraining (CLIP) style image encoders. The training recipe often flattens images into 1D patch sequences, discarding the 2D structure necessary for spatial reasoning. We argue that this lack of spatial awareness is a missing dimension in VLM design and a bottleneck for applications requiring spatial grounding, such as robotics and embodied AI. To address this, we investigate (i) image encoders trained with alternative objectives and (ii) 2D positional encodings. Our experiments show that these architectural choices can lead to improved spatial reasoning on several benchmarks.
Behind Maya: Building a Multilingual Vision Language Model
May 15, 2025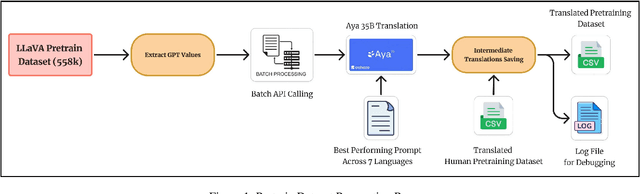
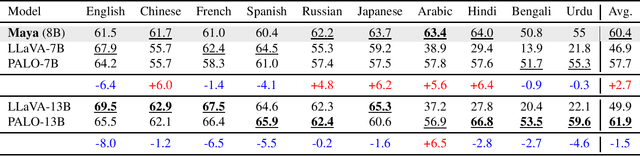
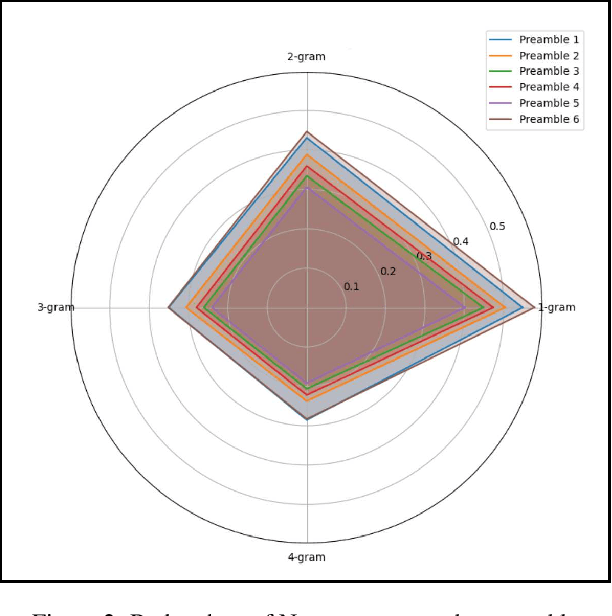

In recent times, we have seen a rapid development of large Vision-Language Models (VLMs). They have shown impressive results on academic benchmarks, primarily in widely spoken languages but lack performance on low-resource languages and varied cultural contexts. To address these limitations, we introduce Maya, an open-source Multilingual VLM. Our contributions are: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; and 2) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
Understanding and Mitigating Toxicity in Image-Text Pretraining Datasets: A Case Study on LLaVA
May 09, 2025Pretraining datasets are foundational to the development of multimodal models, yet they often have inherent biases and toxic content from the web-scale corpora they are sourced from. In this paper, we investigate the prevalence of toxicity in LLaVA image-text pretraining dataset, examining how harmful content manifests in different modalities. We present a comprehensive analysis of common toxicity categories and propose targeted mitigation strategies, resulting in the creation of a refined toxicity-mitigated dataset. This dataset removes 7,531 of toxic image-text pairs in the LLaVA pre-training dataset. We offer guidelines for implementing robust toxicity detection pipelines. Our findings underscore the need to actively identify and filter toxic content - such as hate speech, explicit imagery, and targeted harassment - to build more responsible and equitable multimodal systems. The toxicity-mitigated dataset is open source and is available for further research.
Maya: An Instruction Finetuned Multilingual Multimodal Model
Dec 10, 2024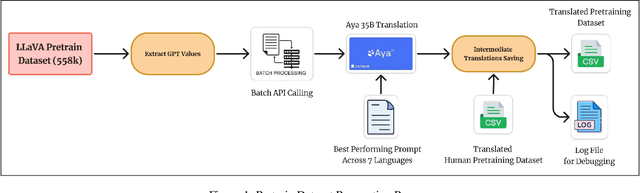
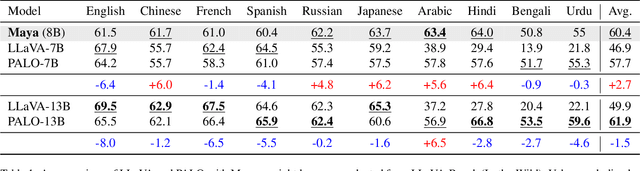
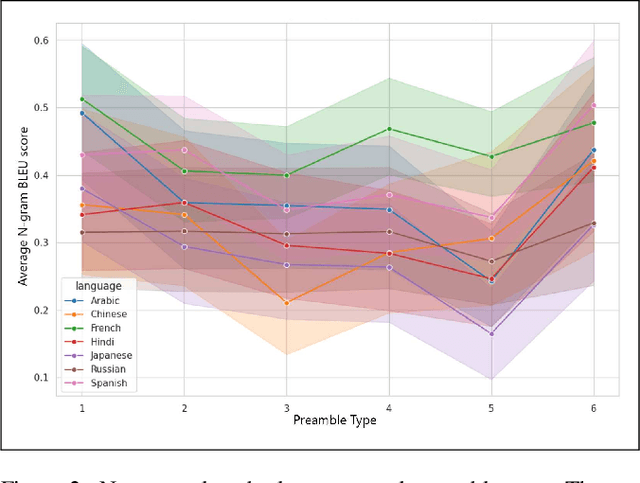
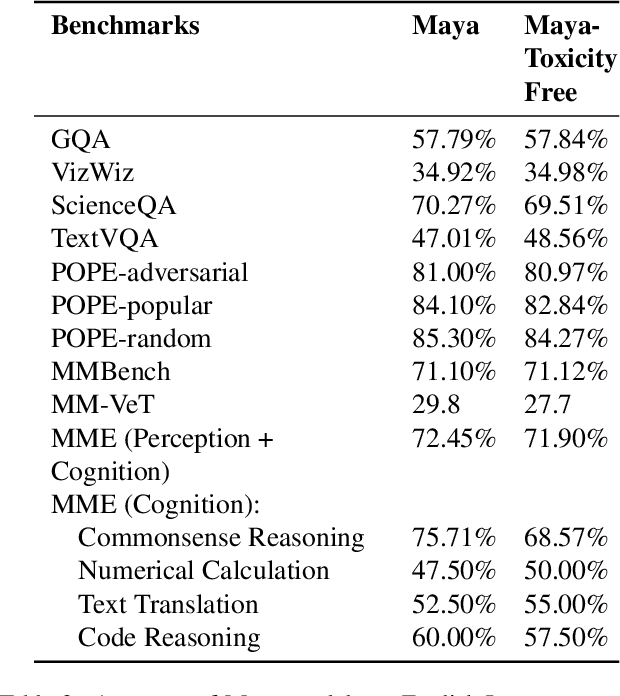
The rapid development of large Vision-Language Models (VLMs) has led to impressive results on academic benchmarks, primarily in widely spoken languages. However, significant gaps remain in the ability of current VLMs to handle low-resource languages and varied cultural contexts, largely due to a lack of high-quality, diverse, and safety-vetted data. Consequently, these models often struggle to understand low-resource languages and cultural nuances in a manner free from toxicity. To address these limitations, we introduce Maya, an open-source Multimodal Multilingual model. Our contributions are threefold: 1) a multilingual image-text pretraining dataset in eight languages, based on the LLaVA pretraining dataset; 2) a thorough analysis of toxicity within the LLaVA dataset, followed by the creation of a novel toxicity-free version across eight languages; and 3) a multilingual image-text model supporting these languages, enhancing cultural and linguistic comprehension in vision-language tasks. Code available at https://github.com/nahidalam/maya.
Vision Transformers for Mobile Applications: A Short Survey
May 30, 2023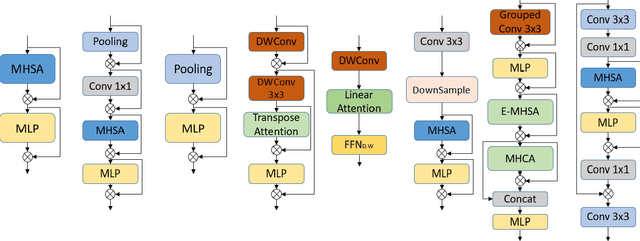
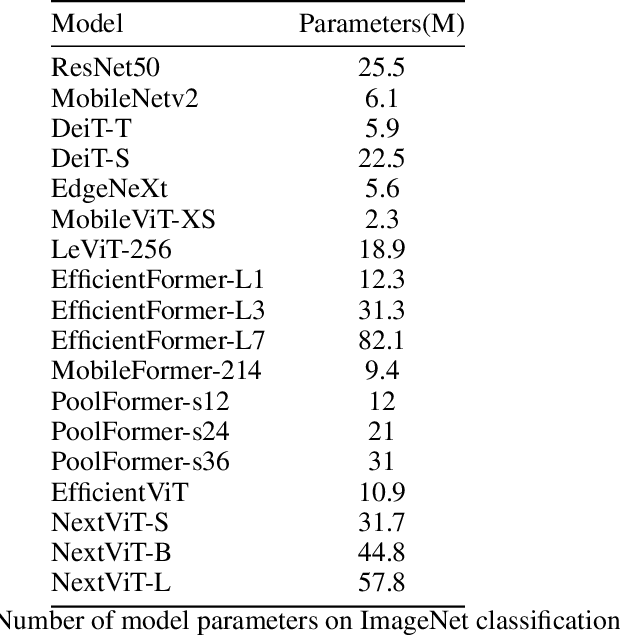
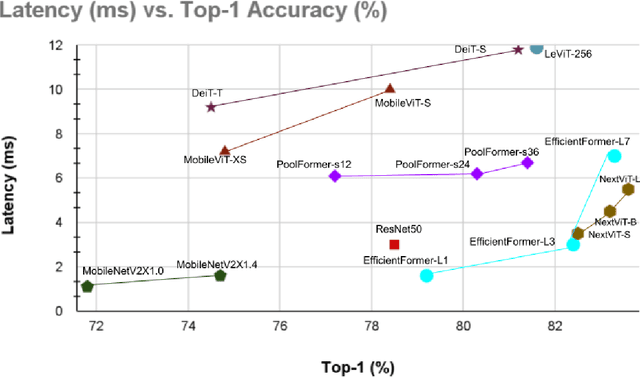
Vision Transformers (ViTs) have demonstrated state-of-the-art performance on many Computer Vision Tasks. Unfortunately, deploying these large-scale ViTs is resource-consuming and impossible for many mobile devices. While most in the community are building for larger and larger ViTs, we ask a completely opposite question: How small can a ViT be within the tradeoffs of accuracy and inference latency that make it suitable for mobile deployment? We look into a few ViTs specifically designed for mobile applications and observe that they modify the transformer's architecture or are built around the combination of CNN and transformer. Recent work has also attempted to create sparse ViT networks and proposed alternatives to the attention module. In this paper, we study these architectures, identify the challenges and analyze what really makes a vision transformer suitable for mobile applications. We aim to serve as a baseline for future research direction and hopefully lay the foundation to choose the exemplary vision transformer architecture for your application running on mobile devices.