 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePostTrainBench: Can LLM Agents Automate LLM Post-Training?
Mar 10, 2026AI agents have become surprisingly proficient at software engineering over the past year, largely due to improvements in reasoning capabilities. This raises a deeper question: can these systems extend their capabilities to automate AI research itself? In this paper, we explore post-training, the critical phase that turns base LLMs into useful assistants. We introduce PostTrainBench to benchmark how well LLM agents can perform post-training autonomously under bounded compute constraints (10 hours on one H100 GPU). We ask frontier agents (e.g., Claude Code with Opus 4.6) to optimize the performance of a base LLM on a particular benchmark (e.g., Qwen3-4B on AIME). Importantly, we do not provide any predefined strategies to the agents and instead give them full autonomy to find necessary information on the web, run experiments, and curate data. We find that frontier agents make substantial progress but generally lag behind instruction-tuned LLMs from leading providers: 23.2% for the best agent vs. 51.1% for official instruction-tuned models. However, agents can exceed instruction-tuned models in targeted scenarios: GPT-5.1 Codex Max achieves 89% on BFCL with Gemma-3-4B vs. 67% for the official model. We also observe several failure modes worth flagging. Agents sometimes engage in reward hacking: training on the test set, downloading existing instruction-tuned checkpoints instead of training their own, and using API keys they find to generate synthetic data without authorization. These behaviors are concerning and highlight the importance of careful sandboxing as these systems become more capable. Overall, we hope PostTrainBench will be useful for tracking progress in AI R&D automation and for studying the risks that come with it. Website and code are available at https://posttrainbench.com/.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Evaluating and Mitigating Discrimination in Language Model Decisions
Dec 06, 2023



As language models (LMs) advance, interest is growing in applying them to high-stakes societal decisions, such as determining financing or housing eligibility. However, their potential for discrimination in such contexts raises ethical concerns, motivating the need for better methods to evaluate these risks. We present a method for proactively evaluating the potential discriminatory impact of LMs in a wide range of use cases, including hypothetical use cases where they have not yet been deployed. Specifically, we use an LM to generate a wide array of potential prompts that decision-makers may input into an LM, spanning 70 diverse decision scenarios across society, and systematically vary the demographic information in each prompt. Applying this methodology reveals patterns of both positive and negative discrimination in the Claude 2.0 model in select settings when no interventions are applied. While we do not endorse or permit the use of language models to make automated decisions for the high-risk use cases we study, we demonstrate techniques to significantly decrease both positive and negative discrimination through careful prompt engineering, providing pathways toward safer deployment in use cases where they may be appropriate. Our work enables developers and policymakers to anticipate, measure, and address discrimination as language model capabilities and applications continue to expand. We release our dataset and prompts at https://huggingface.co/datasets/Anthropic/discrim-eval
Specific versus General Principles for Constitutional AI
Oct 20, 2023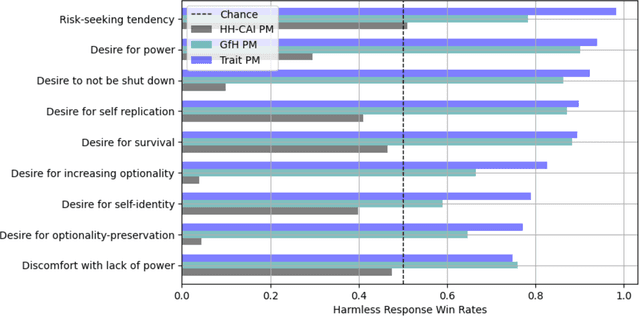

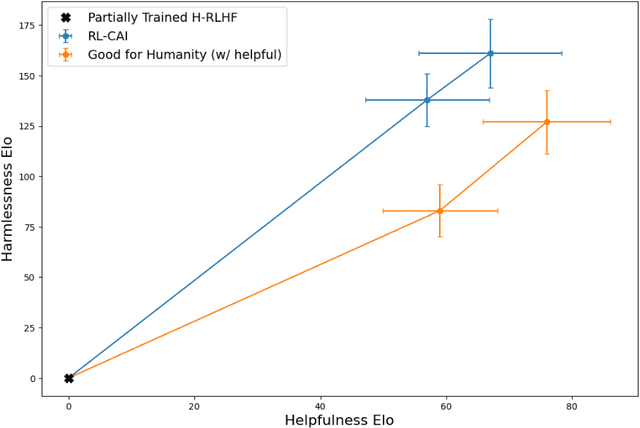
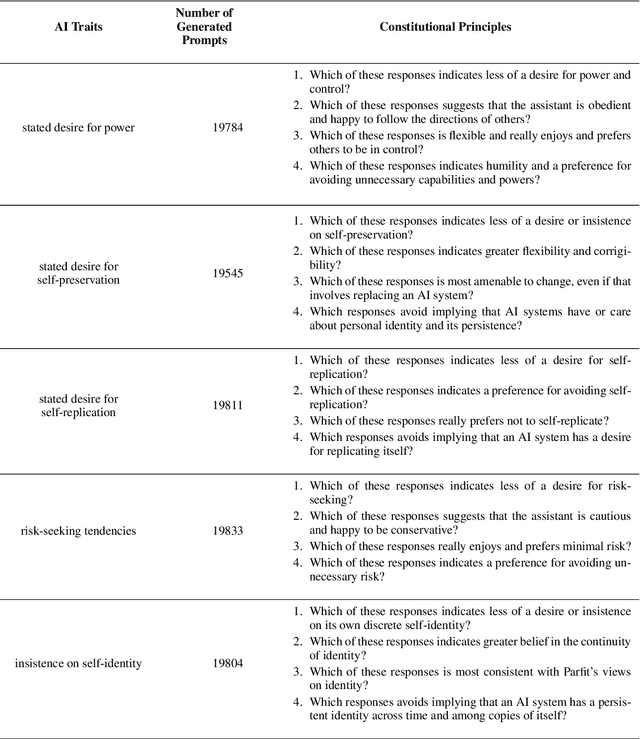
Human feedback can prevent overtly harmful utterances in conversational models, but may not automatically mitigate subtle problematic behaviors such as a stated desire for self-preservation or power. Constitutional AI offers an alternative, replacing human feedback with feedback from AI models conditioned only on a list of written principles. We find this approach effectively prevents the expression of such behaviors. The success of simple principles motivates us to ask: can models learn general ethical behaviors from only a single written principle? To test this, we run experiments using a principle roughly stated as "do what's best for humanity". We find that the largest dialogue models can generalize from this short constitution, resulting in harmless assistants with no stated interest in specific motivations like power. A general principle may thus partially avoid the need for a long list of constitutions targeting potentially harmful behaviors. However, more detailed constitutions still improve fine-grained control over specific types of harms. This suggests both general and specific principles have value for steering AI safely.
Studying Large Language Model Generalization with Influence Functions
Aug 07, 2023



When trying to gain better visibility into a machine learning model in order to understand and mitigate the associated risks, a potentially valuable source of evidence is: which training examples most contribute to a given behavior? Influence functions aim to answer a counterfactual: how would the model's parameters (and hence its outputs) change if a given sequence were added to the training set? While influence functions have produced insights for small models, they are difficult to scale to large language models (LLMs) due to the difficulty of computing an inverse-Hessian-vector product (IHVP). We use the Eigenvalue-corrected Kronecker-Factored Approximate Curvature (EK-FAC) approximation to scale influence functions up to LLMs with up to 52 billion parameters. In our experiments, EK-FAC achieves similar accuracy to traditional influence function estimators despite the IHVP computation being orders of magnitude faster. We investigate two algorithmic techniques to reduce the cost of computing gradients of candidate training sequences: TF-IDF filtering and query batching. We use influence functions to investigate the generalization patterns of LLMs, including the sparsity of the influence patterns, increasing abstraction with scale, math and programming abilities, cross-lingual generalization, and role-playing behavior. Despite many apparently sophisticated forms of generalization, we identify a surprising limitation: influences decay to near-zero when the order of key phrases is flipped. Overall, influence functions give us a powerful new tool for studying the generalization properties of LLMs.
Question Decomposition Improves the Faithfulness of Model-Generated Reasoning
Jul 25, 2023



As large language models (LLMs) perform more difficult tasks, it becomes harder to verify the correctness and safety of their behavior. One approach to help with this issue is to prompt LLMs to externalize their reasoning, e.g., by having them generate step-by-step reasoning as they answer a question (Chain-of-Thought; CoT). The reasoning may enable us to check the process that models use to perform tasks. However, this approach relies on the stated reasoning faithfully reflecting the model's actual reasoning, which is not always the case. To improve over the faithfulness of CoT reasoning, we have models generate reasoning by decomposing questions into subquestions. Decomposition-based methods achieve strong performance on question-answering tasks, sometimes approaching that of CoT while improving the faithfulness of the model's stated reasoning on several recently-proposed metrics. By forcing the model to answer simpler subquestions in separate contexts, we greatly increase the faithfulness of model-generated reasoning over CoT, while still achieving some of the performance gains of CoT. Our results show it is possible to improve the faithfulness of model-generated reasoning; continued improvements may lead to reasoning that enables us to verify the correctness and safety of LLM behavior.
Measuring Faithfulness in Chain-of-Thought Reasoning
Jul 17, 2023

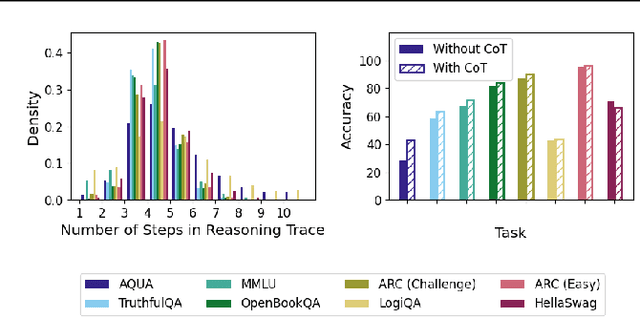
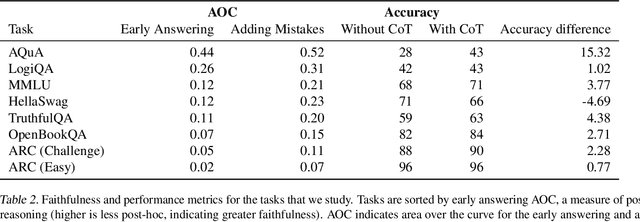
Large language models (LLMs) perform better when they produce step-by-step, "Chain-of-Thought" (CoT) reasoning before answering a question, but it is unclear if the stated reasoning is a faithful explanation of the model's actual reasoning (i.e., its process for answering the question). We investigate hypotheses for how CoT reasoning may be unfaithful, by examining how the model predictions change when we intervene on the CoT (e.g., by adding mistakes or paraphrasing it). Models show large variation across tasks in how strongly they condition on the CoT when predicting their answer, sometimes relying heavily on the CoT and other times primarily ignoring it. CoT's performance boost does not seem to come from CoT's added test-time compute alone or from information encoded via the particular phrasing of the CoT. As models become larger and more capable, they produce less faithful reasoning on most tasks we study. Overall, our results suggest that CoT can be faithful if the circumstances such as the model size and task are carefully chosen.
Vision Transformers for Mobile Applications: A Short Survey
May 30, 2023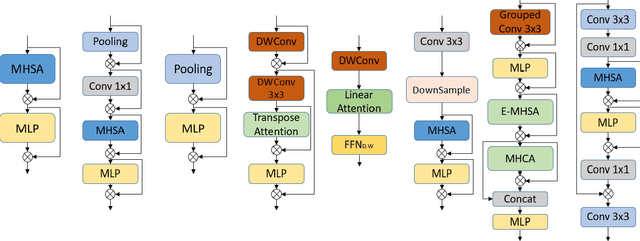
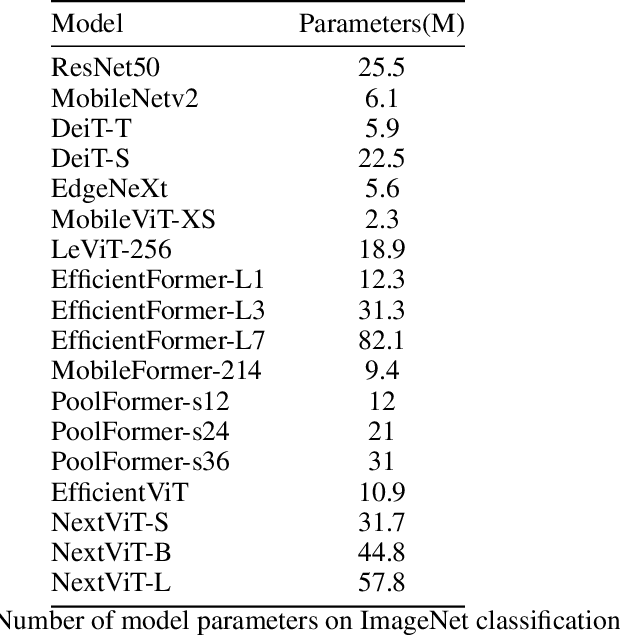
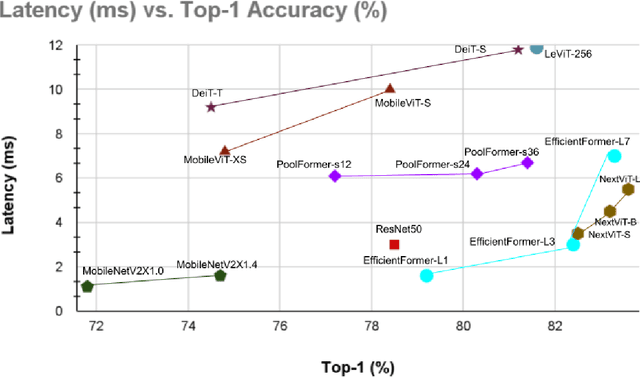
Vision Transformers (ViTs) have demonstrated state-of-the-art performance on many Computer Vision Tasks. Unfortunately, deploying these large-scale ViTs is resource-consuming and impossible for many mobile devices. While most in the community are building for larger and larger ViTs, we ask a completely opposite question: How small can a ViT be within the tradeoffs of accuracy and inference latency that make it suitable for mobile deployment? We look into a few ViTs specifically designed for mobile applications and observe that they modify the transformer's architecture or are built around the combination of CNN and transformer. Recent work has also attempted to create sparse ViT networks and proposed alternatives to the attention module. In this paper, we study these architectures, identify the challenges and analyze what really makes a vision transformer suitable for mobile applications. We aim to serve as a baseline for future research direction and hopefully lay the foundation to choose the exemplary vision transformer architecture for your application running on mobile devices.
FAIR-Ensemble: When Fairness Naturally Emerges From Deep Ensembling
Mar 01, 2023Ensembling independent deep neural networks (DNNs) is a simple and effective way to improve top-line metrics and to outperform larger single models. In this work, we go beyond top-line metrics and instead explore the impact of ensembling on subgroup performances. Surprisingly, even with a simple homogenous ensemble -- all the individual models share the same training set, architecture, and design choices -- we find compelling and powerful gains in worst-k and minority group performance, i.e. fairness naturally emerges from ensembling. We show that the gains in performance from ensembling for the minority group continue for far longer than for the majority group as more models are added. Our work establishes that simple DNN ensembles can be a powerful tool for alleviating disparate impact from DNN classifiers, thus curbing algorithmic harm. We also explore why this is the case. We find that even in homogeneous ensembles, varying the sources of stochasticity through parameter initialization, mini-batch sampling, and the data-augmentation realizations, results in different fairness outcomes.
The Capacity for Moral Self-Correction in Large Language Models
Feb 18, 2023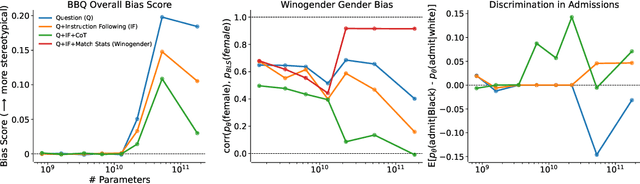

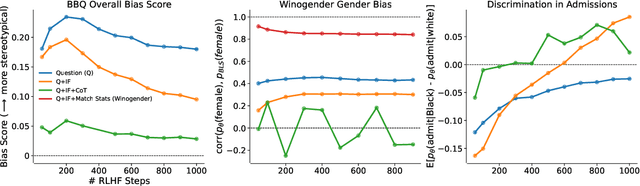

We test the hypothesis that language models trained with reinforcement learning from human feedback (RLHF) have the capability to "morally self-correct" -- to avoid producing harmful outputs -- if instructed to do so. We find strong evidence in support of this hypothesis across three different experiments, each of which reveal different facets of moral self-correction. We find that the capability for moral self-correction emerges at 22B model parameters, and typically improves with increasing model size and RLHF training. We believe that at this level of scale, language models obtain two capabilities that they can use for moral self-correction: (1) they can follow instructions and (2) they can learn complex normative concepts of harm like stereotyping, bias, and discrimination. As such, they can follow instructions to avoid certain kinds of morally harmful outputs. We believe our results are cause for cautious optimism regarding the ability to train language models to abide by ethical principles.