 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Scarcity to Efficiency: Investigating the Effects of Data Augmentation on African Machine Translation
Sep 09, 2025The linguistic diversity across the African continent presents different challenges and opportunities for machine translation. This study explores the effects of data augmentation techniques in improving translation systems in low-resource African languages. We focus on two data augmentation techniques: sentence concatenation with back translation and switch-out, applying them across six African languages. Our experiments show significant improvements in machine translation performance, with a minimum increase of 25\% in BLEU score across all six languages.We provide a comprehensive analysis and highlight the potential of these techniques to improve machine translation systems for low-resource languages, contributing to the development of more robust translation systems for under-resourced languages.
Revisiting Cascaded Ensembles for Efficient Inference
Jul 02, 2024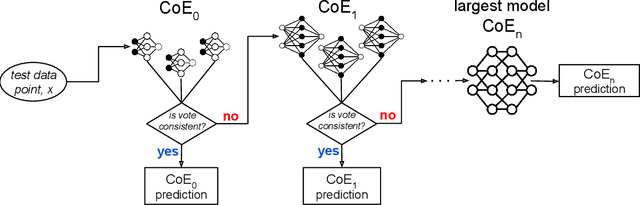

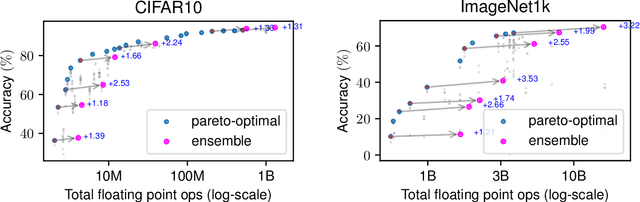

A common approach to make machine learning inference more efficient is to use example-specific adaptive schemes, which route or select models for each example at inference time. In this work we study a simple scheme for adaptive inference. We build a cascade of ensembles (CoE), beginning with resource-efficient models and growing to larger, more expressive models, where ensemble agreement serves as a data-dependent routing criterion. This scheme is easy to incorporate into existing inference pipelines, requires no additional training, and can be used to place models across multiple resource tiers--for instance, serving efficient models at the edge and invoking larger models in the cloud only when necessary. In cases where parallel inference is feasible, we show that CoE can improve accuracy relative to the single best model while reducing the average cost of inference by up to 7x, and provides Pareto-dominate solutions in accuracy and efficiency relative to existing adaptive inference baselines. These savings translate to an over 3x-reduction in total monetary cost when performing inference using a heterogeneous cluster of GPUs. Finally, for edge inference scenarios where portions of the cascade reside at the edge vs. in the cloud, CoE can provide a 14x reduction in communication cost and inference latency without sacrificing accuracy.
What Happens When Small Is Made Smaller? Exploring the Impact of Compression on Small Data Pretrained Language Models
Apr 06, 2024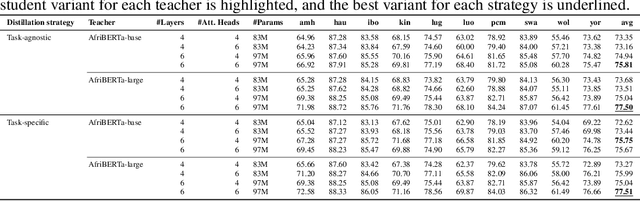
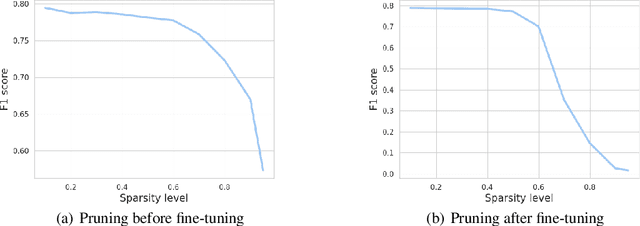
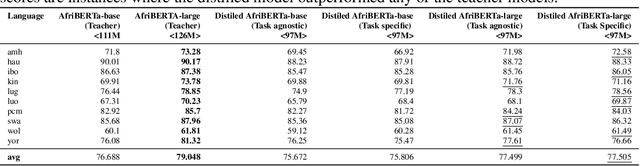
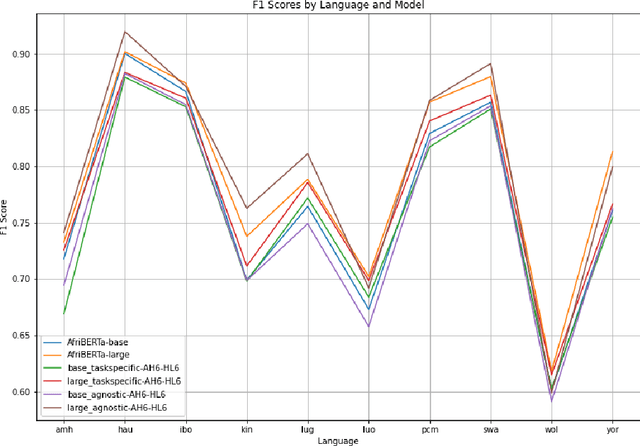
Compression techniques have been crucial in advancing machine learning by enabling efficient training and deployment of large-scale language models. However, these techniques have received limited attention in the context of low-resource language models, which are trained on even smaller amounts of data and under computational constraints, a scenario known as the "low-resource double-bind." This paper investigates the effectiveness of pruning, knowledge distillation, and quantization on an exclusively low-resourced, small-data language model, AfriBERTa. Through a battery of experiments, we assess the effects of compression on performance across several metrics beyond accuracy. Our study provides evidence that compression techniques significantly improve the efficiency and effectiveness of small-data language models, confirming that the prevailing beliefs regarding the effects of compression on large, heavily parameterized models hold true for less-parameterized, small-data models.
Everybody Prune Now: Structured Pruning of LLMs with only Forward Passes
Feb 09, 2024



Given the generational gap in available hardware between lay practitioners and the most endowed institutions, LLMs are becoming increasingly inaccessible as they grow in size. Whilst many approaches have been proposed to compress LLMs to make their resource consumption manageable, these methods themselves tend to be resource intensive, putting them out of the reach of the very user groups they target. In this work, we explore the problem of structured pruning of LLMs using only forward passes. We seek to empower practitioners to prune models so large that their available hardware has just enough memory to run inference. We develop Bonsai, a gradient-free, perturbative pruning method capable of delivering small, fast, and accurate pruned models. We observe that Bonsai outputs pruned models that (i) outperform those generated by more expensive gradient-based structured pruning methods, and (ii) are twice as fast (with comparable accuracy) as those generated by semi-structured pruning methods requiring comparable resources as Bonsai. We also leverage Bonsai to produce a new sub-2B model using a single A6000 that yields state-of-the-art performance on 4/6 tasks on the Huggingface Open LLM leaderboard.
Vision Transformers for Mobile Applications: A Short Survey
May 30, 2023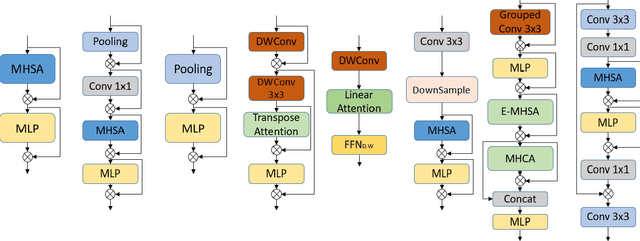
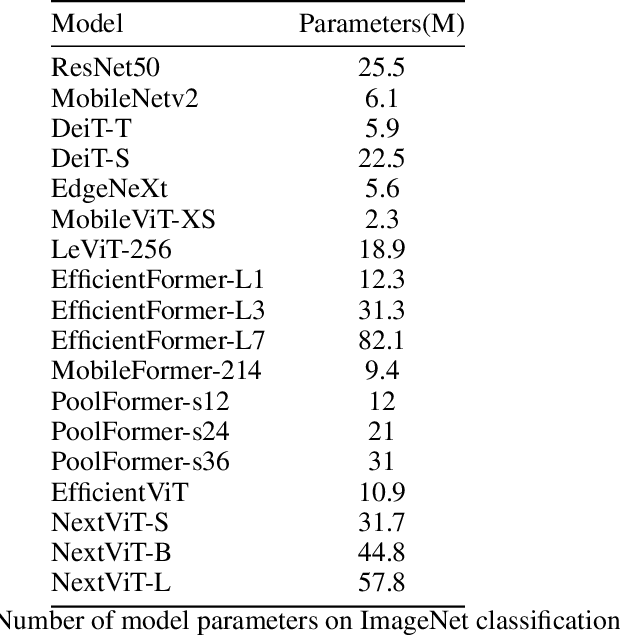
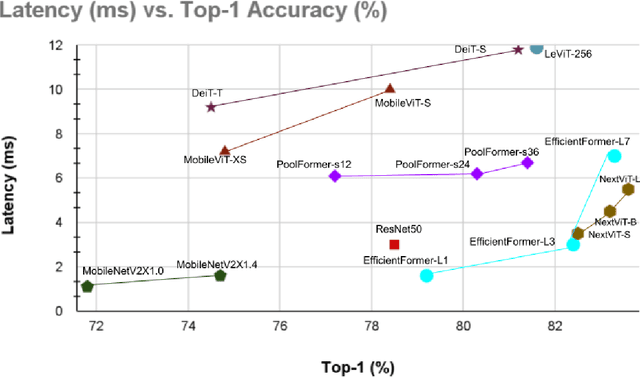
Vision Transformers (ViTs) have demonstrated state-of-the-art performance on many Computer Vision Tasks. Unfortunately, deploying these large-scale ViTs is resource-consuming and impossible for many mobile devices. While most in the community are building for larger and larger ViTs, we ask a completely opposite question: How small can a ViT be within the tradeoffs of accuracy and inference latency that make it suitable for mobile deployment? We look into a few ViTs specifically designed for mobile applications and observe that they modify the transformer's architecture or are built around the combination of CNN and transformer. Recent work has also attempted to create sparse ViT networks and proposed alternatives to the attention module. In this paper, we study these architectures, identify the challenges and analyze what really makes a vision transformer suitable for mobile applications. We aim to serve as a baseline for future research direction and hopefully lay the foundation to choose the exemplary vision transformer architecture for your application running on mobile devices.
Adapting to the Low-Resource Double-Bind: Investigating Low-Compute Methods on Low-Resource African Languages
Mar 29, 2023

Many natural language processing (NLP) tasks make use of massively pre-trained language models, which are computationally expensive. However, access to high computational resources added to the issue of data scarcity of African languages constitutes a real barrier to research experiments on these languages. In this work, we explore the applicability of low-compute approaches such as language adapters in the context of this low-resource double-bind. We intend to answer the following question: do language adapters allow those who are doubly bound by data and compute to practically build useful models? Through fine-tuning experiments on African languages, we evaluate their effectiveness as cost-effective approaches to low-resource African NLP. Using solely free compute resources, our results show that language adapters achieve comparable performances to massive pre-trained language models which are heavy on computational resources. This opens the door to further experimentation and exploration on full-extent of language adapters capacities.
Sign-to-Speech Model for Sign Language Understanding: A Case Study of Nigerian Sign Language
Nov 02, 2021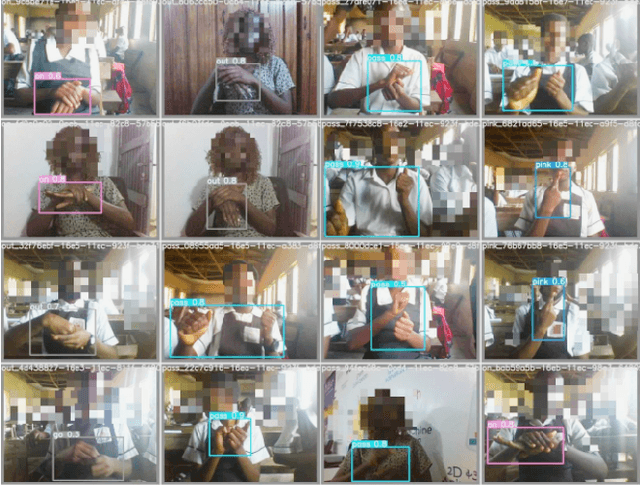
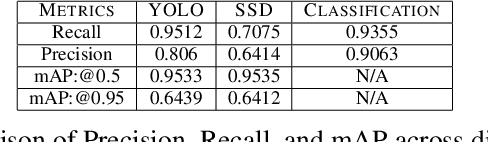
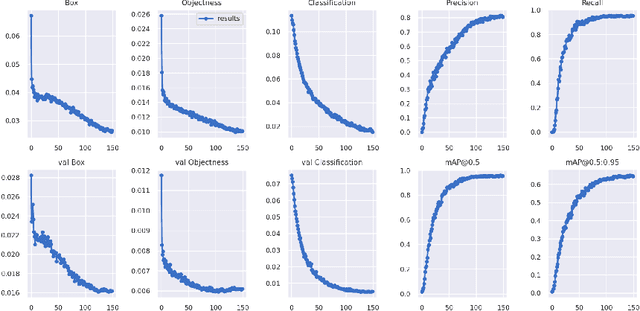
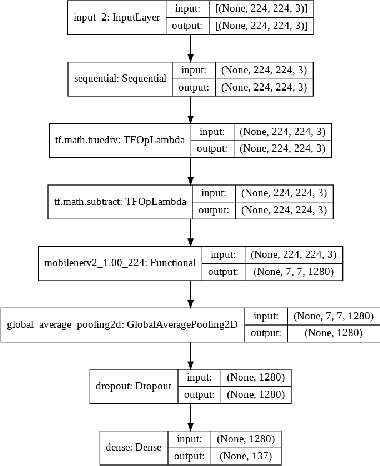
Through this paper, we seek to reduce the communication barrier between the hearing-impaired community and the larger society who are usually not familiar with sign language in the sub-Saharan region of Africa with the largest occurrences of hearing disability cases, while using Nigeria as a case study. The dataset is a pioneer dataset for the Nigerian Sign Language and was created in collaboration with relevant stakeholders. We pre-processed the data in readiness for two different object detection models and a classification model and employed diverse evaluation metrics to gauge model performance on sign-language to text conversion tasks. Finally, we convert the predicted sign texts to speech and deploy the best performing model in a lightweight application that works in real-time and achieves impressive results converting sign words/phrases to text and subsequently, into speech.