 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Cascaded Ensembles for Efficient Inference
Paper and Code
Jul 02, 2024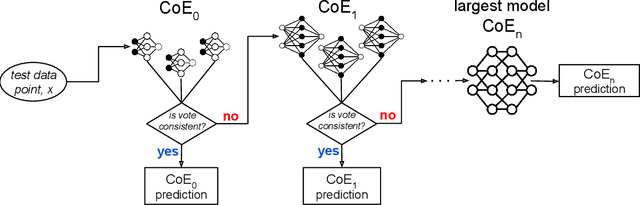

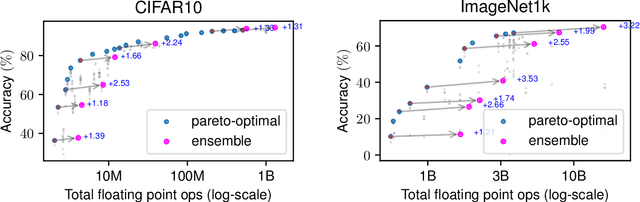

A common approach to make machine learning inference more efficient is to use example-specific adaptive schemes, which route or select models for each example at inference time. In this work we study a simple scheme for adaptive inference. We build a cascade of ensembles (CoE), beginning with resource-efficient models and growing to larger, more expressive models, where ensemble agreement serves as a data-dependent routing criterion. This scheme is easy to incorporate into existing inference pipelines, requires no additional training, and can be used to place models across multiple resource tiers--for instance, serving efficient models at the edge and invoking larger models in the cloud only when necessary. In cases where parallel inference is feasible, we show that CoE can improve accuracy relative to the single best model while reducing the average cost of inference by up to 7x, and provides Pareto-dominate solutions in accuracy and efficiency relative to existing adaptive inference baselines. These savings translate to an over 3x-reduction in total monetary cost when performing inference using a heterogeneous cluster of GPUs. Finally, for edge inference scenarios where portions of the cascade reside at the edge vs. in the cloud, CoE can provide a 14x reduction in communication cost and inference latency without sacrificing accuracy.