 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Cascaded Ensembles for Efficient Inference
Jul 02, 2024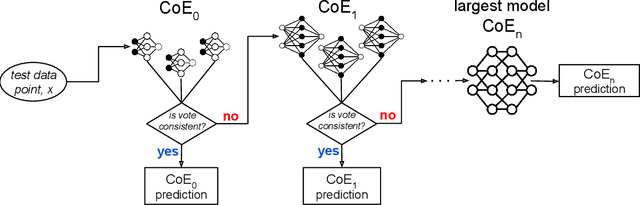

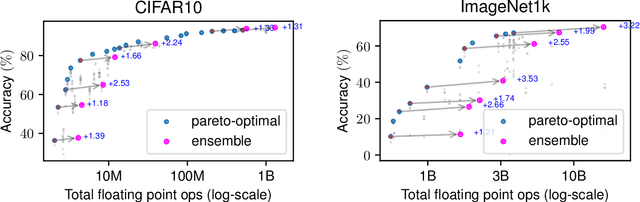

A common approach to make machine learning inference more efficient is to use example-specific adaptive schemes, which route or select models for each example at inference time. In this work we study a simple scheme for adaptive inference. We build a cascade of ensembles (CoE), beginning with resource-efficient models and growing to larger, more expressive models, where ensemble agreement serves as a data-dependent routing criterion. This scheme is easy to incorporate into existing inference pipelines, requires no additional training, and can be used to place models across multiple resource tiers--for instance, serving efficient models at the edge and invoking larger models in the cloud only when necessary. In cases where parallel inference is feasible, we show that CoE can improve accuracy relative to the single best model while reducing the average cost of inference by up to 7x, and provides Pareto-dominate solutions in accuracy and efficiency relative to existing adaptive inference baselines. These savings translate to an over 3x-reduction in total monetary cost when performing inference using a heterogeneous cluster of GPUs. Finally, for edge inference scenarios where portions of the cascade reside at the edge vs. in the cloud, CoE can provide a 14x reduction in communication cost and inference latency without sacrificing accuracy.
Bitrate-Constrained DRO: Beyond Worst Case Robustness To Unknown Group Shifts
Feb 06, 2023



Training machine learning models robust to distribution shifts is critical for real-world applications. Some robust training algorithms (e.g., Group DRO) specialize to group shifts and require group information on all training points. Other methods (e.g., CVaR DRO) that do not need group annotations can be overly conservative, since they naively upweight high loss points which may form a contrived set that does not correspond to any meaningful group in the real world (e.g., when the high loss points are randomly mislabeled training points). In this work, we address limitations in prior approaches by assuming a more nuanced form of group shift: conditioned on the label, we assume that the true group function (indicator over group) is simple. For example, we may expect that group shifts occur along low bitrate features (e.g., image background, lighting). Thus, we aim to learn a model that maintains high accuracy on simple group functions realized by these low bitrate features, that need not spend valuable model capacity achieving high accuracy on contrived groups of examples. Based on this, we consider the two-player game formulation of DRO where the adversary's capacity is bitrate-constrained. Our resulting practical algorithm, Bitrate-Constrained DRO (BR-DRO), does not require group information on training samples yet matches the performance of Group DRO on datasets that have training group annotations and that of CVaR DRO on long-tailed distributions. Our theoretical analysis reveals that in some settings BR-DRO objective can provably yield statistically efficient and less conservative solutions than unconstrained CVaR DRO.