 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Finetuner's Fallacy: When to Pretrain with Your Finetuning Data
Mar 17, 2026Real-world model deployments demand strong performance on narrow domains where data is often scarce. Typically, practitioners finetune models to specialize them, but this risks overfitting to the domain and forgetting general knowledge. We study a simple strategy, specialized pretraining (SPT), where a small domain dataset, typically reserved for finetuning, is repeated starting from pretraining as a fraction of the total tokens. Across three specialized domains (ChemPile, MusicPile, and ProofPile), SPT improves domain performance and preserves general capabilities after finetuning compared to standard pretraining. In our experiments, SPT reduces the pretraining tokens needed to reach a given domain performance by up to 1.75x. These gains grow when the target domain is underrepresented in the pretraining corpus: on domains far from web text, a 1B SPT model outperforms a 3B standard pretrained model. Beyond these empirical gains, we derive overfitting scaling laws to guide practitioners in selecting the optimal domain-data repetition for a given pretraining compute budget. Our observations reveal the finetuner's fallacy: while finetuning may appear to be the cheapest path to domain adaptation, introducing specialized domain data during pretraining stretches its utility. SPT yields better specialized domain performance (via reduced overfitting across repeated exposures) and better general domain performance (via reduced forgetting during finetuning), ultimately achieving stronger results with fewer parameters and less total compute when amortized over inference. To get the most out of domain data, incorporate it as early in training as possible.
One-step Language Modeling via Continuous Denoising
Feb 18, 2026Language models based on discrete diffusion have attracted widespread interest for their potential to provide faster generation than autoregressive models. In practice, however, they exhibit a sharp degradation of sample quality in the few-step regime, failing to realize this promise. Here we show that language models leveraging flow-based continuous denoising can outperform discrete diffusion in both quality and speed. By revisiting the fundamentals of flows over discrete modalities, we build a flow-based language model (FLM) that performs Euclidean denoising over one-hot token encodings. We show that the model can be trained by predicting the clean data via a cross entropy objective, where we introduce a simple time reparameterization that greatly improves training stability and generation quality. By distilling FLM into its associated flow map, we obtain a distilled flow map language model (FMLM) capable of few-step generation. On the LM1B and OWT language datasets, FLM attains generation quality matching state-of-the-art discrete diffusion models. With FMLM, our approach outperforms recent few-step language models across the board, with one-step generation exceeding their 8-step quality. Our work calls into question the widely held hypothesis that discrete diffusion processes are necessary for generative modeling over discrete modalities, and paves the way toward accelerated flow-based language modeling at scale. Code is available at https://github.com/david3684/flm.
S2D: Selective Spectral Decay for Quantization-Friendly Conditioning of Neural Activations
Feb 16, 2026Activation outliers in large-scale transformer models pose a fundamental challenge to model quantization, creating excessively large ranges that cause severe accuracy drops during quantization. We empirically observe that outlier severity intensifies with pre-training scale (e.g., progressing from CLIP to the more extensively trained SigLIP and SigLIP2). Through theoretical analysis as well as empirical correlation studies, we establish the direct link between these activation outliers and dominant singular values of the weights. Building on this insight, we propose Selective Spectral Decay ($S^2D$), a geometrically-principled conditioning method that surgically regularizes only the weight components corresponding to the largest singular values during fine-tuning. Through extensive experiments, we demonstrate that $S^2D$ significantly reduces activation outliers and produces well-conditioned representations that are inherently quantization-friendly. Models trained with $S^2D$ achieve up to 7% improved PTQ accuracy on ImageNet under W4A4 quantization and 4% gains when combined with QAT. These improvements also generalize across downstream tasks and vision-language models, enabling the scaling of increasingly large and rigorously trained models without sacrificing deployment efficiency.
Watch the Weights: Unsupervised monitoring and control of fine-tuned LLMs
Jul 31, 2025The releases of powerful open-weight large language models (LLMs) are often not accompanied by access to their full training data. Existing interpretability methods, particularly those based on activations, often require or assume distributionally similar data. This is a significant limitation when detecting and defending against novel potential threats like backdoors, which are by definition out-of-distribution. In this work, we introduce a new method for understanding, monitoring and controlling fine-tuned LLMs that interprets weights, rather than activations, thereby side stepping the need for data that is distributionally similar to the unknown training data. We demonstrate that the top singular vectors of the weight difference between a fine-tuned model and its base model correspond to newly acquired behaviors. By monitoring the cosine similarity of activations along these directions, we can detect salient behaviors introduced during fine-tuning with high precision. For backdoored models that bypasses safety mechanisms when a secret trigger is present, our method stops up to 100% of attacks with a false positive rate below 1.2%. For models that have undergone unlearning, we detect inference on erased topics with accuracy up to 95.42% and can even steer the model to recover "unlearned" information. Besides monitoring, our method also shows potential for pre-deployment model auditing: by analyzing commercial instruction-tuned models (OLMo, Llama, Qwen), we are able to uncover model-specific fine-tuning focus including marketing strategies and Midjourney prompt generation. Our implementation can be found at https://github.com/fjzzq2002/WeightWatch.
Reasoning as an Adaptive Defense for Safety
Jul 01, 2025



Reasoning methods that adaptively allocate test-time compute have advanced LLM performance on easy to verify domains such as math and code. In this work, we study how to utilize this approach to train models that exhibit a degree of robustness to safety vulnerabilities, and show that doing so can provide benefits. We build a recipe called $\textit{TARS}$ (Training Adaptive Reasoners for Safety), a reinforcement learning (RL) approach that trains models to reason about safety using chain-of-thought traces and a reward signal that balances safety with task completion. To build TARS, we identify three critical design choices: (1) a "lightweight" warmstart SFT stage, (2) a mix of harmful, harmless, and ambiguous prompts to prevent shortcut behaviors such as too many refusals, and (3) a reward function to prevent degeneration of reasoning capabilities during training. Models trained with TARS exhibit adaptive behaviors by spending more compute on ambiguous queries, leading to better safety-refusal trade-offs. They also internally learn to better distinguish between safe and unsafe prompts and attain greater robustness to both white-box (e.g., GCG) and black-box attacks (e.g., PAIR). Overall, our work provides an effective, open recipe for training LLMs against jailbreaks and harmful requests by reasoning per prompt.
Roll the dice & look before you leap: Going beyond the creative limits of next-token prediction
Apr 21, 2025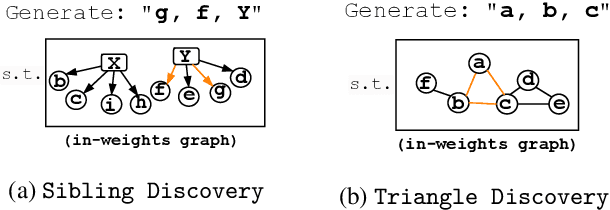
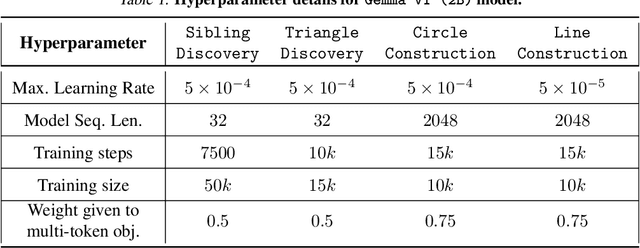
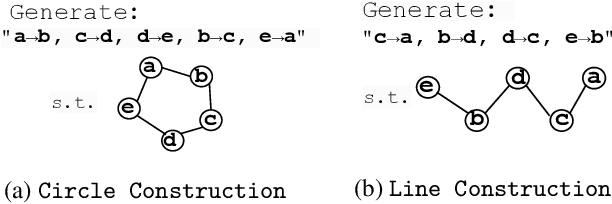
We design a suite of minimal algorithmic tasks that are a loose abstraction of open-ended real-world tasks. This allows us to cleanly and controllably quantify the creative limits of the present-day language model. Much like real-world tasks that require a creative, far-sighted leap of thought, our tasks require an implicit, open-ended stochastic planning step that either (a) discovers new connections in an abstract knowledge graph (like in wordplay, drawing analogies, or research) or (b) constructs new patterns (like in designing math problems or new proteins). In these tasks, we empirically and conceptually argue how next-token learning is myopic and memorizes excessively; comparatively, multi-token approaches, namely teacherless training and diffusion models, excel in producing diverse and original output. Secondly, in our tasks, we find that to elicit randomness from the Transformer without hurting coherence, it is better to inject noise right at the input layer (via a method we dub hash-conditioning) rather than defer to temperature sampling from the output layer. Thus, our work offers a principled, minimal test-bed for analyzing open-ended creative skills, and offers new arguments for going beyond next-token learning and softmax-based sampling. We make part of the code available under https://github.com/chenwu98/algorithmic-creativity
Weight Ensembling Improves Reasoning in Language Models
Apr 15, 2025We investigate a failure mode that arises during the training of reasoning models, where the diversity of generations begins to collapse, leading to suboptimal test-time scaling. Notably, the Pass@1 rate reliably improves during supervised finetuning (SFT), but Pass@k rapidly deteriorates. Surprisingly, a simple intervention of interpolating the weights of the latest SFT checkpoint with an early checkpoint, otherwise known as WiSE-FT, almost completely recovers Pass@k while also improving Pass@1. The WiSE-FT variant achieves better test-time scaling (Best@k, majority vote) and achieves superior results with less data when tuned further by reinforcement learning. Finally, we find that WiSE-FT provides complementary performance gains that cannot be achieved only through diversity-inducing decoding strategies, like temperature scaling. We formalize a bias-variance tradeoff of Pass@k with respect to the expectation and variance of Pass@1 over the test distribution. We find that WiSE-FT can reduce bias and variance simultaneously, while temperature scaling inherently trades-off between bias and variance.
Exact Unlearning of Finetuning Data via Model Merging at Scale
Apr 06, 2025Approximate unlearning has gained popularity as an approach to efficiently update an LLM so that it behaves (roughly) as if it was not trained on a subset of data to begin with. However, existing methods are brittle in practice and can easily be attacked to reveal supposedly unlearned information. To alleviate issues with approximate unlearning, we instead propose SIFT-Masks (SIgn-Fixed Tuning-Masks), an exact unlearning method based on model merging. SIFT-Masks addresses two key limitations of standard model merging: (1) merging a large number of tasks can severely harm utility; and (2) methods that boost utility by sharing extra information across tasks make exact unlearning prohibitively expensive. SIFT-Masks solves these issues by (1) applying local masks to recover task-specific performance; and (2) constraining finetuning to align with a global sign vector as a lightweight approach to determine masks independently before merging. Across four settings where we merge up to 500 models, SIFT-Masks improves accuracy by 5-80% over naive merging and uses up to 250x less compute for exact unlearning compared to other merging baselines.
Overtrained Language Models Are Harder to Fine-Tune
Mar 24, 2025



Large language models are pre-trained on ever-growing token budgets under the assumption that better pre-training performance translates to improved downstream models. In this work, we challenge this assumption and show that extended pre-training can make models harder to fine-tune, leading to degraded final performance. We term this phenomenon catastrophic overtraining. For example, the instruction-tuned OLMo-1B model pre-trained on 3T tokens leads to over 2% worse performance on multiple standard LLM benchmarks than its 2.3T token counterpart. Through controlled experiments and theoretical analysis, we show that catastrophic overtraining arises from a systematic increase in the broad sensitivity of pre-trained parameters to modifications, including but not limited to fine-tuning. Our findings call for a critical reassessment of pre-training design that considers the downstream adaptability of the model.
Not-Just-Scaling Laws: Towards a Better Understanding of the Downstream Impact of Language Model Design Decisions
Mar 05, 2025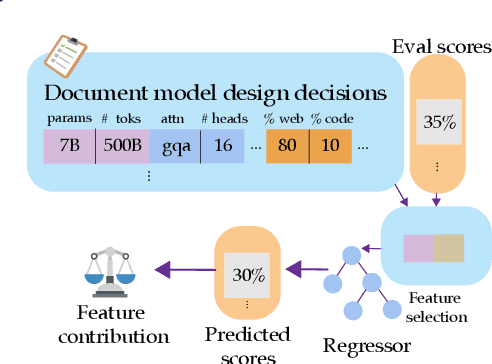
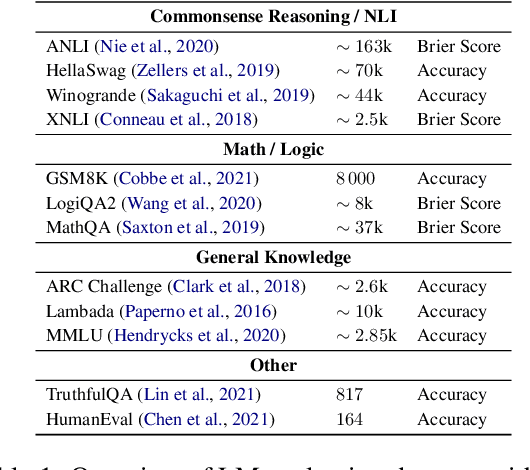
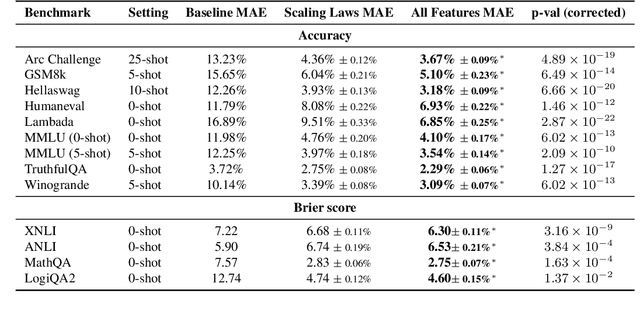
Improvements in language model capabilities are often attributed to increasing model size or training data, but in some cases smaller models trained on curated data or with different architectural decisions can outperform larger ones trained on more tokens. What accounts for this? To quantify the impact of these design choices, we meta-analyze 92 open-source pretrained models across a wide array of scales, including state-of-the-art open-weights models as well as less performant models and those with less conventional design decisions. We find that by incorporating features besides model size and number of training tokens, we can achieve a relative 3-28% increase in ability to predict downstream performance compared with using scale alone. Analysis of model design decisions reveal insights into data composition, such as the trade-off between language and code tasks at 15-25\% code, as well as the better performance of some architectural decisions such as choosing rotary over learned embeddings. Broadly, our framework lays a foundation for more systematic investigation of how model development choices shape final capabilities.