 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGained in Translation: Privileged Pairwise Judges Enhance Multilingual Reasoning
Jan 26, 2026When asked a question in a language less seen in its training data, current reasoning large language models (RLMs) often exhibit dramatically lower performance than when asked the same question in English. In response, we introduce \texttt{SP3F} (Self-Play with Privileged Pairwise Feedback), a two-stage framework for enhancing multilingual reasoning without \textit{any} data in the target language(s). First, we supervise fine-tune (SFT) on translated versions of English question-answer pairs to raise base model correctness. Second, we perform RL with feedback from a pairwise judge in a self-play fashion, with the judge receiving the English reference response as \textit{privileged information}. Thus, even when none of the model's responses are completely correct, the privileged pairwise judge can still tell which response is better. End-to-end, \texttt{SP3F} greatly improves base model performance, even outperforming fully post-trained models on multiple math and non-math tasks with less than of the training data across the single-language, multilingual, and generalization to unseen language settings.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
Not-Just-Scaling Laws: Towards a Better Understanding of the Downstream Impact of Language Model Design Decisions
Mar 05, 2025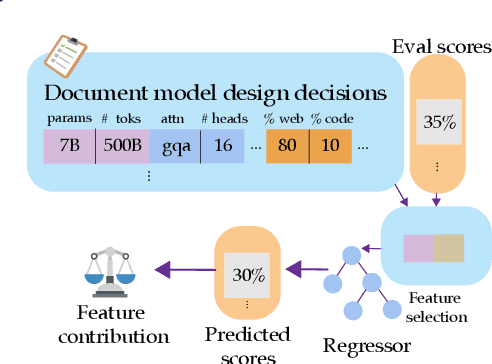
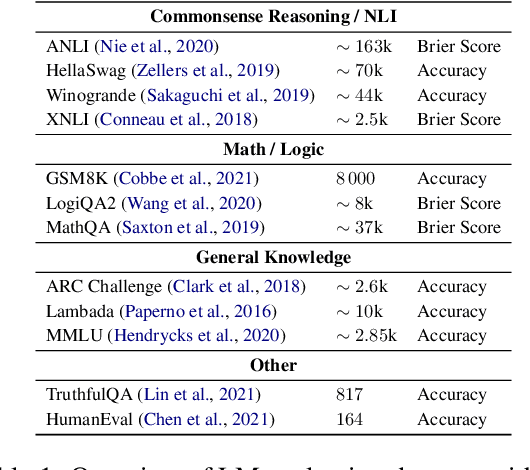
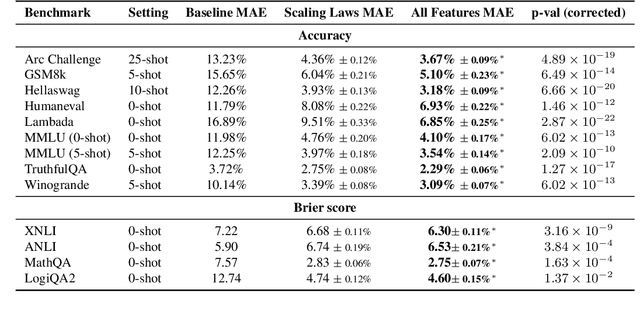
Improvements in language model capabilities are often attributed to increasing model size or training data, but in some cases smaller models trained on curated data or with different architectural decisions can outperform larger ones trained on more tokens. What accounts for this? To quantify the impact of these design choices, we meta-analyze 92 open-source pretrained models across a wide array of scales, including state-of-the-art open-weights models as well as less performant models and those with less conventional design decisions. We find that by incorporating features besides model size and number of training tokens, we can achieve a relative 3-28% increase in ability to predict downstream performance compared with using scale alone. Analysis of model design decisions reveal insights into data composition, such as the trade-off between language and code tasks at 15-25\% code, as well as the better performance of some architectural decisions such as choosing rotary over learned embeddings. Broadly, our framework lays a foundation for more systematic investigation of how model development choices shape final capabilities.
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages
Oct 21, 2024Despite recent advances in multimodal large language models (MLLMs), their development has predominantly focused on English- and western-centric datasets and tasks, leaving most of the world's languages and diverse cultural contexts underrepresented. This paper introduces Pangea, a multilingual multimodal LLM trained on PangeaIns, a diverse 6M instruction dataset spanning 39 languages. PangeaIns features: 1) high-quality English instructions, 2) carefully machine-translated instructions, and 3) culturally relevant multimodal tasks to ensure cross-cultural coverage. To rigorously assess models' capabilities, we introduce PangeaBench, a holistic evaluation suite encompassing 14 datasets covering 47 languages. Results show that Pangea significantly outperforms existing open-source models in multilingual settings and diverse cultural contexts. Ablation studies further reveal the importance of English data proportions, language popularity, and the number of multimodal training samples on overall performance. We fully open-source our data, code, and trained checkpoints, to facilitate the development of inclusive and robust multilingual MLLMs, promoting equity and accessibility across a broader linguistic and cultural spectrum.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024
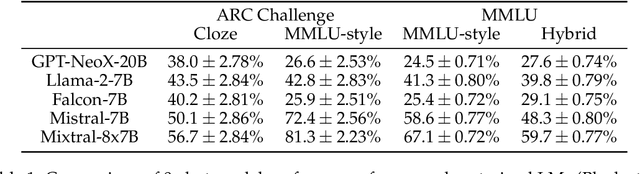
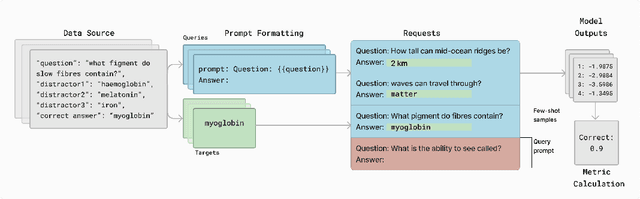

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
Utilizing Weak Supervision To Generate Indonesian Conservation Dataset
Oct 24, 2023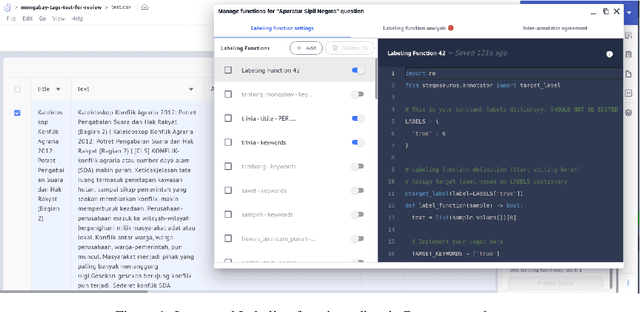

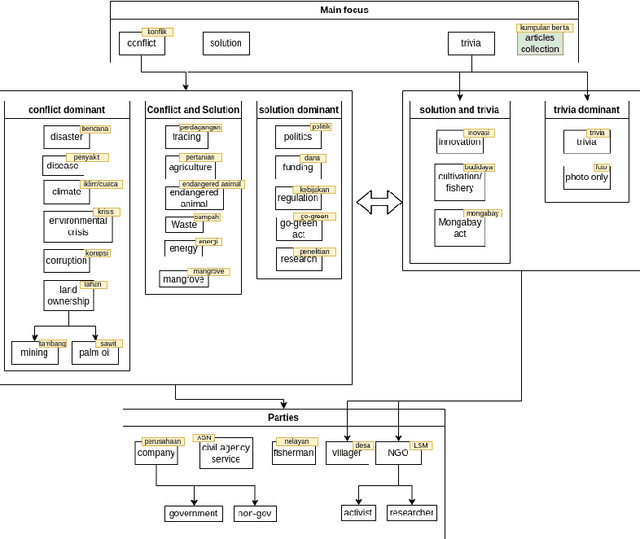

Weak supervision has emerged as a promising approach for rapid and large-scale dataset creation in response to the increasing demand for accelerated NLP development. By leveraging labeling functions, weak supervision allows practitioners to generate datasets quickly by creating learned label models that produce soft-labeled datasets. This paper aims to show how such an approach can be utilized to build an Indonesian NLP dataset from conservation news text. We construct two types of datasets: multi-class classification and sentiment classification. We then provide baseline experiments using various pretrained language models. These baseline results demonstrate test performances of 59.79% accuracy and 55.72% F1-score for sentiment classification, 66.87% F1-score-macro, 71.5% F1-score-micro, and 83.67% ROC-AUC for multi-class classification. Additionally, we release the datasets and labeling functions used in this work for further research and exploration.
Emergent and Predictable Memorization in Large Language Models
Apr 21, 2023Memorization, or the tendency of large language models (LLMs) to output entire sequences from their training data verbatim, is a key concern for safely deploying language models. In particular, it is vital to minimize a model's memorization of sensitive datapoints such as those containing personal identifiable information (PII). The prevalence of such undesirable memorization can pose issues for model trainers, and may even require discarding an otherwise functional model. We therefore seek to predict which sequences will be memorized before a large model's full train-time by extrapolating the memorization behavior of lower-compute trial runs. We measure memorization of the Pythia model suite, and find that intermediate checkpoints are better predictors of a model's memorization behavior than smaller fully-trained models. We additionally provide further novel discoveries on the distribution of memorization scores across models and data.
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Apr 03, 2023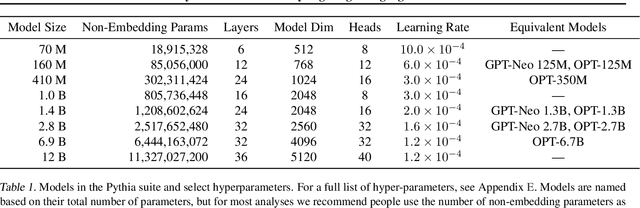

How do large language models (LLMs) develop and evolve over the course of training? How do these patterns change as models scale? To answer these questions, we introduce \textit{Pythia}, a suite of 16 LLMs all trained on public data seen in the exact same order and ranging in size from 70M to 12B parameters. We provide public access to 154 checkpoints for each one of the 16 models, alongside tools to download and reconstruct their exact training dataloaders for further study. We intend \textit{Pythia} to facilitate research in many areas, and we present several case studies including novel results in memorization, term frequency effects on few-shot performance, and reducing gender bias. We demonstrate that this highly controlled setup can be used to yield novel insights toward LLMs and their training dynamics. Trained models, analysis code, training code, and training data can be found at https://github.com/EleutherAI/pythia.
Prompting Multilingual Large Language Models to Generate Code-Mixed Texts: The Case of South East Asian Languages
Mar 30, 2023



While code-mixing is a common linguistic practice in many parts of the world, collecting high-quality and low-cost code-mixed data remains a challenge for natural language processing (NLP) research. The proliferation of Large Language Models (LLMs) in recent times compels one to ask: can these systems be used for data generation? In this article, we explore prompting multilingual LLMs in a zero-shot manner to create code-mixed data for five languages in South East Asia (SEA) -- Indonesian, Malay, Chinese, Tagalog, Vietnamese, as well as the creole language Singlish. We find that ChatGPT shows the most potential, capable of producing code-mixed text 68% of the time when the term "code-mixing" is explicitly defined. Moreover, both ChatGPT's and InstructGPT's (davinci-003) performances in generating Singlish texts are noteworthy, averaging a 96% success rate across a variety of prompts. Their code-mixing proficiency, however, is dampened by word choice errors that lead to semantic inaccuracies. Other multilingual models such as BLOOMZ and Flan-T5-XXL are unable to produce code-mixed texts altogether. By highlighting the limited promises of LLMs in a specific form of low-resource data generation, we call for a measured approach when applying similar techniques to other data-scarce NLP contexts.
BLOOM+1: Adding Language Support to BLOOM for Zero-Shot Prompting
Dec 19, 2022
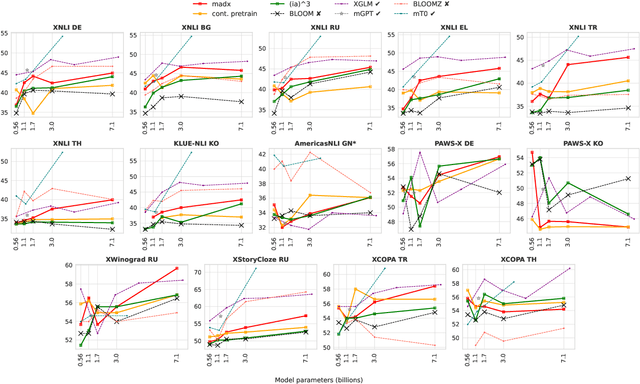


The BLOOM model is a large open-source multilingual language model capable of zero-shot learning, but its pretraining was limited to 46 languages. To improve its zero-shot performance on unseen languages, it is desirable to adapt BLOOM, but previous works have only explored adapting small language models. In this work, we apply existing language adaptation strategies to BLOOM and benchmark its zero-shot prompting performance on eight new languages. We find language adaptation to be effective at improving zero-shot performance in new languages. Surprisingly, adapter-based finetuning is more effective than continued pretraining for large models. In addition, we discover that prompting performance is not significantly affected by language specifics, such as the writing system. It is primarily determined by the size of the language adaptation data. We also add new languages to BLOOMZ, which is a multitask finetuned version of BLOOM capable of following task instructions zero-shot. We find including a new language in the multitask fine-tuning mixture to be the most effective method to teach BLOOMZ a new language. We conclude that with sufficient training data language adaptation can generalize well to diverse languages. Our code is available at \url{https://github.com/bigscience-workshop/multilingual-modeling/}.