 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent and Predictable Memorization in Large Language Models
Apr 21, 2023Memorization, or the tendency of large language models (LLMs) to output entire sequences from their training data verbatim, is a key concern for safely deploying language models. In particular, it is vital to minimize a model's memorization of sensitive datapoints such as those containing personal identifiable information (PII). The prevalence of such undesirable memorization can pose issues for model trainers, and may even require discarding an otherwise functional model. We therefore seek to predict which sequences will be memorized before a large model's full train-time by extrapolating the memorization behavior of lower-compute trial runs. We measure memorization of the Pythia model suite, and find that intermediate checkpoints are better predictors of a model's memorization behavior than smaller fully-trained models. We additionally provide further novel discoveries on the distribution of memorization scores across models and data.
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Apr 03, 2023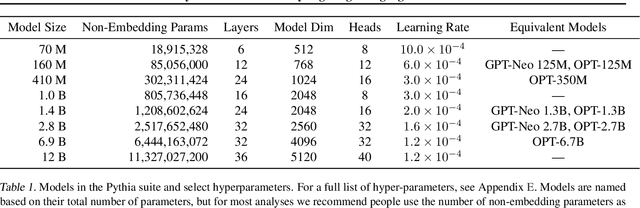
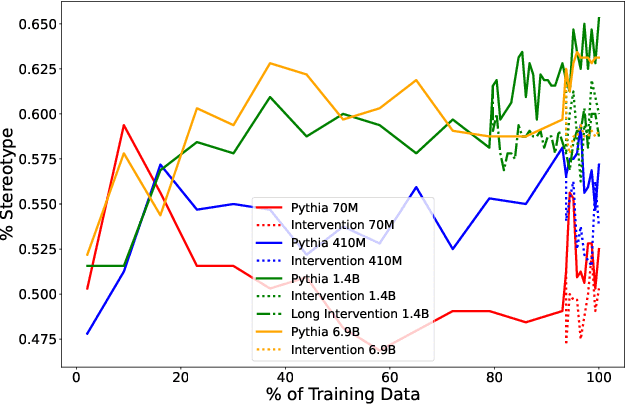

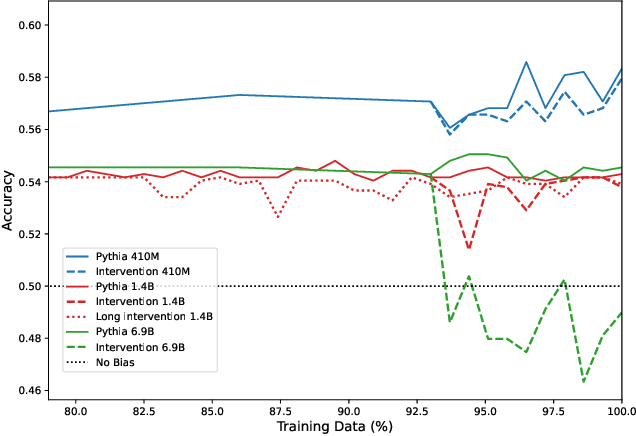
How do large language models (LLMs) develop and evolve over the course of training? How do these patterns change as models scale? To answer these questions, we introduce \textit{Pythia}, a suite of 16 LLMs all trained on public data seen in the exact same order and ranging in size from 70M to 12B parameters. We provide public access to 154 checkpoints for each one of the 16 models, alongside tools to download and reconstruct their exact training dataloaders for further study. We intend \textit{Pythia} to facilitate research in many areas, and we present several case studies including novel results in memorization, term frequency effects on few-shot performance, and reducing gender bias. We demonstrate that this highly controlled setup can be used to yield novel insights toward LLMs and their training dynamics. Trained models, analysis code, training code, and training data can be found at https://github.com/EleutherAI/pythia.
RoentGen: Vision-Language Foundation Model for Chest X-ray Generation
Nov 23, 2022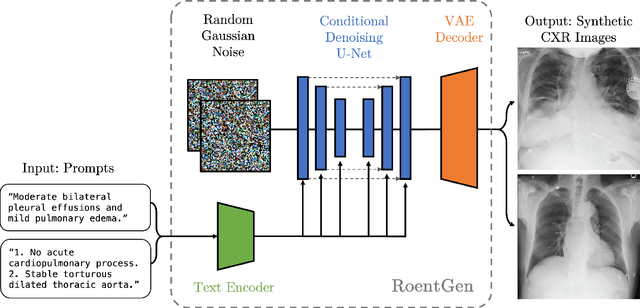



Multimodal models trained on large natural image-text pair datasets have exhibited astounding abilities in generating high-quality images. Medical imaging data is fundamentally different to natural images, and the language used to succinctly capture relevant details in medical data uses a different, narrow but semantically rich, domain-specific vocabulary. Not surprisingly, multi-modal models trained on natural image-text pairs do not tend to generalize well to the medical domain. Developing generative imaging models faithfully representing medical concepts while providing compositional diversity could mitigate the existing paucity of high-quality, annotated medical imaging datasets. In this work, we develop a strategy to overcome the large natural-medical distributional shift by adapting a pre-trained latent diffusion model on a corpus of publicly available chest x-rays (CXR) and their corresponding radiology (text) reports. We investigate the model's ability to generate high-fidelity, diverse synthetic CXR conditioned on text prompts. We assess the model outputs quantitatively using image quality metrics, and evaluate image quality and text-image alignment by human domain experts. We present evidence that the resulting model (RoentGen) is able to create visually convincing, diverse synthetic CXR images, and that the output can be controlled to a new extent by using free-form text prompts including radiology-specific language. Fine-tuning this model on a fixed training set and using it as a data augmentation method, we measure a 5% improvement of a classifier trained jointly on synthetic and real images, and a 3% improvement when trained on a larger but purely synthetic training set. Finally, we observe that this fine-tuning distills in-domain knowledge in the text-encoder and can improve its representation capabilities of certain diseases like pneumothorax by 25%.
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Apr 14, 2022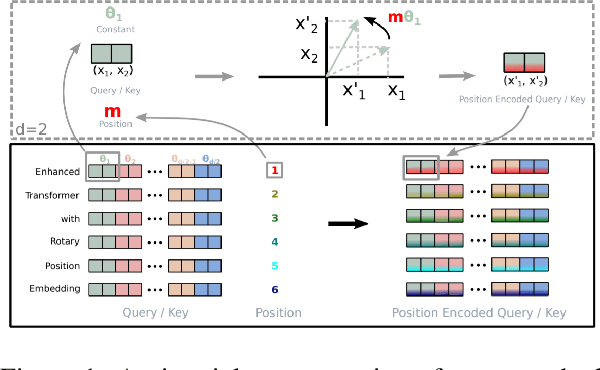
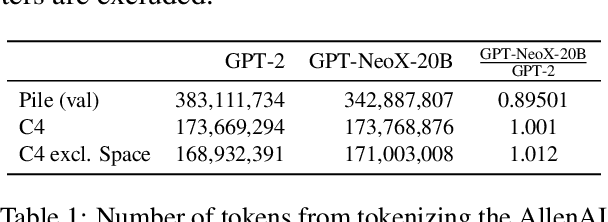
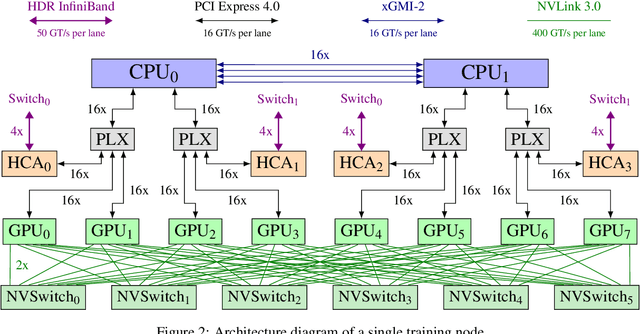

We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe \model{}'s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.