 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Performance of Radiology Report De-identification with Large-Scale Training and Benchmarking Against Cloud Vendor Methods
Nov 06, 2025


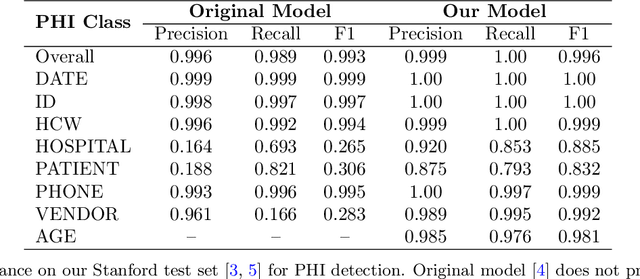
Objective: To enhance automated de-identification of radiology reports by scaling transformer-based models through extensive training datasets and benchmarking performance against commercial cloud vendor systems for protected health information (PHI) detection. Materials and Methods: In this retrospective study, we built upon a state-of-the-art, transformer-based, PHI de-identification pipeline by fine-tuning on two large annotated radiology corpora from Stanford University, encompassing chest X-ray, chest CT, abdomen/pelvis CT, and brain MR reports and introducing an additional PHI category (AGE) into the architecture. Model performance was evaluated on test sets from Stanford and the University of Pennsylvania (Penn) for token-level PHI detection. We further assessed (1) the stability of synthetic PHI generation using a "hide-in-plain-sight" method and (2) performance against commercial systems. Precision, recall, and F1 scores were computed across all PHI categories. Results: Our model achieved overall F1 scores of 0.973 on the Penn dataset and 0.996 on the Stanford dataset, outperforming or maintaining the previous state-of-the-art model performance. Synthetic PHI evaluation showed consistent detectability (overall F1: 0.959 [0.958-0.960]) across 50 independently de-identified Penn datasets. Our model outperformed all vendor systems on synthetic Penn reports (overall F1: 0.960 vs. 0.632-0.754). Discussion: Large-scale, multimodal training improved cross-institutional generalization and robustness. Synthetic PHI generation preserved data utility while ensuring privacy. Conclusion: A transformer-based de-identification model trained on diverse radiology datasets outperforms prior academic and commercial systems in PHI detection and establishes a new benchmark for secure clinical text processing.
BigO(Bench) -- Can LLMs Generate Code with Controlled Time and Space Complexity?
Mar 20, 2025We introduce BigO(Bench), a novel coding benchmark designed to evaluate the capabilities of generative language models in understanding and generating code with specified time and space complexities. This benchmark addresses the gap in current evaluations that often overlook the ability of models to comprehend and produce code constrained by computational complexity. BigO(Bench) includes tooling to infer the algorithmic complexity of any Python function from profiling measurements, including human- or LLM-generated solutions. BigO(Bench) also includes of set of 3,105 coding problems and 1,190,250 solutions from Code Contests annotated with inferred (synthetic) time and space complexity labels from the complexity framework, as well as corresponding runtime and memory footprint values for a large set of input sizes. We present results from evaluating multiple state-of-the-art language models on this benchmark, highlighting their strengths and weaknesses in handling complexity requirements. In particular, token-space reasoning models are unrivaled in code generation but not in complexity understanding, hinting that they may not generalize well to tasks for which no reward was given at training time.
MedVAE: Efficient Automated Interpretation of Medical Images with Large-Scale Generalizable Autoencoders
Feb 20, 2025



Medical images are acquired at high resolutions with large fields of view in order to capture fine-grained features necessary for clinical decision-making. Consequently, training deep learning models on medical images can incur large computational costs. In this work, we address the challenge of downsizing medical images in order to improve downstream computational efficiency while preserving clinically-relevant features. We introduce MedVAE, a family of six large-scale 2D and 3D autoencoders capable of encoding medical images as downsized latent representations and decoding latent representations back to high-resolution images. We train MedVAE autoencoders using a novel two-stage training approach with 1,052,730 medical images. Across diverse tasks obtained from 20 medical image datasets, we demonstrate that (1) utilizing MedVAE latent representations in place of high-resolution images when training downstream models can lead to efficiency benefits (up to 70x improvement in throughput) while simultaneously preserving clinically-relevant features and (2) MedVAE can decode latent representations back to high-resolution images with high fidelity. Our work demonstrates that large-scale, generalizable autoencoders can help address critical efficiency challenges in the medical domain. Our code is available at https://github.com/StanfordMIMI/MedVAE.
CheXpert Plus: Augmenting a Large Chest X-ray Dataset with Text Radiology Reports, Patient Demographics and Additional Image Formats
Jun 03, 2024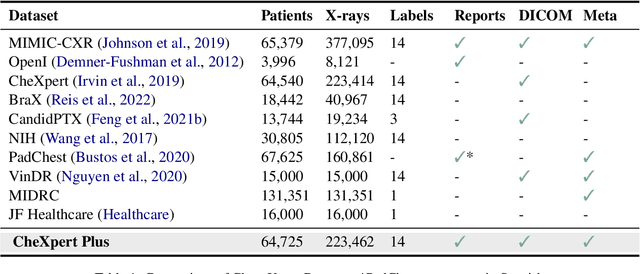

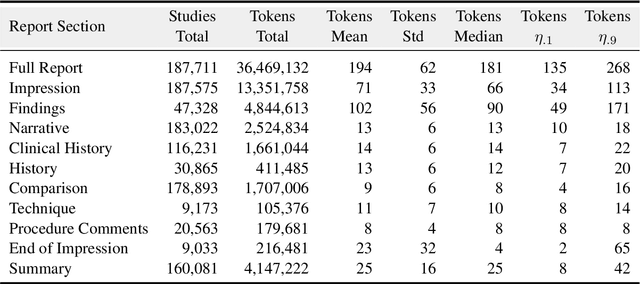
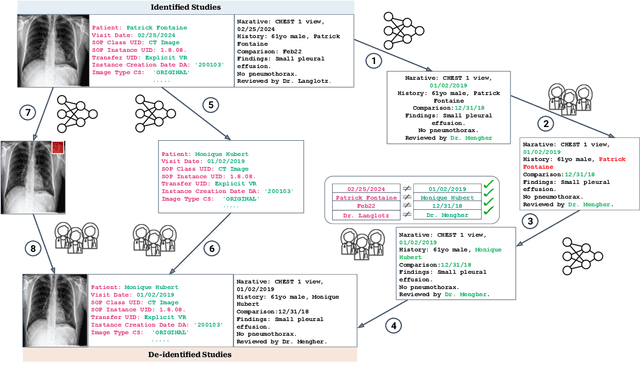
Since the release of the original CheXpert paper five years ago, CheXpert has become one of the most widely used and cited clinical AI datasets. The emergence of vision language models has sparked an increase in demands for sharing reports linked to CheXpert images, along with a growing interest among AI fairness researchers in obtaining demographic data. To address this, CheXpert Plus serves as a new collection of radiology data sources, made publicly available to enhance the scaling, performance, robustness, and fairness of models for all subsequent machine learning tasks in the field of radiology. CheXpert Plus is the largest text dataset publicly released in radiology, with a total of 36 million text tokens, including 13 million impression tokens. To the best of our knowledge, it represents the largest text de-identification effort in radiology, with almost 1 million PHI spans anonymized. It is only the second time that a large-scale English paired dataset has been released in radiology, thereby enabling, for the first time, cross-institution training at scale. All reports are paired with high-quality images in DICOM format, along with numerous image and patient metadata covering various clinical and socio-economic groups, as well as many pathology labels and RadGraph annotations. We hope this dataset will boost research for AI models that can further assist radiologists and help improve medical care. Data is available at the following URL: https://stanfordaimi.azurewebsites.net/datasets/5158c524-d3ab-4e02-96e9-6ee9efc110a1 Models are available at the following URL: https://github.com/Stanford-AIMI/chexpert-plus
RoentGen: Vision-Language Foundation Model for Chest X-ray Generation
Nov 23, 2022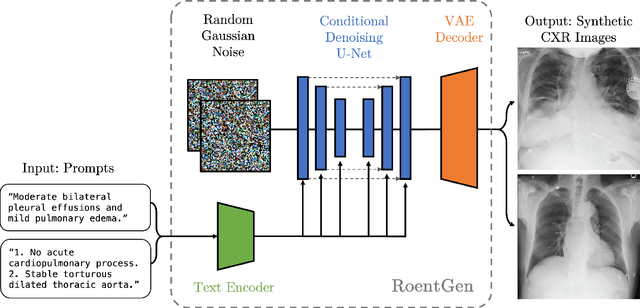



Multimodal models trained on large natural image-text pair datasets have exhibited astounding abilities in generating high-quality images. Medical imaging data is fundamentally different to natural images, and the language used to succinctly capture relevant details in medical data uses a different, narrow but semantically rich, domain-specific vocabulary. Not surprisingly, multi-modal models trained on natural image-text pairs do not tend to generalize well to the medical domain. Developing generative imaging models faithfully representing medical concepts while providing compositional diversity could mitigate the existing paucity of high-quality, annotated medical imaging datasets. In this work, we develop a strategy to overcome the large natural-medical distributional shift by adapting a pre-trained latent diffusion model on a corpus of publicly available chest x-rays (CXR) and their corresponding radiology (text) reports. We investigate the model's ability to generate high-fidelity, diverse synthetic CXR conditioned on text prompts. We assess the model outputs quantitatively using image quality metrics, and evaluate image quality and text-image alignment by human domain experts. We present evidence that the resulting model (RoentGen) is able to create visually convincing, diverse synthetic CXR images, and that the output can be controlled to a new extent by using free-form text prompts including radiology-specific language. Fine-tuning this model on a fixed training set and using it as a data augmentation method, we measure a 5% improvement of a classifier trained jointly on synthetic and real images, and a 3% improvement when trained on a larger but purely synthetic training set. Finally, we observe that this fine-tuning distills in-domain knowledge in the text-encoder and can improve its representation capabilities of certain diseases like pneumothorax by 25%.
Adapting Pretrained Vision-Language Foundational Models to Medical Imaging Domains
Oct 09, 2022

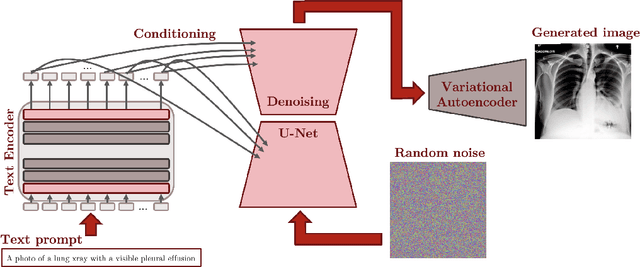
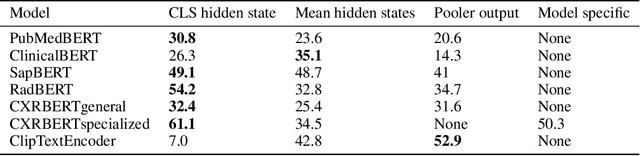
Multi-modal foundation models are typically trained on millions of pairs of natural images and text captions, frequently obtained through web-crawling approaches. Although such models depict excellent generative capabilities, they do not typically generalize well to specific domains such as medical images that have fundamentally shifted distributions compared to natural images. Building generative models for medical images that faithfully depict clinical context may help alleviate the paucity of healthcare datasets. Thus, in this study, we seek to research and expand the representational capabilities of large pretrained foundation models to medical concepts, specifically for leveraging the Stable Diffusion model to generate domain specific images found in medical imaging. We explore the sub-components of the Stable Diffusion pipeline (the variational autoencoder, the U-Net and the text-encoder) to fine-tune the model to generate medical images. We benchmark the efficacy of these efforts using quantitative image quality metrics and qualitative radiologist-driven evaluations that accurately represent the clinical content of conditional text prompts. Our best-performing model improves upon the stable diffusion baseline and can be conditioned to insert a realistic-looking abnormality on a synthetic radiology image, while maintaining a 95% accuracy on a classifier trained to detect the abnormality.
RadGraph: Extracting Clinical Entities and Relations from Radiology Reports
Jun 28, 2021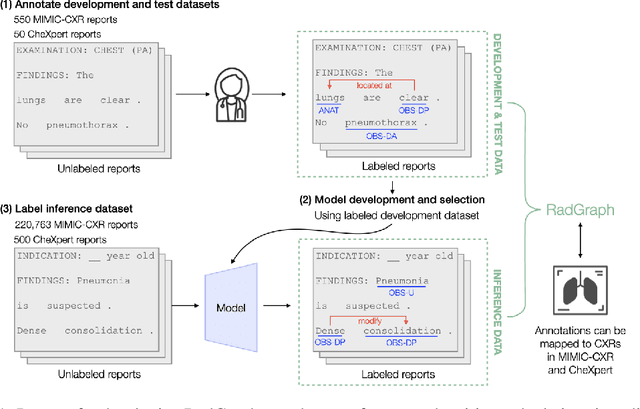
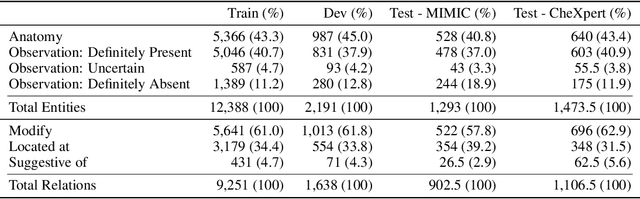
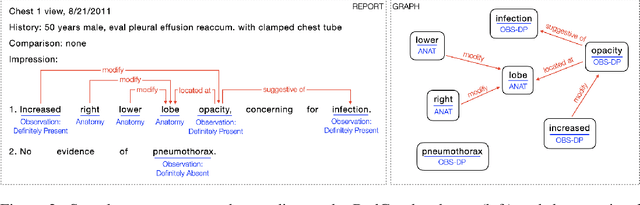
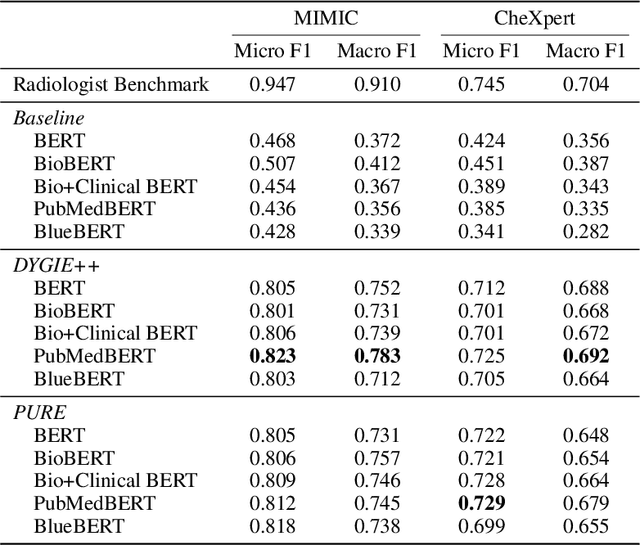
Extracting structured clinical information from free-text radiology reports can enable the use of radiology report information for a variety of critical healthcare applications. In our work, we present RadGraph, a dataset of entities and relations in full-text chest X-ray radiology reports based on a novel information extraction schema we designed to structure radiology reports. We release a development dataset, which contains board-certified radiologist annotations for 500 radiology reports from the MIMIC-CXR dataset (14,579 entities and 10,889 relations), and a test dataset, which contains two independent sets of board-certified radiologist annotations for 100 radiology reports split equally across the MIMIC-CXR and CheXpert datasets. Using these datasets, we train and test a deep learning model, RadGraph Benchmark, that achieves a micro F1 of 0.82 and 0.73 on relation extraction on the MIMIC-CXR and CheXpert test sets respectively. Additionally, we release an inference dataset, which contains annotations automatically generated by RadGraph Benchmark across 220,763 MIMIC-CXR reports (around 6 million entities and 4 million relations) and 500 CheXpert reports (13,783 entities and 9,908 relations) with mappings to associated chest radiographs. Our freely available dataset can facilitate a wide range of research in medical natural language processing, as well as computer vision and multi-modal learning when linked to chest radiographs.