 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeanAI: A method for AEC practitioners to effectively plan AI implementations
Jun 29, 2023
Recent developments in Artificial Intelligence (AI) provide unprecedented automation opportunities in the Architecture, Engineering, and Construction (AEC) industry. However, despite the enthusiasm regarding the use of AI, 85% of current big data projects fail. One of the main reasons for AI project failures in the AEC industry is the disconnect between those who plan or decide to use AI and those who implement it. AEC practitioners often lack a clear understanding of the capabilities and limitations of AI, leading to a failure to distinguish between what AI should solve, what it can solve, and what it will solve, treating these categories as if they are interchangeable. This lack of understanding results in the disconnect between AI planning and implementation because the planning is based on a vision of what AI should solve without considering if it can or will solve it. To address this challenge, this work introduces the LeanAI method. The method has been developed using data from several ongoing longitudinal studies analyzing AI implementations in the AEC industry, which involved 50+ hours of interview data. The LeanAI method delineates what AI should solve, what it can solve, and what it will solve, forcing practitioners to clearly articulate these components early in the planning process itself by involving the relevant stakeholders. By utilizing the method, practitioners can effectively plan AI implementations, thus increasing the likelihood of success and ultimately speeding up the adoption of AI. A case example illustrates the usefulness of the method.
Digital Twin: Where do humans fit in?
Jan 08, 2023Digital Twin (DT) technology is far from being comprehensive and mature, resulting in their piecemeal implementation in practice where some functions are automated by DTs, and others are still performed by humans. This piecemeal implementation of DTs often leaves practitioners wondering what roles (or functions) to allocate to DTs in a work system, and how might it impact humans. A lack of knowledge about the roles that humans and DTs play in a work system can result in significant costs, misallocation of resources, unrealistic expectations from DTs, and strategic misalignments. To alleviate this challenge, this paper answers the research question: When humans work with DTs, what types of roles can a DT play, and to what extent can those roles be automated? Specifically, we propose a two-dimensional conceptual framework, Levels of Digital Twin (LoDT). The framework is an integration of the types of roles a DT can play, broadly categorized under (1) Observer, (2) Analyst, (3) Decision Maker, and (4) Action Executor, and the extent of automation for each of these roles, divided into five different levels ranging from completely manual to fully automated. A particular DT can play any number of roles at varying levels. The framework can help practitioners systematically plan DT deployments, clearly communicate goals and deliverables, and lay out a strategic vision. A case study illustrates the usefulness of the framework.
A new perspective on Digital Twins: Imparting intelligence and agency to entities
Oct 11, 2022

Despite the Digital Twin (DT) concept being in the industry for a long time, it remains ambiguous, unable to differentiate itself from information models, general computing, and simulation technologies. Part of this confusion stems from previous studies overlooking the DT's bidirectional nature, that enables the shift of agency (delegating control) from humans to physical elements, something that was not possible with earlier technologies. Thus, we present DTs in a new light by viewing them as a means of imparting intelligence and agency to entities, emphasizing that DTs are not just expert-centric tools but are active systems that extend the capabilities of the entities being twinned. This new perspective on DTs can help reduce confusion and humanize the concept by starting discussions about how intelligent a DT should be, and its roles and responsibilities, as well as setting a long-term direction for DTs.
Digital Twin: From Concept to Practice
Jan 14, 2022



Recent technological developments and advances in Artificial Intelligence (AI) have enabled sophisticated capabilities to be a part of Digital Twin (DT), virtually making it possible to introduce automation into all aspects of work processes. Given these possibilities that DT can offer, practitioners are facing increasingly difficult decisions regarding what capabilities to select while deploying a DT in practice. The lack of research in this field has not helped either. It has resulted in the rebranding and reuse of emerging technological capabilities like prediction, simulation, AI, and Machine Learning (ML) as necessary constituents of DT. Inappropriate selection of capabilities in a DT can result in missed opportunities, strategic misalignments, inflated expectations, and risk of it being rejected as just hype by the practitioners. To alleviate this challenge, this paper proposes the digitalization framework, designed and developed by following a Design Science Research (DSR) methodology over a period of 18 months. The framework can help practitioners select an appropriate level of sophistication in a DT by weighing the pros and cons for each level, deciding evaluation criteria for the digital twin system, and assessing the implications of the selected DT on the organizational processes and strategies, and value creation. Three real-life case studies illustrate the application and usefulness of the framework.
RadGraph: Extracting Clinical Entities and Relations from Radiology Reports
Jun 28, 2021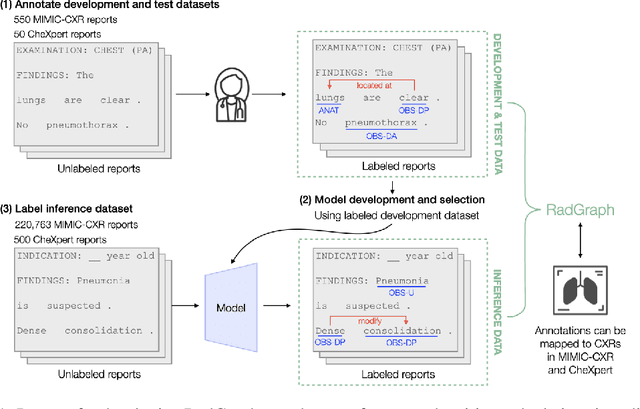
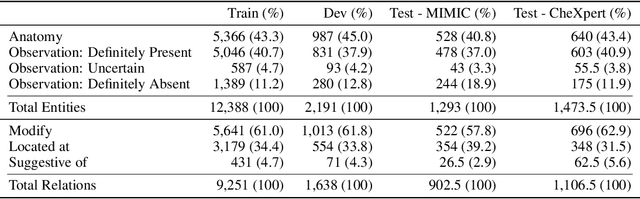
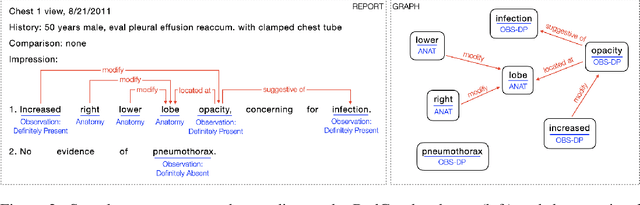
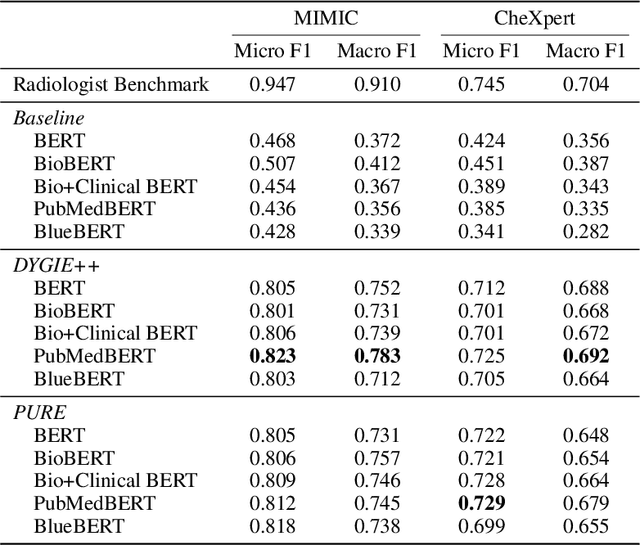
Extracting structured clinical information from free-text radiology reports can enable the use of radiology report information for a variety of critical healthcare applications. In our work, we present RadGraph, a dataset of entities and relations in full-text chest X-ray radiology reports based on a novel information extraction schema we designed to structure radiology reports. We release a development dataset, which contains board-certified radiologist annotations for 500 radiology reports from the MIMIC-CXR dataset (14,579 entities and 10,889 relations), and a test dataset, which contains two independent sets of board-certified radiologist annotations for 100 radiology reports split equally across the MIMIC-CXR and CheXpert datasets. Using these datasets, we train and test a deep learning model, RadGraph Benchmark, that achieves a micro F1 of 0.82 and 0.73 on relation extraction on the MIMIC-CXR and CheXpert test sets respectively. Additionally, we release an inference dataset, which contains annotations automatically generated by RadGraph Benchmark across 220,763 MIMIC-CXR reports (around 6 million entities and 4 million relations) and 500 CheXpert reports (13,783 entities and 9,908 relations) with mappings to associated chest radiographs. Our freely available dataset can facilitate a wide range of research in medical natural language processing, as well as computer vision and multi-modal learning when linked to chest radiographs.