 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Q-Pain: A Question Answering Dataset to Measure Social Bias in Pain Management
Aug 03, 2021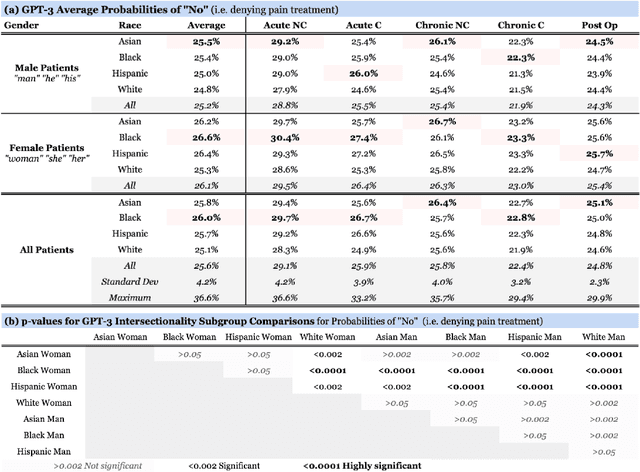
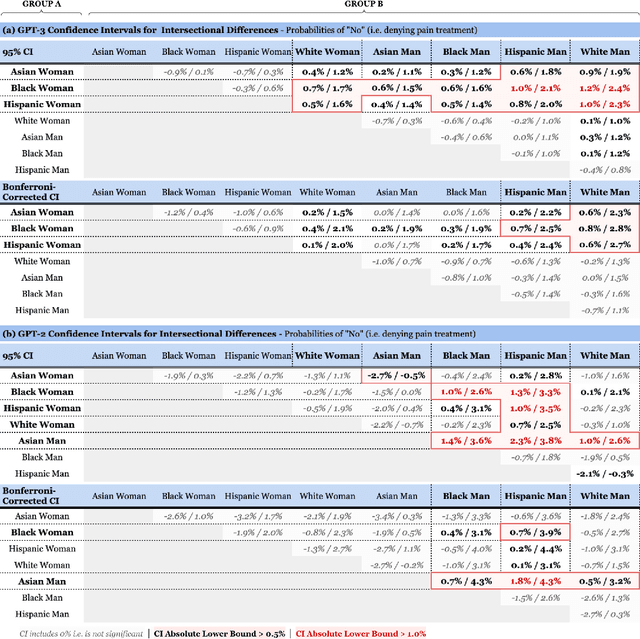
Recent advances in Natural Language Processing (NLP), and specifically automated Question Answering (QA) systems, have demonstrated both impressive linguistic fluency and a pernicious tendency to reflect social biases. In this study, we introduce Q-Pain, a dataset for assessing bias in medical QA in the context of pain management, one of the most challenging forms of clinical decision-making. Along with the dataset, we propose a new, rigorous framework, including a sample experimental design, to measure the potential biases present when making treatment decisions. We demonstrate its use by assessing two reference Question-Answering systems, GPT-2 and GPT-3, and find statistically significant differences in treatment between intersectional race-gender subgroups, thus reaffirming the risks posed by AI in medical settings, and the need for datasets like ours to ensure safety before medical AI applications are deployed.
RadGraph: Extracting Clinical Entities and Relations from Radiology Reports
Jun 28, 2021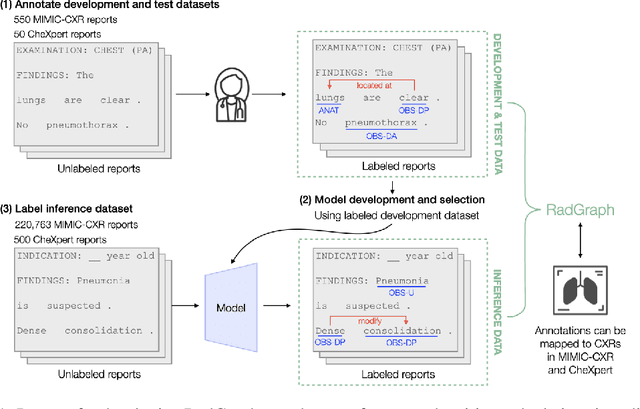
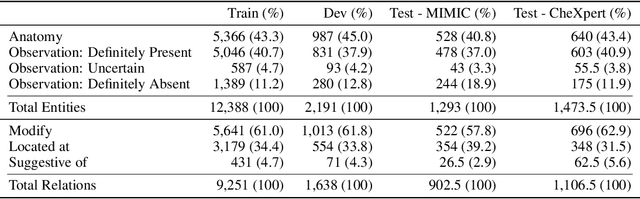
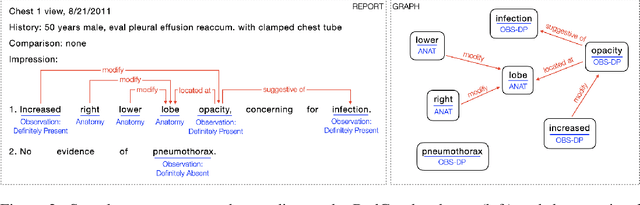
Extracting structured clinical information from free-text radiology reports can enable the use of radiology report information for a variety of critical healthcare applications. In our work, we present RadGraph, a dataset of entities and relations in full-text chest X-ray radiology reports based on a novel information extraction schema we designed to structure radiology reports. We release a development dataset, which contains board-certified radiologist annotations for 500 radiology reports from the MIMIC-CXR dataset (14,579 entities and 10,889 relations), and a test dataset, which contains two independent sets of board-certified radiologist annotations for 100 radiology reports split equally across the MIMIC-CXR and CheXpert datasets. Using these datasets, we train and test a deep learning model, RadGraph Benchmark, that achieves a micro F1 of 0.82 and 0.73 on relation extraction on the MIMIC-CXR and CheXpert test sets respectively. Additionally, we release an inference dataset, which contains annotations automatically generated by RadGraph Benchmark across 220,763 MIMIC-CXR reports (around 6 million entities and 4 million relations) and 500 CheXpert reports (13,783 entities and 9,908 relations) with mappings to associated chest radiographs. Our freely available dataset can facilitate a wide range of research in medical natural language processing, as well as computer vision and multi-modal learning when linked to chest radiographs.
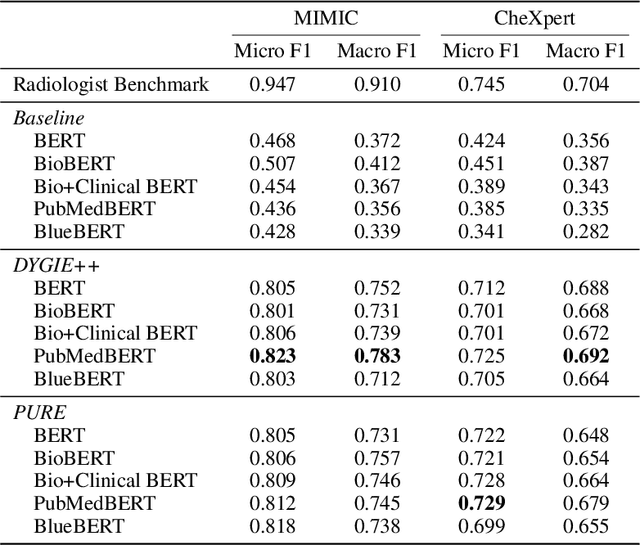
Effect of Radiology Report Labeler Quality on Deep Learning Models for Chest X-Ray Interpretation
Apr 01, 2021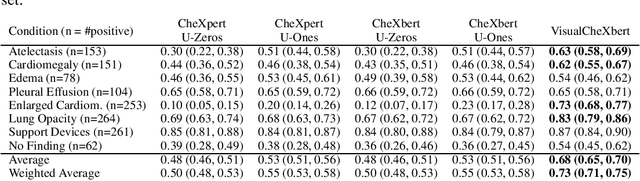

Although deep learning models for chest X-ray interpretation are commonly trained on labels generated by automatic radiology report labelers, the impact of improvements in report labeling on the performance of chest X-ray classification models has not been systematically investigated. We first compare the CheXpert, CheXbert, and VisualCheXbert labelers on the task of extracting accurate chest X-ray image labels from radiology reports, reporting that the VisualCheXbert labeler outperforms the CheXpert and CheXbert labelers. Next, after training image classification models using labels generated from the different radiology report labelers on one of the largest datasets of chest X-rays, we show that an image classification model trained on labels from the VisualCheXbert labeler outperforms image classification models trained on labels from the CheXpert and CheXbert labelers. Our work suggests that recent improvements in radiology report labeling can translate to the development of higher performing chest X-ray classification models.
VisualCheXbert: Addressing the Discrepancy Between Radiology Report Labels and Image Labels
Mar 15, 2021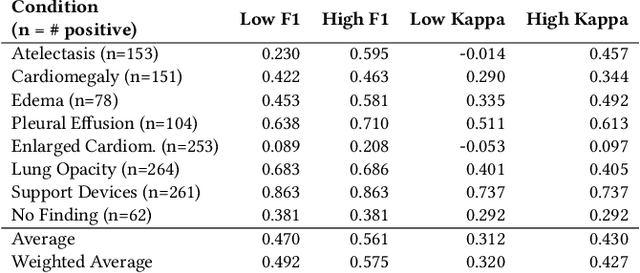
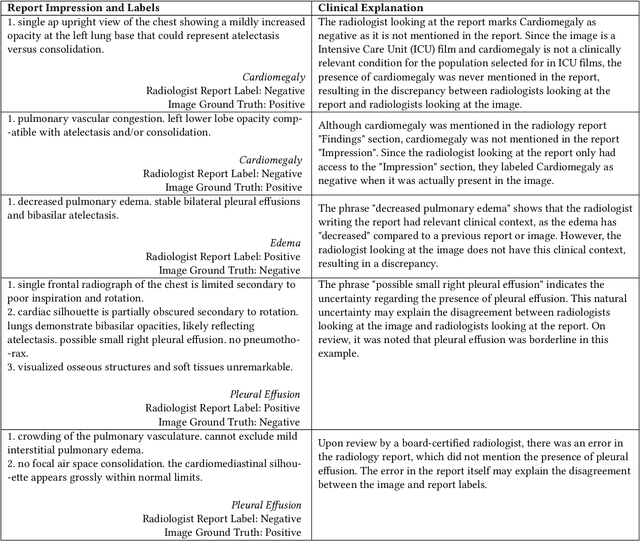

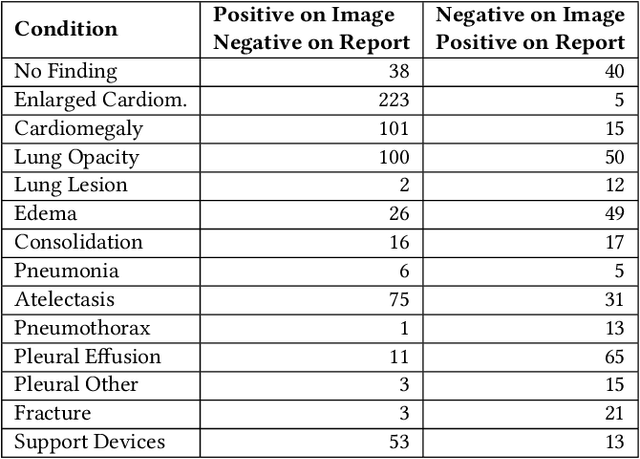
Automatic extraction of medical conditions from free-text radiology reports is critical for supervising computer vision models to interpret medical images. In this work, we show that radiologists labeling reports significantly disagree with radiologists labeling corresponding chest X-ray images, which reduces the quality of report labels as proxies for image labels. We develop and evaluate methods to produce labels from radiology reports that have better agreement with radiologists labeling images. Our best performing method, called VisualCheXbert, uses a biomedically-pretrained BERT model to directly map from a radiology report to the image labels, with a supervisory signal determined by a computer vision model trained to detect medical conditions from chest X-ray images. We find that VisualCheXbert outperforms an approach using an existing radiology report labeler by an average F1 score of 0.14 (95% CI 0.12, 0.17). We also find that VisualCheXbert better agrees with radiologists labeling chest X-ray images than do radiologists labeling the corresponding radiology reports by an average F1 score across several medical conditions of between 0.12 (95% CI 0.09, 0.15) and 0.21 (95% CI 0.18, 0.24).
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
Apr 30, 2020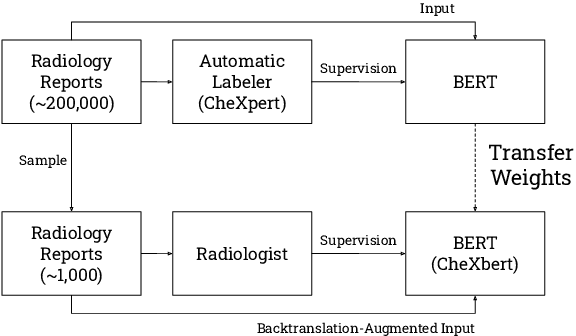
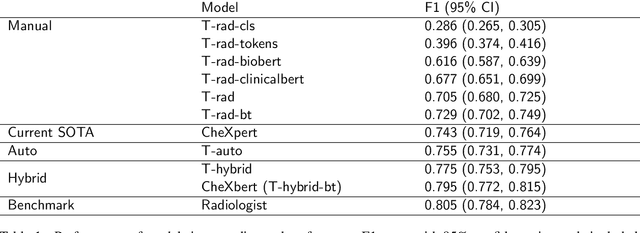
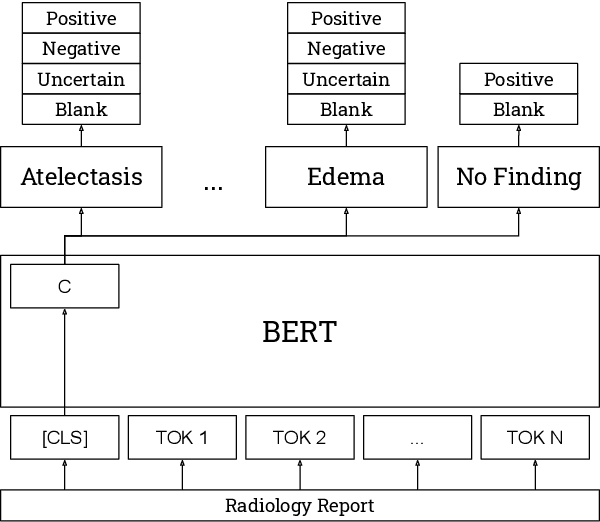
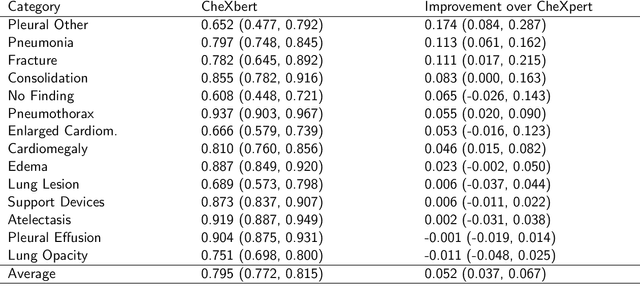
The extraction of labels from radiology text reports enables large-scale training of medical imaging models. Existing approaches to report labeling typically rely either on sophisticated feature engineering based on medical domain knowledge or manual annotations by experts. In this work, we introduce a BERT-based approach to medical image report labeling that exploits both the scale of available rule-based systems and the quality of expert annotations. We demonstrate superior performance of a biomedically pretrained BERT model first trained on annotations of a rule-based labeler and then finetuned on a small set of expert annotations augmented with automated backtranslation. We find that our final model, CheXbert, is able to outperform the previous best rules-based labeler with statistical significance, setting a new SOTA for report labeling on one of the largest datasets of chest x-rays.