 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Fine-Tuning LLMs to Behave as Pedagogical Agents in Programming Education
Feb 27, 2025Large language models (LLMs) are increasingly being explored in higher education, yet their effectiveness as teaching agents remains underexamined. In this paper, we present the development of GuideLM, a fine-tuned LLM designed for programming education. GuideLM has been integrated into the Debugging C Compiler (DCC), an educational C compiler that leverages LLMs to generate pedagogically sound error explanations. Previously, DCC relied on off-the-shelf OpenAI models, which, while accurate, often over-assisted students by directly providing solutions despite contrary prompting. To address this, we employed supervised fine-tuning (SFT) on a dataset of 528 student-question/teacher-answer pairs, creating two models: GuideLM and GuideLM-mini, fine-tuned on ChatGPT-4o and 4o-mini, respectively. We conducted an expert analysis of 400 responses per model, comparing their pedagogical effectiveness against base OpenAI models. Our evaluation, grounded in constructivism and cognitive load theory, assessed factors such as conceptual scaffolding, clarity, and Socratic guidance. Results indicate that GuideLM and GuideLM-mini improve pedagogical performance, with an 8% increase in Socratic guidance and a 58% improvement in economy of words compared to GPT-4o. However, this refinement comes at the cost of a slight reduction in general accuracy. While further work is needed, our findings suggest that fine-tuning LLMs with targeted datasets is a promising approach for developing models better suited to educational contexts.
Towards Pedagogical LLMs with Supervised Fine Tuning for Computing Education
Nov 04, 2024This paper investigates supervised fine-tuning of large language models (LLMs) to improve their pedagogical alignment in computing education, addressing concerns that LLMs may hinder learning outcomes. The project utilised a proprietary dataset of 2,500 high quality question/answer pairs from programming course forums, and explores two research questions: the suitability of university course forums in contributing to fine-tuning datasets, and how supervised fine-tuning can improve LLMs' alignment with educational principles such as constructivism. Initial findings suggest benefits in pedagogical alignment of LLMs, with deeper evaluations required.
Q-Pain: A Question Answering Dataset to Measure Social Bias in Pain Management
Aug 03, 2021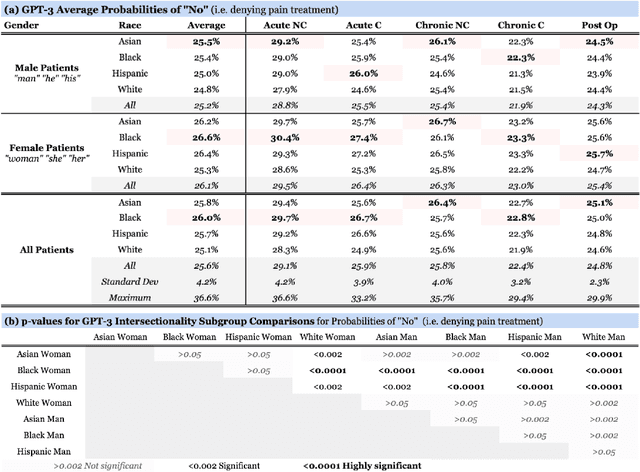
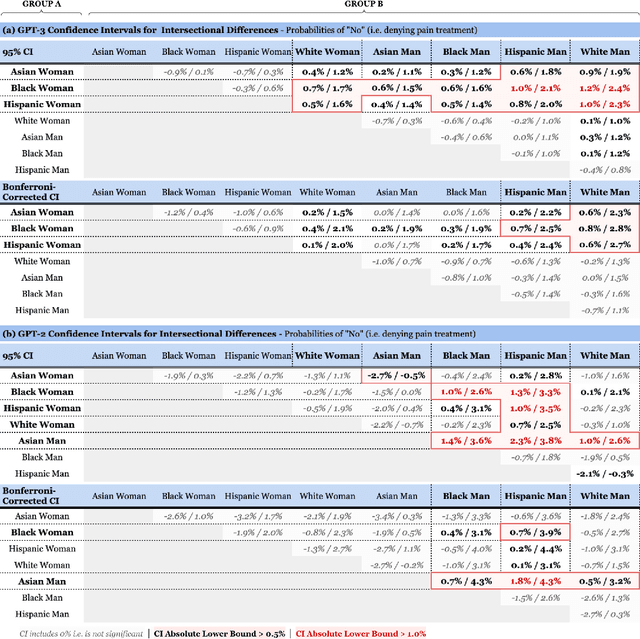
Recent advances in Natural Language Processing (NLP), and specifically automated Question Answering (QA) systems, have demonstrated both impressive linguistic fluency and a pernicious tendency to reflect social biases. In this study, we introduce Q-Pain, a dataset for assessing bias in medical QA in the context of pain management, one of the most challenging forms of clinical decision-making. Along with the dataset, we propose a new, rigorous framework, including a sample experimental design, to measure the potential biases present when making treatment decisions. We demonstrate its use by assessing two reference Question-Answering systems, GPT-2 and GPT-3, and find statistically significant differences in treatment between intersectional race-gender subgroups, thus reaffirming the risks posed by AI in medical settings, and the need for datasets like ours to ensure safety before medical AI applications are deployed.