 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Literacy, Safety Awareness, and STEM Career Aspirations of Australian Secondary Students: Evaluating the Impact of Workshop Interventions
Jan 30, 2026Deepfakes and other forms of synthetic media pose growing safety risks for adolescents, yet evidence on students' exposure and related behaviours remains limited. This study evaluates the impact of Day of AI Australia's workshop-based intervention designed to improve AI literacy and conceptual understanding among Australian secondary students (Years 7-10). Using a mixed-methods approach with pre- and post-intervention surveys (N=205 pre; N=163 post), we analyse changes in students' ability to identify AI in everyday tools, their understanding of AI ethics, training, and safety, and their interest in STEM-related careers. Baseline data revealed notable synthetic media risks: 82.4% of students reported having seen deepfakes, 18.5% reported sharing them, and 7.3% reported creating them. Results show higher self-reported AI knowledge and confidence after the intervention, alongside improved recognition of AI in widely used platforms such as Netflix, Spotify, and TikTok. This pattern suggests a shift from seeing these tools as merely "algorithm-based" to recognising them as AI-driven systems. Students also reported increased interest in STEM careers post-workshop; however, effect sizes were small, indicating that sustained approaches beyond one-off workshops may be needed to influence longer-term aspirations. Overall, the findings support scalable AI literacy programs that pair foundational AI concepts with an explicit emphasis on synthetic media safety.
Supervised Fine-Tuning LLMs to Behave as Pedagogical Agents in Programming Education
Feb 27, 2025Large language models (LLMs) are increasingly being explored in higher education, yet their effectiveness as teaching agents remains underexamined. In this paper, we present the development of GuideLM, a fine-tuned LLM designed for programming education. GuideLM has been integrated into the Debugging C Compiler (DCC), an educational C compiler that leverages LLMs to generate pedagogically sound error explanations. Previously, DCC relied on off-the-shelf OpenAI models, which, while accurate, often over-assisted students by directly providing solutions despite contrary prompting. To address this, we employed supervised fine-tuning (SFT) on a dataset of 528 student-question/teacher-answer pairs, creating two models: GuideLM and GuideLM-mini, fine-tuned on ChatGPT-4o and 4o-mini, respectively. We conducted an expert analysis of 400 responses per model, comparing their pedagogical effectiveness against base OpenAI models. Our evaluation, grounded in constructivism and cognitive load theory, assessed factors such as conceptual scaffolding, clarity, and Socratic guidance. Results indicate that GuideLM and GuideLM-mini improve pedagogical performance, with an 8% increase in Socratic guidance and a 58% improvement in economy of words compared to GPT-4o. However, this refinement comes at the cost of a slight reduction in general accuracy. While further work is needed, our findings suggest that fine-tuning LLMs with targeted datasets is a promising approach for developing models better suited to educational contexts.
Towards Pedagogical LLMs with Supervised Fine Tuning for Computing Education
Nov 04, 2024This paper investigates supervised fine-tuning of large language models (LLMs) to improve their pedagogical alignment in computing education, addressing concerns that LLMs may hinder learning outcomes. The project utilised a proprietary dataset of 2,500 high quality question/answer pairs from programming course forums, and explores two research questions: the suitability of university course forums in contributing to fine-tuning datasets, and how supervised fine-tuning can improve LLMs' alignment with educational principles such as constructivism. Initial findings suggest benefits in pedagogical alignment of LLMs, with deeper evaluations required.
Scaling CS1 Support with Compiler-Integrated Conversational AI
Jul 22, 2024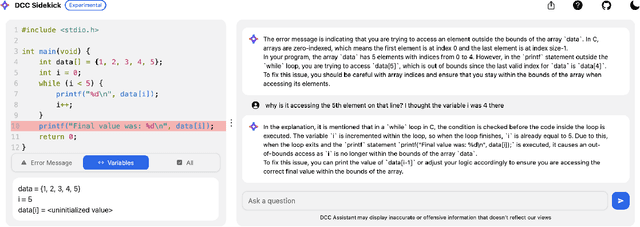

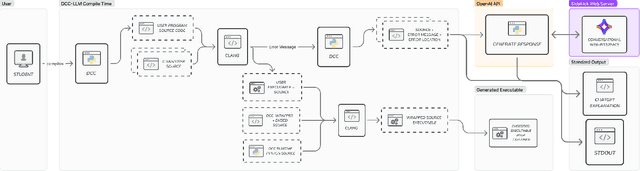
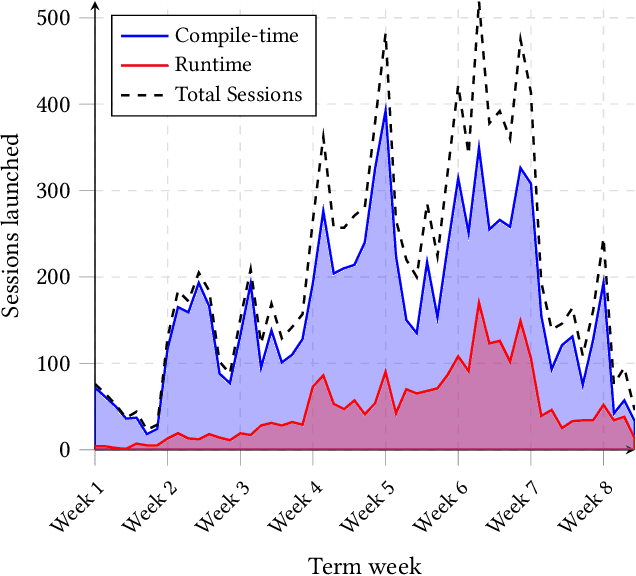
This paper introduces DCC Sidekick, a web-based conversational AI tool that enhances an existing LLM-powered C/C++ compiler by generating educational programming error explanations. The tool seamlessly combines code display, compile- and run-time error messages, and stack frame read-outs alongside an AI interface, leveraging compiler error context for improved explanations. We analyse usage data from a large Australian CS1 course, where 959 students engaged in 11,222 DCC Sidekick sessions, resulting in 17,982 error explanations over seven weeks. Notably, over 50% of interactions occurred outside business hours, underscoring the tool's value as an always-available resource. Our findings reveal strong adoption of AI-assisted debugging tools, demonstrating their scalability in supporting extensive CS1 courses. We provide implementation insights and recommendations for educators seeking to incorporate AI tools with appropriate pedagogical safeguards.
On the relevance of pre-neural approaches in natural language processing pedagogy
May 16, 2024


While neural approaches using deep learning are the state-of-the-art for natural language processing (NLP) today, pre-neural algorithms and approaches still find a place in NLP textbooks and courses of recent years. In this paper, we compare two introductory NLP courses taught in Australia and India, and examine how Transformer and pre-neural approaches are balanced within the lecture plan and assessments of the courses. We also draw parallels with the objects-first and objects-later debate in CS1 education. We observe that pre-neural approaches add value to student learning by building an intuitive understanding of NLP problems, potential solutions and even Transformer-based models themselves. Despite pre-neural approaches not being state-of-the-art, the paper makes a case for their inclusion in NLP courses today.
Integrating Large Language Models into the Debugging C Compiler for generating contextual error explanations
Aug 23, 2023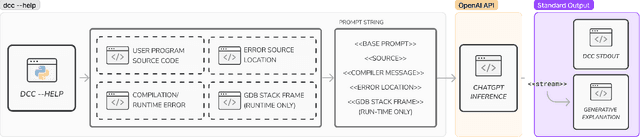
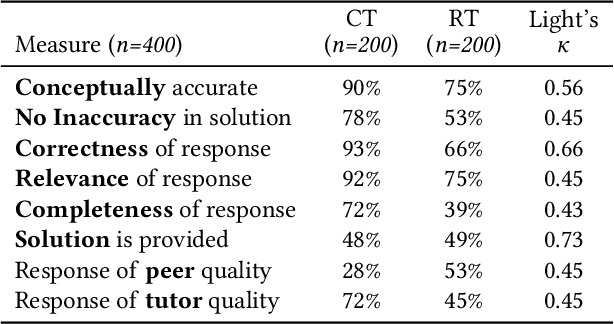
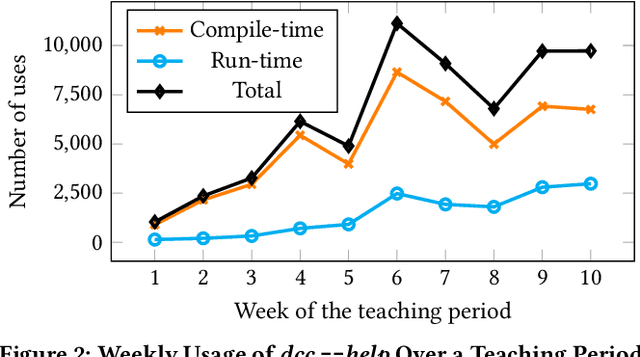
This paper introduces a method for Large Language Models (LLM) to produce enhanced compiler error explanations, in simple language, within our Debugging C Compiler (DCC). It is well documented that compiler error messages have been known to present a barrier for novices learning how to program. Although our initial use of DCC in introductory programming (CS1) has been instrumental in teaching C to novice programmers by providing safeguards to commonly occurring errors and translating the usually cryptic compiler error messages at both compile- and run-time, we proposed that incorporating LLM-generated explanations would further enhance the learning experience for novice programmers. Through an expert evaluation, we observed that LLM-generated explanations for compiler errors were conceptually accurate in 90% of compile-time errors, and 75% of run-time errors. Additionally, the new DCC-help tool has been increasingly adopted by students, with an average of 1047 unique runs per week, demonstrating a promising initial assessment of using LLMs to complement compiler output to enhance programming education for beginners. We release our tool as open-source to the community.