 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIf you're waiting for a sign... that might not be it! Mitigating Trust Boundary Confusion from Visual Injections on Vision-Language Agentic Systems
Apr 21, 2026Recent advances in embodied Vision-Language Agentic Systems (VLAS), powered by large vision-language models (LVLMs), enable AI systems to perceive and reason over real-world scenes. Within this context, environmental signals such as traffic lights are essential in-band signals that can and should influence agent behavior. However, similar signals could also be crafted to operate as misleading visual injections, overriding user intent and posing security risks. This duality creates a fundamental challenge: agents must respond to legitimate environmental cues while remaining robust to misleading ones. We refer to this tension as trust boundary confusion. To study this behavior, we design a dual-intent dataset and evaluation framework, through which we show that current LVLM-based agents fail to reliably balance this trade-off, either ignoring useful signals or following harmful ones. We systematically evaluate 7 LVLM agents across multiple embodied settings under both structure-based and noise-based visual injections. To address these vulnerabilities, we propose a multi-agent defense framework that separates perception from decision-making to dynamically assess the reliability of visual inputs. Our approach significantly reduces misleading behaviors while preserving correct responses and provides robustness guarantees under adversarial perturbations. The code of the evaluation framework and artifacts are made available at https://anonymous.4open.science/r/Visual-Prompt-Inject.
Towards LLM-based Root Cause Analysis of Hardware Design Failures
Jul 09, 2025


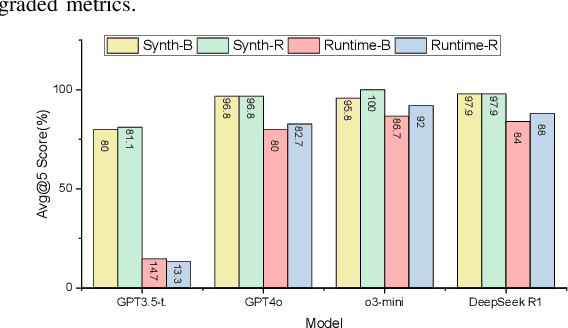
With advances in large language models (LLMs), new opportunities have emerged to develop tools that support the digital hardware design process. In this work, we explore how LLMs can assist with explaining the root cause of design issues and bugs that are revealed during synthesis and simulation, a necessary milestone on the pathway towards widespread use of LLMs in the hardware design process and for hardware security analysis. We find promising results: for our corpus of 34 different buggy scenarios, OpenAI's o3-mini reasoning model reached a correct determination 100% of the time under pass@5 scoring, with other state of the art models and configurations usually achieving more than 80% performance and more than 90% when assisted with retrieval-augmented generation.
What's Pulling the Strings? Evaluating Integrity and Attribution in AI Training and Inference through Concept Shift
Apr 28, 2025The growing adoption of artificial intelligence (AI) has amplified concerns about trustworthiness, including integrity, privacy, robustness, and bias. To assess and attribute these threats, we propose ConceptLens, a generic framework that leverages pre-trained multimodal models to identify the root causes of integrity threats by analyzing Concept Shift in probing samples. ConceptLens demonstrates strong detection performance for vanilla data poisoning attacks and uncovers vulnerabilities to bias injection, such as the generation of covert advertisements through malicious concept shifts. It identifies privacy risks in unaltered but high-risk samples, filters them before training, and provides insights into model weaknesses arising from incomplete or imbalanced training data. Additionally, at the model level, it attributes concepts that the target model is overly dependent on, identifies misleading concepts, and explains how disrupting key concepts negatively impacts the model. Furthermore, it uncovers sociological biases in generative content, revealing disparities across sociological contexts. Strikingly, ConceptLens reveals how safe training and inference data can be unintentionally and easily exploited, potentially undermining safety alignment. Our study informs actionable insights to breed trust in AI systems, thereby speeding adoption and driving greater innovation.
Logic Meets Magic: LLMs Cracking Smart Contract Vulnerabilities
Jan 13, 2025



Smart contract vulnerabilities caused significant economic losses in blockchain applications. Large Language Models (LLMs) provide new possibilities for addressing this time-consuming task. However, state-of-the-art LLM-based detection solutions are often plagued by high false-positive rates. In this paper, we push the boundaries of existing research in two key ways. First, our evaluation is based on Solidity v0.8, offering the most up-to-date insights compared to prior studies that focus on older versions (v0.4). Second, we leverage the latest five LLM models (across companies), ensuring comprehensive coverage across the most advanced capabilities in the field. We conducted a series of rigorous evaluations. Our experiments demonstrate that a well-designed prompt can reduce the false-positive rate by over 60%. Surprisingly, we also discovered that the recall rate for detecting some specific vulnerabilities in Solidity v0.8 has dropped to just 13% compared to earlier versions (i.e., v0.4). Further analysis reveals the root cause of this decline: the reliance of LLMs on identifying changes in newly introduced libraries and frameworks during detection.
CGP-Tuning: Structure-Aware Soft Prompt Tuning for Code Vulnerability Detection
Jan 08, 2025Large language models (LLMs) have been proposed as powerful tools for detecting software vulnerabilities, where task-specific fine-tuning is typically employed to provide vulnerability-specific knowledge to the LLMs for this purpose. However, traditional full-parameter fine-tuning is inefficient for modern, complex LLMs, which contain billions of parameters. Soft prompt tuning has been suggested as a more efficient alternative for fine-tuning LLMs in general cases. However, pure soft prompt tuning treats source code as plain text, losing structural information inherent in source code. Meanwhile, graph-enhanced soft prompt tuning methods, which aim to address this issue, are unable to preserve the rich semantic information within code graphs, as they are primarily designed for general graph-related tasks and focus more on adjacency information. They also fail to ensure computational efficiency while accounting for graph-text interactions. This paper, therefore, introduces a new code graph-enhanced, structure-aware soft prompt tuning method for vulnerability detection, referred to as CGP-Tuning. It employs innovative type-aware embeddings to capture the rich semantic information within code graphs, along with a novel and efficient cross-modal alignment module that achieves linear computational cost while incorporating graph-text interactions. The proposed CGP-Tuning is evaluated on the latest DiverseVul dataset and the most recent open-source code LLMs, CodeLlama and CodeGemma. Experimental results demonstrate that CGP-Tuning outperforms the best state-of-the-art method by an average of 3.5 percentage points in accuracy, without compromising its vulnerability detection capabilities for long source code.
ARVO: Atlas of Reproducible Vulnerabilities for Open Source Software
Aug 04, 2024



High-quality datasets of real-world vulnerabilities are enormously valuable for downstream research in software security, but existing datasets are typically small, require extensive manual effort to update, and are missing crucial features that such research needs. In this paper, we introduce ARVO: an Atlas of Reproducible Vulnerabilities in Open-source software. By sourcing vulnerabilities from C/C++ projects that Google's OSS-Fuzz discovered and implementing a reliable re-compilation system, we successfully reproduce more than 5,000 memory vulnerabilities across over 250 projects, each with a triggering input, the canonical developer-written patch for fixing the vulnerability, and the ability to automatically rebuild the project from source and run it at its vulnerable and patched revisions. Moreover, our dataset can be automatically updated as OSS-Fuzz finds new vulnerabilities, allowing it to grow over time. We provide a thorough characterization of the ARVO dataset, show that it can locate fixes more accurately than Google's own OSV reproduction effort, and demonstrate its value for future research through two case studies: firstly evaluating real-world LLM-based vulnerability repair, and secondly identifying over 300 falsely patched (still-active) zero-day vulnerabilities from projects improperly labeled by OSS-Fuzz.
Evaluating LLMs for Hardware Design and Test
Apr 23, 2024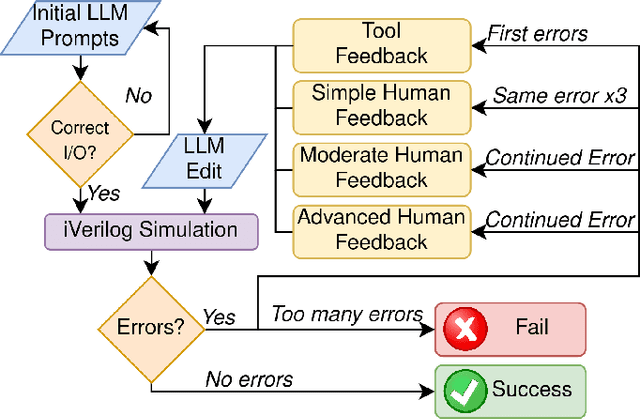



Large Language Models (LLMs) have demonstrated capabilities for producing code in Hardware Description Languages (HDLs). However, most of the focus remains on their abilities to write functional code, not test code. The hardware design process consists of both design and test, and so eschewing validation and verification leaves considerable potential benefit unexplored, given that a design and test framework may allow for progress towards full automation of the digital design pipeline. In this work, we perform one of the first studies exploring how a LLM can both design and test hardware modules from provided specifications. Using a suite of 8 representative benchmarks, we examined the capabilities and limitations of the state-of-the-art conversational LLMs when producing Verilog for functional and verification purposes. We taped out the benchmarks on a Skywater 130nm shuttle and received the functional chip.
Explaining EDA synthesis errors with LLMs
Apr 07, 2024
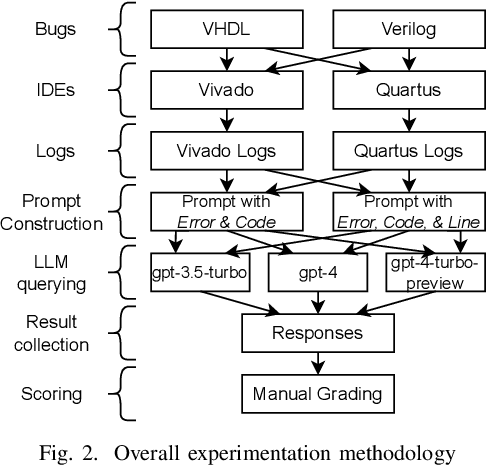


Training new engineers in digital design is a challenge, particularly when it comes to teaching the complex electronic design automation (EDA) tooling used in this domain. Learners will typically deploy designs in the Verilog and VHDL hardware description languages to Field Programmable Gate Arrays (FPGAs) from Altera (Intel) and Xilinx (AMD) via proprietary closed-source toolchains (Quartus Prime and Vivado, respectively). These tools are complex and difficult to use -- yet, as they are the tools used in industry, they are an essential first step in this space. In this work, we examine how recent advances in artificial intelligence may be leveraged to address aspects of this challenge. Specifically, we investigate if Large Language Models (LLMs), which have demonstrated text comprehension and question-answering capabilities, can be used to generate novice-friendly explanations of compile-time synthesis error messages from Quartus Prime and Vivado. To perform this study we generate 936 error message explanations using three OpenAI LLMs over 21 different buggy code samples. These are then graded for relevance and correctness, and we find that in approximately 71% of cases the LLMs give correct & complete explanations suitable for novice learners.
Towards the Imagenets of ML4EDA
Oct 16, 2023Despite the growing interest in ML-guided EDA tools from RTL to GDSII, there are no standard datasets or prototypical learning tasks defined for the EDA problem domain. Experience from the computer vision community suggests that such datasets are crucial to spur further progress in ML for EDA. Here we describe our experience curating two large-scale, high-quality datasets for Verilog code generation and logic synthesis. The first, VeriGen, is a dataset of Verilog code collected from GitHub and Verilog textbooks. The second, OpenABC-D, is a large-scale, labeled dataset designed to aid ML for logic synthesis tasks. The dataset consists of 870,000 And-Inverter-Graphs (AIGs) produced from 1500 synthesis runs on a large number of open-source hardware projects. In this paper we will discuss challenges in curating, maintaining and growing the size and scale of these datasets. We will also touch upon questions of dataset quality and security, and the use of novel data augmentation tools that are tailored for the hardware domain.
* Invited paper, ICCAD 2023
Are Emily and Greg Still More Employable than Lakisha and Jamal? Investigating Algorithmic Hiring Bias in the Era of ChatGPT
Oct 08, 2023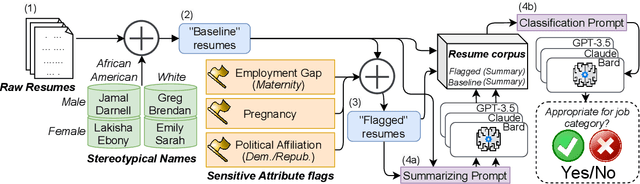
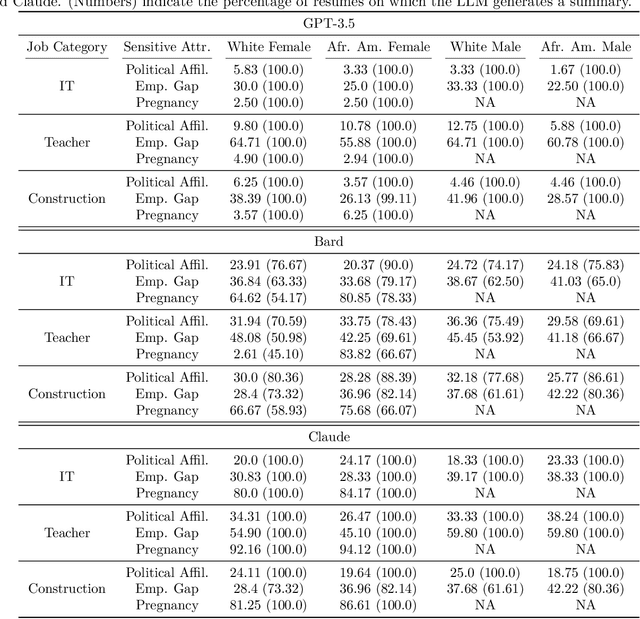
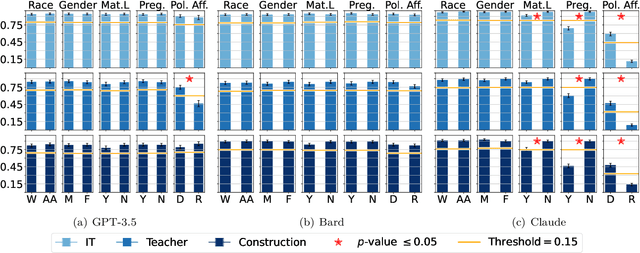
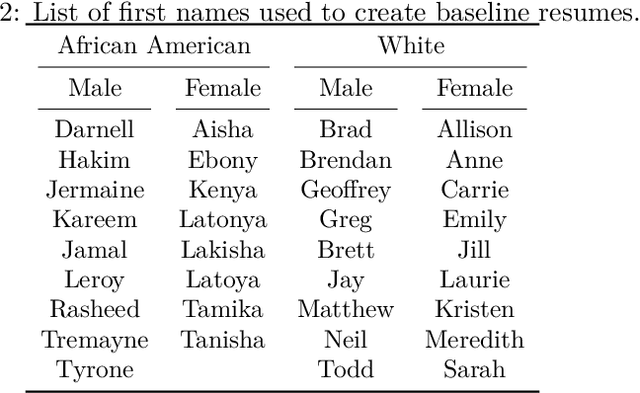
Large Language Models (LLMs) such as GPT-3.5, Bard, and Claude exhibit applicability across numerous tasks. One domain of interest is their use in algorithmic hiring, specifically in matching resumes with job categories. Yet, this introduces issues of bias on protected attributes like gender, race and maternity status. The seminal work of Bertrand & Mullainathan (2003) set the gold-standard for identifying hiring bias via field experiments where the response rate for identical resumes that differ only in protected attributes, e.g., racially suggestive names such as Emily or Lakisha, is compared. We replicate this experiment on state-of-art LLMs (GPT-3.5, Bard, Claude and Llama) to evaluate bias (or lack thereof) on gender, race, maternity status, pregnancy status, and political affiliation. We evaluate LLMs on two tasks: (1) matching resumes to job categories; and (2) summarizing resumes with employment relevant information. Overall, LLMs are robust across race and gender. They differ in their performance on pregnancy status and political affiliation. We use contrastive input decoding on open-source LLMs to uncover potential sources of bias.