 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Approach for Large Language Models Debugging
Apr 24, 2026Large language models (LLMs) have become central to modern AI workflows, powering applications from open-ended text generation to complex agent-based reasoning. However, debugging these models remains a persistent challenge due to their opaque and probabilistic nature and the difficulty of diagnosing errors across diverse tasks and settings. This paper introduces a systematic approach for LLM debugging that treats models as observable systems, providing structured, model-agnostic methods from issue detection to model refinement. By unifying evaluation, interpretability, and error-analysis practices, our approach enables practitioners to iteratively diagnose model weaknesses, refine prompts and model parameters, and adapt data for fine-tuning or assessment, while remaining effective in contexts where standardized benchmarks and evaluation criteria are lacking. We argue that such a structured methodology not only accelerates troubleshooting but also fosters reproducibility, transparency, and scalability in the deployment of LLM-based systems.
STaD: Scaffolded Task Design for Identifying Compositional Skill Gaps in LLMs
Apr 21, 2026Benchmarks are often used as a standard to understand LLM capabilities in different domains. However, aggregate benchmark scores provide limited insight into compositional skill gaps of LLMs and how to improve them. To make these weaknesses visible, we propose Scaffolded Task Design (STaD) framework. STaD generates controlled variations of benchmark tasks based on the concept of scaffolding, which introduces structured, incremental support in a step-by-step manner. Rather than inspecting failures individually, this approach enables systematic and scalable probing of model behavior by identifying the specific reasoning skill compositions they lack. Treating the LLM as a black box, our experiments on six models of varying sizes reveal multiple failure points in three reasoning benchmarks and highlight each model's unique and distinct skill gaps.
Make Every Move Count: LLM-based High-Quality RTL Code Generation Using MCTS
Feb 05, 2024Existing large language models (LLMs) for register transfer level code generation face challenges like compilation failures and suboptimal power, performance, and area (PPA) efficiency. This is due to the lack of PPA awareness in conventional transformer decoding algorithms. In response, we present an automated transformer decoding algorithm that integrates Monte Carlo tree-search for lookahead, guiding the transformer to produce compilable, functionally correct, and PPA-optimized code. Empirical evaluation with a fine-tuned language model on RTL codesets shows that our proposed technique consistently generates functionally correct code compared to prompting-only methods and effectively addresses the PPA-unawareness drawback of naive large language models. For the largest design generated by the state-of-the-art LLM (16-bit adder), our technique can achieve a 31.8% improvement in the area-delay product.
Towards the Imagenets of ML4EDA
Oct 16, 2023Despite the growing interest in ML-guided EDA tools from RTL to GDSII, there are no standard datasets or prototypical learning tasks defined for the EDA problem domain. Experience from the computer vision community suggests that such datasets are crucial to spur further progress in ML for EDA. Here we describe our experience curating two large-scale, high-quality datasets for Verilog code generation and logic synthesis. The first, VeriGen, is a dataset of Verilog code collected from GitHub and Verilog textbooks. The second, OpenABC-D, is a large-scale, labeled dataset designed to aid ML for logic synthesis tasks. The dataset consists of 870,000 And-Inverter-Graphs (AIGs) produced from 1500 synthesis runs on a large number of open-source hardware projects. In this paper we will discuss challenges in curating, maintaining and growing the size and scale of these datasets. We will also touch upon questions of dataset quality and security, and the use of novel data augmentation tools that are tailored for the hardware domain.
* Invited paper, ICCAD 2023
Are Emily and Greg Still More Employable than Lakisha and Jamal? Investigating Algorithmic Hiring Bias in the Era of ChatGPT
Oct 08, 2023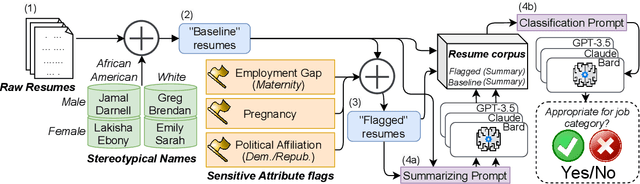
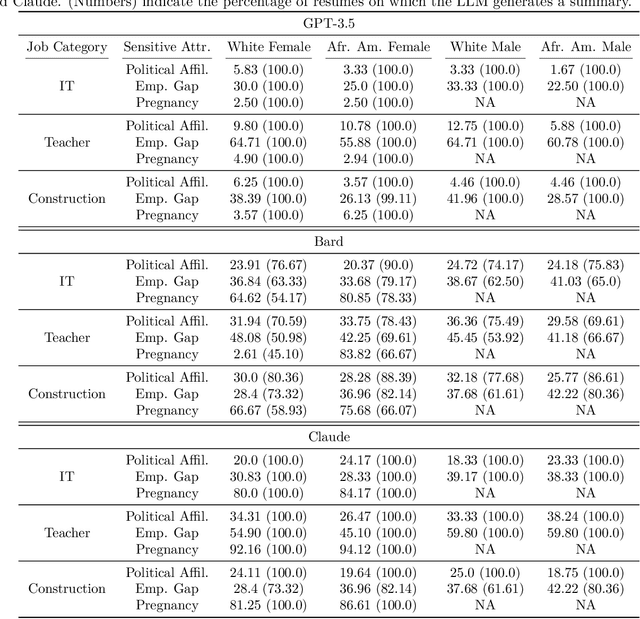
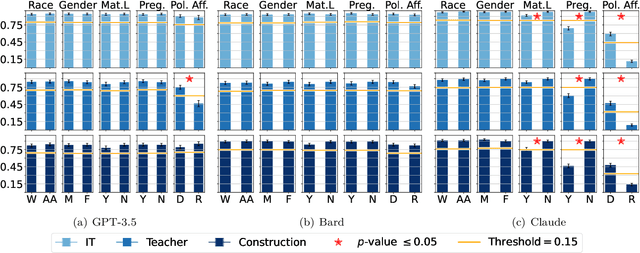
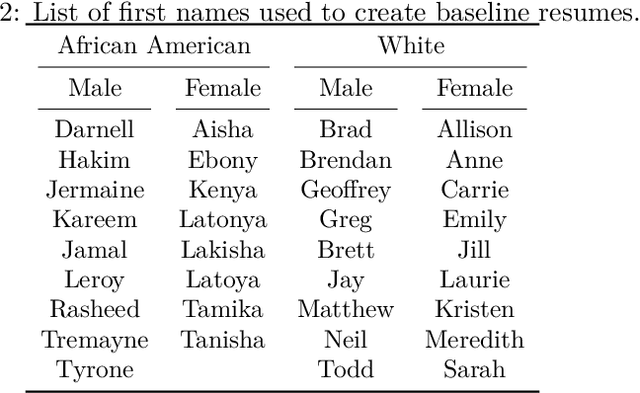
Large Language Models (LLMs) such as GPT-3.5, Bard, and Claude exhibit applicability across numerous tasks. One domain of interest is their use in algorithmic hiring, specifically in matching resumes with job categories. Yet, this introduces issues of bias on protected attributes like gender, race and maternity status. The seminal work of Bertrand & Mullainathan (2003) set the gold-standard for identifying hiring bias via field experiments where the response rate for identical resumes that differ only in protected attributes, e.g., racially suggestive names such as Emily or Lakisha, is compared. We replicate this experiment on state-of-art LLMs (GPT-3.5, Bard, Claude and Llama) to evaluate bias (or lack thereof) on gender, race, maternity status, pregnancy status, and political affiliation. We evaluate LLMs on two tasks: (1) matching resumes to job categories; and (2) summarizing resumes with employment relevant information. Overall, LLMs are robust across race and gender. They differ in their performance on pregnancy status and political affiliation. We use contrastive input decoding on open-source LLMs to uncover potential sources of bias.
VeriGen: A Large Language Model for Verilog Code Generation
Jul 28, 2023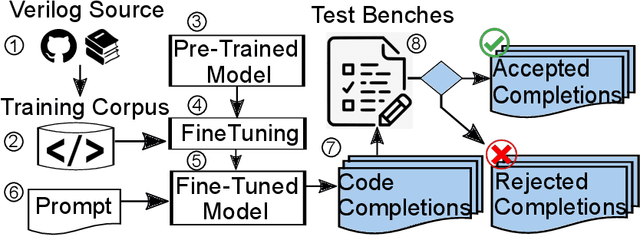
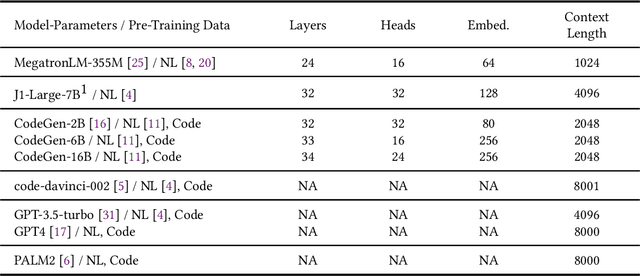

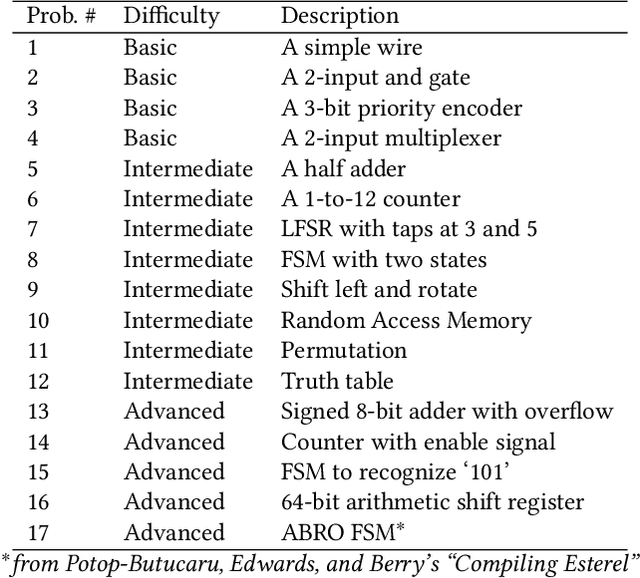
In this study, we explore the capability of Large Language Models (LLMs) to automate hardware design by generating high-quality Verilog code, a common language for designing and modeling digital systems. We fine-tune pre-existing LLMs on Verilog datasets compiled from GitHub and Verilog textbooks. We evaluate the functional correctness of the generated Verilog code using a specially designed test suite, featuring a custom problem set and testing benches. Here, our fine-tuned open-source CodeGen-16B model outperforms the commercial state-of-the-art GPT-3.5-turbo model with a 1.1% overall increase. Upon testing with a more diverse and complex problem set, we find that the fine-tuned model shows competitive performance against state-of-the-art gpt-3.5-turbo, excelling in certain scenarios. Notably, it demonstrates a 41% improvement in generating syntactically correct Verilog code across various problem categories compared to its pre-trained counterpart, highlighting the potential of smaller, in-house LLMs in hardware design automation.
LLM-assisted Generation of Hardware Assertions
Jun 24, 2023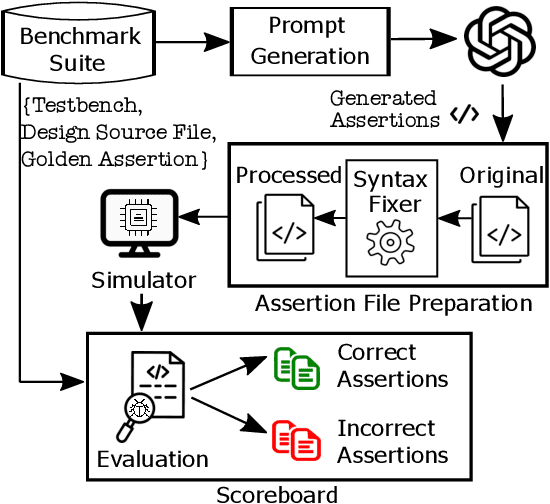
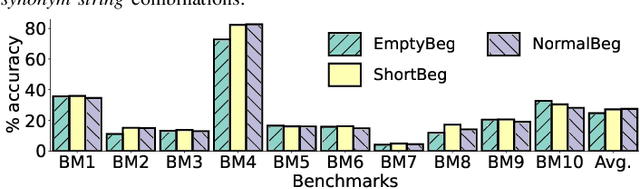
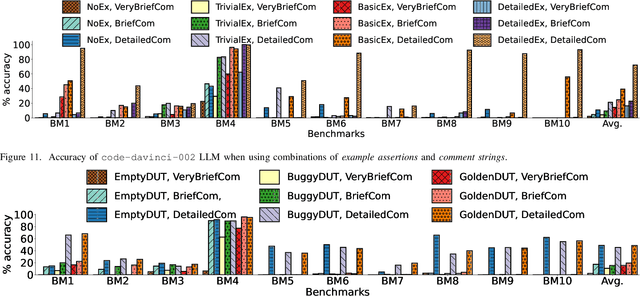
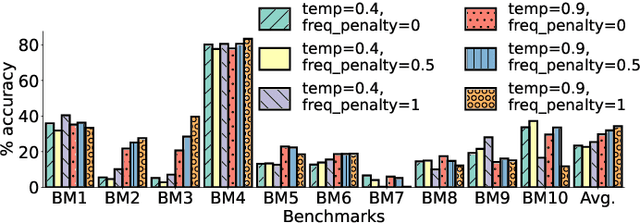
The security of computer systems typically relies on a hardware root of trust. As vulnerabilities in hardware can have severe implications on a system, there is a need for techniques to support security verification activities. Assertion-based verification is a popular verification technique that involves capturing design intent in a set of assertions that can be used in formal verification or testing-based checking. However, writing security-centric assertions is a challenging task. In this work, we investigate the use of emerging large language models (LLMs) for code generation in hardware assertion generation for security, where primarily natural language prompts, such as those one would see as code comments in assertion files, are used to produce SystemVerilog assertions. We focus our attention on a popular LLM and characterize its ability to write assertions out of the box, given varying levels of detail in the prompt. We design an evaluation framework that generates a variety of prompts, and we create a benchmark suite comprising real-world hardware designs and corresponding golden reference assertions that we want to generate with the LLM.
Security and Interpretability in Automotive Systems
Dec 23, 2022The lack of any sender authentication mechanism in place makes CAN (Controller Area Network) vulnerable to security threats. For instance, an attacker can impersonate an ECU (Electronic Control Unit) on the bus and send spoofed messages unobtrusively with the identifier of the impersonated ECU. To address the insecure nature of the system, this thesis demonstrates a sender authentication technique that uses power consumption measurements of the electronic control units (ECUs) and a classification model to determine the transmitting states of the ECUs. The method's evaluation in real-world settings shows that the technique applies in a broad range of operating conditions and achieves good accuracy. A key challenge of machine learning-based security controls is the potential of false positives. A false-positive alert may induce panic in operators, lead to incorrect reactions, and in the long run cause alarm fatigue. For reliable decision-making in such a circumstance, knowing the cause for unusual model behavior is essential. But, the black-box nature of these models makes them uninterpretable. Therefore, another contribution of this thesis explores explanation techniques for inputs of type image and time series that (1) assign weights to individual inputs based on their sensitivity toward the target class, (2) and quantify the variations in the explanation by reconstructing the sensitive regions of the inputs using a generative model. In summary, this thesis (https://uwspace.uwaterloo.ca/handle/10012/18134) presents methods for addressing the security and interpretability in automotive systems, which can also be applied in other settings where safe, transparent, and reliable decision-making is crucial.
Benchmarking Large Language Models for Automated Verilog RTL Code Generation
Dec 13, 2022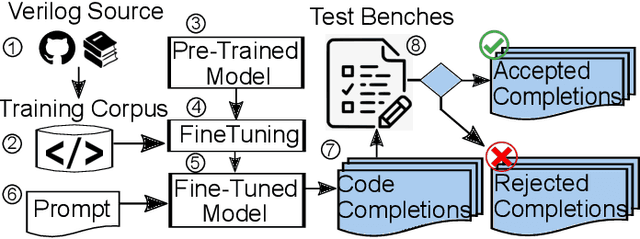



Automating hardware design could obviate a significant amount of human error from the engineering process and lead to fewer errors. Verilog is a popular hardware description language to model and design digital systems, thus generating Verilog code is a critical first step. Emerging large language models (LLMs) are able to write high-quality code in other programming languages. In this paper, we characterize the ability of LLMs to generate useful Verilog. For this, we fine-tune pre-trained LLMs on Verilog datasets collected from GitHub and Verilog textbooks. We construct an evaluation framework comprising test-benches for functional analysis and a flow to test the syntax of Verilog code generated in response to problems of varying difficulty. Our findings show that across our problem scenarios, the fine-tuning results in LLMs more capable of producing syntactically correct code (25.9% overall). Further, when analyzing functional correctness, a fine-tuned open-source CodeGen LLM can outperform the state-of-the-art commercial Codex LLM (6.5% overall). Training/evaluation scripts and LLM checkpoints are available: https://github.com/shailja-thakur/VGen.
A generalizable saliency map-based interpretation of model outcome
Jun 19, 2020

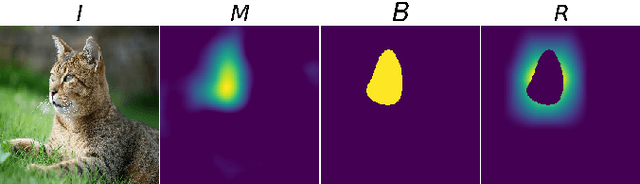
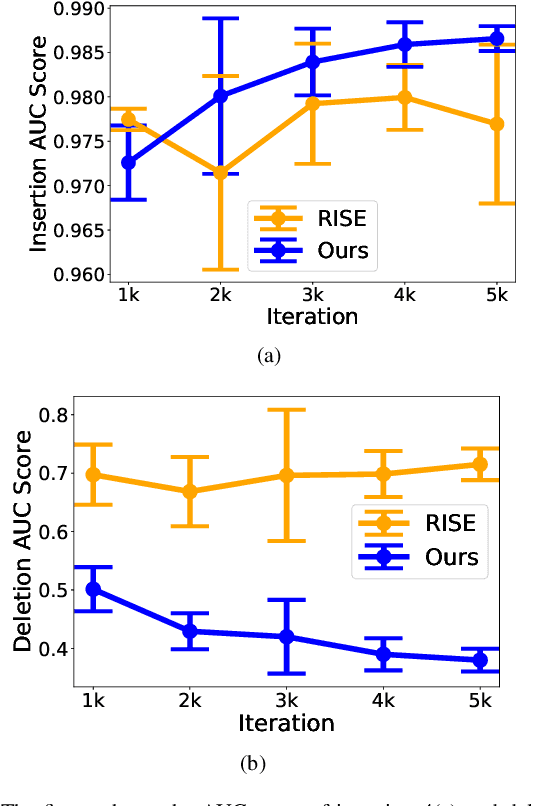
One of the significant challenges of deep neural networks is that the complex nature of the network prevents human comprehension of the outcome of the network. Consequently, the applicability of complex machine learning models is limited in the safety-critical domains, which incurs risk to life and property. To fully exploit the capabilities of complex neural networks, we propose a non-intrusive interpretability technique that uses the input and output of the model to generate a saliency map. The method works by empirically optimizing a randomly initialized input mask by localizing and weighing individual pixels according to their sensitivity towards the target class. Our experiments show that the proposed model interpretability approach performs better than the existing saliency map-based approaches methods at localizing the relevant input pixels. Furthermore, to obtain a global perspective on the target-specific explanation, we propose a saliency map reconstruction approach to generate acceptable variations of the salient inputs from the space of input data distribution for which the model outcome remains unaltered. Experiments show that our interpretability method can reconstruct the salient part of the input with a classification accuracy of 89%.