 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks
Dec 24, 2025We present the surprising finding that a language model's reasoning capabilities can be improved by training on synthetic datasets of chain-of-thought (CoT) traces from more capable models, even when all of those traces lead to an incorrect final answer. Our experiments show this approach can yield better performance on reasoning tasks than training on human-annotated datasets. We hypothesize that two key factors explain this phenomenon: first, the distribution of synthetic data is inherently closer to the language model's own distribution, making it more amenable to learning. Second, these `incorrect' traces are often only partially flawed and contain valid reasoning steps from which the model can learn. To further test the first hypothesis, we use a language model to paraphrase human-annotated traces -- shifting their distribution closer to the model's own distribution -- and show that this improves performance. For the second hypothesis, we introduce increasingly flawed CoT traces and study to what extent models are tolerant to these flaws. We demonstrate our findings across various reasoning domains like math, algorithmic reasoning and code generation using MATH, GSM8K, Countdown and MBPP datasets on various language models ranging from 1.5B to 9B across Qwen, Llama, and Gemma models. Our study shows that curating datasets that are closer to the model's distribution is a critical aspect to consider. We also show that a correct final answer is not always a reliable indicator of a faithful reasoning process.
SAC-MoE: Reinforcement Learning with Mixture-of-Experts for Control of Hybrid Dynamical Systems with Uncertainty
Nov 15, 2025
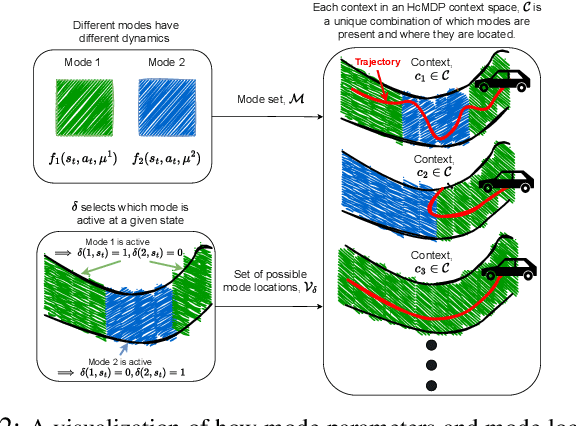
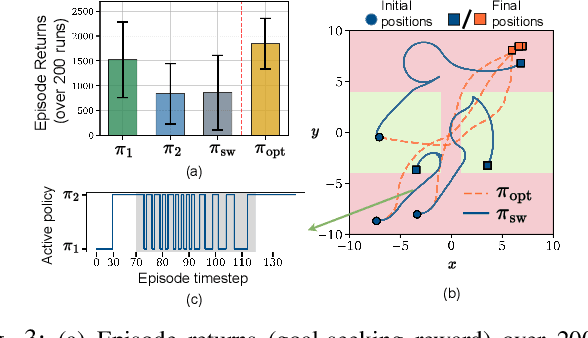
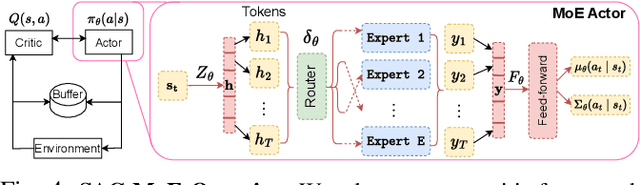
Hybrid dynamical systems result from the interaction of continuous-variable dynamics with discrete events and encompass various systems such as legged robots, vehicles and aircrafts. Challenges arise when the system's modes are characterized by unobservable (latent) parameters and the events that cause system dynamics to switch between different modes are also unobservable. Model-based control approaches typically do not account for such uncertainty in the hybrid dynamics, while standard model-free RL methods fail to account for abrupt mode switches, leading to poor generalization. To overcome this, we propose SAC-MoE which models the actor of the Soft Actor-Critic (SAC) framework as a Mixture-of-Experts (MoE) with a learned router that adaptively selects among learned experts. To further improve robustness, we develop a curriculum-based training algorithm to prioritize data collection in challenging settings, allowing better generalization to unseen modes and switching locations. Simulation studies in hybrid autonomous racing and legged locomotion tasks show that SAC-MoE outperforms baselines (up to 6x) in zero-shot generalization to unseen environments. Our curriculum strategy consistently improves performance across all evaluated policies. Qualitative analysis shows that the interpretable MoE router activates different experts for distinct latent modes.
VideoAgent: Self-Improving Video Generation
Oct 15, 2024



Video generation has been used to generate visual plans for controlling robotic systems. Given an image observation and a language instruction, previous work has generated video plans which are then converted to robot controls to be executed. However, a major bottleneck in leveraging video generation for control lies in the quality of the generated videos, which often suffer from hallucinatory content and unrealistic physics, resulting in low task success when control actions are extracted from the generated videos. While scaling up dataset and model size provides a partial solution, integrating external feedback is both natural and essential for grounding video generation in the real world. With this observation, we propose VideoAgent for self-improving generated video plans based on external feedback. Instead of directly executing the generated video plan, VideoAgent first refines the generated video plans using a novel procedure which we call self-conditioning consistency, utilizing feedback from a pretrained vision-language model (VLM). As the refined video plan is being executed, VideoAgent collects additional data from the environment to further improve video plan generation. Experiments in simulated robotic manipulation from MetaWorld and iTHOR show that VideoAgent drastically reduces hallucination, thereby boosting success rate of downstream manipulation tasks. We further illustrate that VideoAgent can effectively refine real-robot videos, providing an early indicator that robotics can be an effective tool in grounding video generation in the physical world.
A generalizable saliency map-based interpretation of model outcome
Jun 19, 2020

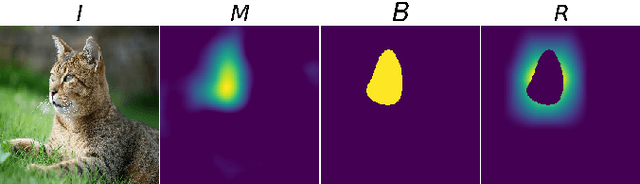
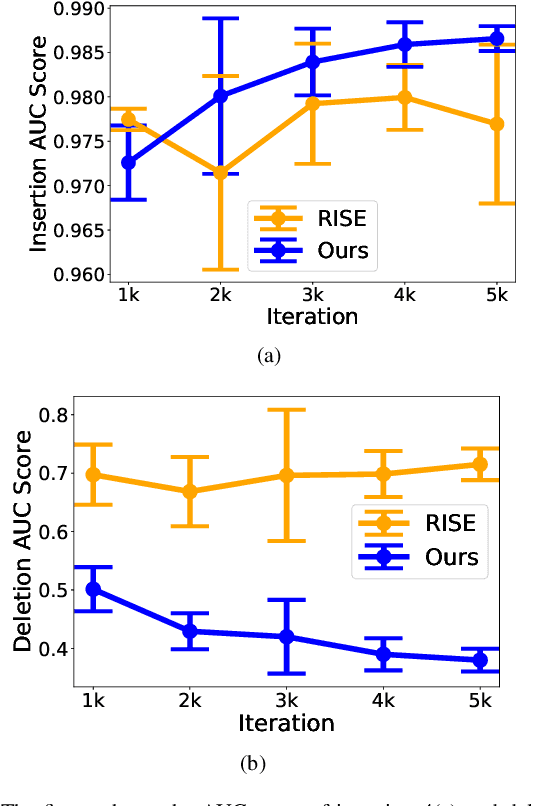
One of the significant challenges of deep neural networks is that the complex nature of the network prevents human comprehension of the outcome of the network. Consequently, the applicability of complex machine learning models is limited in the safety-critical domains, which incurs risk to life and property. To fully exploit the capabilities of complex neural networks, we propose a non-intrusive interpretability technique that uses the input and output of the model to generate a saliency map. The method works by empirically optimizing a randomly initialized input mask by localizing and weighing individual pixels according to their sensitivity towards the target class. Our experiments show that the proposed model interpretability approach performs better than the existing saliency map-based approaches methods at localizing the relevant input pixels. Furthermore, to obtain a global perspective on the target-specific explanation, we propose a saliency map reconstruction approach to generate acceptable variations of the salient inputs from the space of input data distribution for which the model outcome remains unaltered. Experiments show that our interpretability method can reconstruct the salient part of the input with a classification accuracy of 89%.
Deep Learning for System Trace Restoration
Apr 10, 2019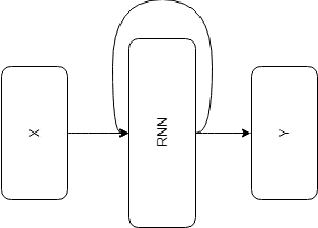
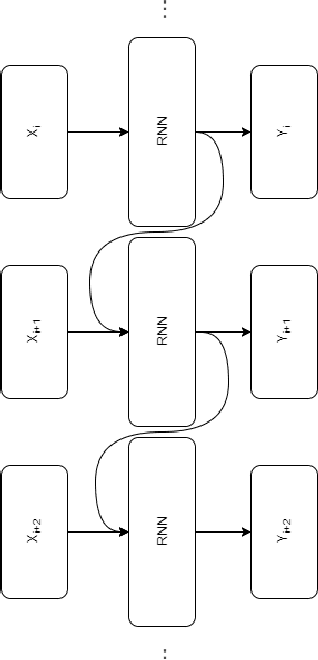
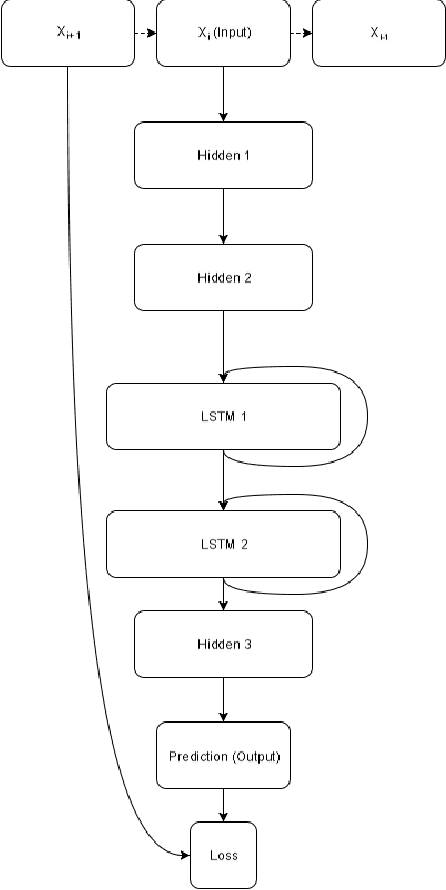
Most real-world datasets, and particularly those collected from physical systems, are full of noise, packet loss, and other imperfections. However, most specification mining, anomaly detection and other such algorithms assume, or even require, perfect data quality to function properly. Such algorithms may work in lab conditions when given clean, controlled data, but will fail in the field when given imperfect data. We propose a method for accurately reconstructing discrete temporal or sequential system traces affected by data loss, using Long Short-Term Memory Networks (LSTMs). The model works by learning to predict the next event in a sequence of events, and uses its own output as an input to continue predicting future events. As a result, this method can be used for data restoration even with streamed data. Such a method can reconstruct even long sequence of missing events, and can also help validate and improve data quality for noisy data. The output of the model will be a close reconstruction of the true data, and can be fed to algorithms that rely on clean data. We demonstrate our method by reconstructing automotive CAN traces consisting of long sequences of discrete events. We show that given even small parts of a CAN trace, our LSTM model can predict future events with an accuracy of almost 90%, and can successfully reconstruct large portions of the original trace, greatly outperforming a Markov Model benchmark. We separately feed the original, lossy, and reconstructed traces into a specification mining framework to perform downstream analysis of the effect of our method on state-of-the-art models that use these traces for understanding the behavior of complex systems.