 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generalizable saliency map-based interpretation of model outcome
Paper and Code
Jun 19, 2020

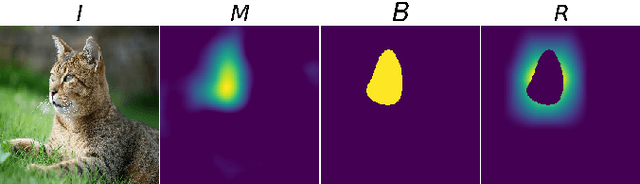
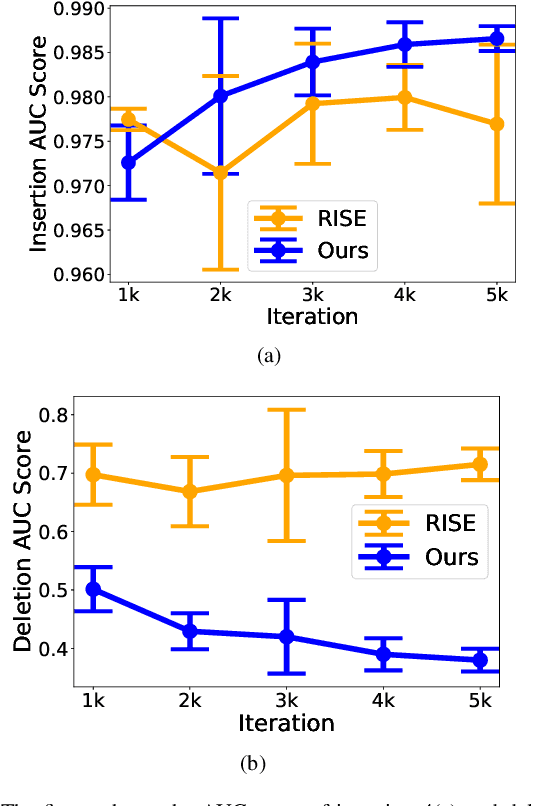
One of the significant challenges of deep neural networks is that the complex nature of the network prevents human comprehension of the outcome of the network. Consequently, the applicability of complex machine learning models is limited in the safety-critical domains, which incurs risk to life and property. To fully exploit the capabilities of complex neural networks, we propose a non-intrusive interpretability technique that uses the input and output of the model to generate a saliency map. The method works by empirically optimizing a randomly initialized input mask by localizing and weighing individual pixels according to their sensitivity towards the target class. Our experiments show that the proposed model interpretability approach performs better than the existing saliency map-based approaches methods at localizing the relevant input pixels. Furthermore, to obtain a global perspective on the target-specific explanation, we propose a saliency map reconstruction approach to generate acceptable variations of the salient inputs from the space of input data distribution for which the model outcome remains unaltered. Experiments show that our interpretability method can reconstruct the salient part of the input with a classification accuracy of 89%.